【机器学习】阿里云天池竞赛——工业蒸汽量预测(5)
机器学习经典赛题:工业蒸汽量预测(5)
- 机器学习经典赛题:工业蒸汽量预测(5):模型验证(赛题实战)
- 5.3 模型验证与调参实战
- 5.3.1 模型过拟合与欠拟合
- 5.3.2 模型正则化
- 5.3.3 模型交叉验证
- 5.3.4 模型超参空间及调参
- 5.3.5 学习曲线和验证曲线
- 参考资料
机器学习经典赛题:工业蒸汽量预测(5):模型验证(赛题实战)
5.3 模型验证与调参实战
5.3.1 模型过拟合与欠拟合
- 基础代码
导入工具包,用于模型验证和数据处理。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
import warnings
warnings.filterwarnings("ignore")
from sklearn.linear_model import LinearRegression #从sklearn引入线性模型
from sklearn.neighbors import KNeighborsRegressor #k近邻回归模型
from sklearn.tree import DecisionTreeRegressor #决策树回归模型
from sklearn.ensemble import RandomForestRegressor #随机森林回归模型
from sklearn.svm import SVR #支持向量机
from lightgbm import LGBMRegressor #LightGBM回归模型
from sklearn.model_selection import train_test_split #切分数据
from sklearn.metrics import mean_squared_error #评价指标
from sklearn.linear_model import SGDRegressor
读取数据:
#读取数据
train_data_file = '../data/zhengqi_train.txt'
test_data_file = '../data/zhengqi_test.txt'
train_data = pd.read_csv(train_data_file, sep='\t', encoding='utf-8')
test_data = pd.read_csv(test_data_file, sep='\t', encoding='utf-8')
对数据进行归一化处理:
from sklearn import preprocessing
#归一化处理
features_columns = [col for col in train_data.columns if col not in ['target']]
min_max_scaler = preprocessing.MinMaxScaler()
min_max_scaler = min_max_scaler.fit(train_data[features_columns])
train_data_scaler = min_max_scaler.transform(train_data[features_columns])
test_data_scaler = min_max_scaler.transform(test_data[features_columns])
train_data_scaler = pd.DataFrame(train_data_scaler)
train_data_scaler.columns = features_columns
test_data_scaler = pd.DataFrame(test_data_scaler)
test_data_scaler.columns = features_columns
train_data_scaler['target'] = train_data['target']
使用PCA进行特征降维:
#PCA方法降维
from sklearn.decomposition import PCA
# 保留16个主成分
pca = PCA(n_components=16)
new_train_pca_16 = pca.fit_transform(train_data_scaler.iloc[:, 0:-1])
new_test_pca_16 = pca.transform(test_data_scaler)
new_train_pca_16 = pd.DataFrame(new_train_pca_16)
new_test_pca_16 = pd.DataFrame(new_test_pca_16)
new_train_pca_16['target'] = train_data_scaler['target']
切分数据集,分为训练集和验证集:
#保留16维特征并切分数据
new_train_pca_16 = new_train_pca_16.fillna(0)
train = new_train_pca_16[new_train_pca_16.columns]
target = new_train_pca_16['target']
#划分数据集, 训练集80% : 验证机20%
train_data, test_data, train_target, test_target = train_test_split(train, target,test_size=0.2, random_state=0)
- 欠拟合
模型欠拟合的情况:
# 模型欠拟合的情况
clf = SGDRegressor(max_iter=500, tol=1e-2)
clf.fit(train_data, train_target)
score_train = mean_squared_error(train_target, clf.predict(train_data))
score_test = mean_squared_error(test_target, clf.predict(test_data))
print("SGDRegressor train MSE:", score_train)
print("SGDRegressor test MSE:", score_test)
输出结果:
SGDRegressor train MSE: 0.0009160671723394329
SGDRegressor test MSE: 0.000981634366517726
- 过拟合
模型过拟合的情况:
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(5)
train_data_poly = poly.fit_transform(train_data)
test_data_poly = poly.fit_transform(test_data)
clf = SGDRegressor(max_iter=1000, tol=1e-3)
clf.fit(train_data_poly, train_target)
score_train = mean_squared_error(train_target, clf.predict(train_data_poly))
score_test = mean_squared_error(test_target, clf.predict(test_data_poly))
print("SGDRegressor train MSE:", score_train)
print("SGDRegressor test MSE:", score_test)
输出结果:
SGDRegressor train MSE: 1.0898632608641039e+24
SGDRegressor test MSE: 1.6982104334110243e+24
- 正常拟合
模型正常拟合的情况:
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(3)
train_data_poly = poly.fit_transform(train_data)
test_data_poly = poly.fit_transform(test_data)
clf = SGDRegressor(max_iter=1000, tol=1e-3)
clf.fit(train_data_poly, train_target)
score_train = mean_squared_error(train_target, clf.predict(train_data_poly))
score_test = mean_squared_error(test_target, clf.predict(test_data_poly))
print("SGDRegressor train MSE:", score_train)
print("SGDRegressor test MSE:", score_test)
输出结果:
SGDRegressor train MSE: 0.001055038113307342
SGDRegressor test MSE: 0.001233821154013793
5.3.2 模型正则化
- L2范数正则化
采用L2范数正则化处理模型:
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(3)
train_data_poly = poly.fit_transform(train_data)
test_data_poly = poly.fit_transform(test_data)
clf = SGDRegressor(max_iter=1000, tol=1e-3, penalty='L2', alpha=0.0001)
clf.fit(train_data_poly, train_target)
score_train = mean_squared_error(train_target, clf.predict(train_data_poly))
score_test = mean_squared_error(test_target, clf.predict(test_data_poly))
print("SGDRegressor train MSE:", score_train)
print("SGDRegressor test MSE:", score_test)
输出结果:
SGDRegressor train MSE: 0.0010417279350570649
SGDRegressor test MSE: 0.0012885335267450496
- L1范数正则化
使用L1范数正则化处理模型
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(3)
train_data_poly = poly.fit_transform(train_data)
test_data_poly = poly.fit_transform(test_data)
clf = SGDRegressor(max_iter=1000, tol=1e-3, penalty='L1', alpha=0.0001)
clf.fit(train_data_poly, train_target)
score_train = mean_squared_error(train_target, clf.predict(train_data_poly))
score_test = mean_squared_error(test_target, clf.predict(test_data_poly))
print("SGDRegressor train MSE:", score_train)
print("SGDRegressor test MSE:", score_test)
- ElasticNet联合L1和L2范数加权正则化
使用ElasticNet正则化处理模型:
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(3)
train_data_poly = poly.fit_transform(train_data)
test_data_poly = poly.fit_transform(test_data)
clf = SGDRegressor(max_iter=1000, tol=1e-3, penalty='elasticnet', l1_ratio=0.9, alpha=.0001)
clf.fit(train_data_poly, train_target)
score_train = mean_squared_error(train_target, clf.predict(train_data_poly))
score_test = mean_squared_error(test_target, clf.predict(test_data_poly))
print("SGDRegressor train MSE:", score_train)
print("SGDRegressor test MSE:", score_test)
输出结果:
SGDRegressor train MSE: 0.0009336657359501396
SGDRegressor test MSE: 0.0011472413880708912
5.3.3 模型交叉验证
- 简单交叉验证
使用简单交叉验证方法对模型进行交叉验证并切分数据集,其中训练数据为80%,验证数据为20%。
#划分数据集, 训练集80% : 验证机20%
train_data, test_data, train_target, test_target = train_test_split(train, target,test_size=0.2, random_state=0)
clf = SGDRegressor(max_iter=1000, tol=1e-3)
clf.fit(train_data, train_target)
score_train = mean_squared_error(train_target, clf.predict(train_data))
score_test = mean_squared_error(test_target, clf.predict(test_data))
print("SGDRegressor train MSE:", score_train)
print("SGDRegressor test MSE:", score_test)
输出结果:
SGDRegressor train MSE: 0.0008805332436144762
SGDRegressor test MSE: 0.0009742019879530982
- K折交叉验证
使用K折交叉验证方法对模型进行交叉验证:
from sklearn.model_selection import KFold
kf = KFold(n_splits=5)
for k, (train_index, test_index) in enumerate(kf.split(train)):
train_data, test_data, train_target, test_target = train.values[train_index], train.values[test_index], target[
train_index], target[test_index]
clf = SGDRegressor(max_iter=1000, tol=1e-3)
clf.fit(train_data, train_target)
score_train = mean_squared_error(train_target, clf.predict(train_data))
score_test = mean_squared_error(test_target, clf.predict(test_data))
print(k, "折", "SGDRegressor train MSE:", score_train)
print(k, "折", "SGDRegressor test MSE:", score_test, "\n")
运行结果:
0 折 SGDRegressor train MSE: 0.0009220591043969376
0 折 SGDRegressor test MSE: 0.0005310778285509602
1 折 SGDRegressor train MSE: 0.0008800234249554588
1 折 SGDRegressor test MSE: 0.001259968578517734
2 折 SGDRegressor train MSE: 0.0008211966326584619
2 折 SGDRegressor test MSE: 0.0009107924815045727
3 折 SGDRegressor train MSE: 0.0009456226800574005
3 折 SGDRegressor test MSE: 0.0009853654948970164
4 折 SGDRegressor train MSE: 0.0009055864978733344
4 折 SGDRegressor test MSE: 0.0011048017616418345
- 留一法交叉验证
使用留一法交叉验证对模型进行交叉验证:
from sklearn.model_selection import LeaveOneOut
loo = LeaveOneOut()
num = 100
for k, (train_index, test_index) in enumerate(loo.split(train)):
train_data, test_data, train_target, test_target = train.values[train_index], train.values[test_index], target[
train_index], target[test_index]
clf = SGDRegressor(max_iter=1000, tol=1e-3)
clf.fit(train_data, train_target)
score_train = mean_squared_error(train_target, clf.predict(train_data))
score_test = mean_squared_error(test_target, clf.predict(test_data))
print(k, "个", "SGDRegressor train MSE:", score_train)
print(k, "个", "SGDRegressor test MSE:", score_test, "\n")
if k >= 9:
break
运行结果:
0 个 SGDRegressor train MSE: 0.0007447292899787238
0 个 SGDRegressor test MSE: 5.2599252754080336e-05
...
9 个 SGDRegressor train MSE: 0.0007887842650802939
9 个 SGDRegressor test MSE: 0.0005482147049830396
- 留P法交叉验证
使用留P法交叉验证对模型进行交叉验证:
from sklearn.model_selection import LeavePOut
lpo = LeavePOut(p=10)
num = 100
for k, (train_index, test_index) in enumerate(lpo.split(train)):
train_data, test_data, train_target, test_target = train.values[train_index], train.values[test_index], target[
train_index], target[test_index]
clf = SGDRegressor(max_iter=1000, tol=1e-3)
clf.fit(train_data, train_target)
score_train = mean_squared_error(train_target, clf.predict(train_data))
score_test = mean_squared_error(test_target, clf.predict(test_data))
print(k, "10个", "SGDRegressor train MSE:", score_train)
print(k, "10个", "SGDRegressor test MSE:", score_test, "\n")
if k >= 9:
break
运行结果:
0 10个 SGDRegressor train MSE: 0.0007482296929583594
0 10个 SGDRegressor test MSE: 0.00029421354601069736
...
9 10个 SGDRegressor train MSE: 0.0008062741989626481
9 10个 SGDRegressor test MSE: 0.00023679186419471267
5.3.4 模型超参空间及调参
- 穷举网格搜索
使用数据训练随机森林模型,采用网格搜索方法调参:
#使用数据训练随机森林模型,采用穷举网格搜索方法调参
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestRegressor
RandomForestRegressor = RandomForestRegressor()
parameters = {'n_estimators': [50, 100, 200], 'max_depth': [1, 2, 3]}
clf = GridSearchCV(RandomForestRegressor, parameters, cv=5)
clf.fit(train_data, train_target)
score_test = mean_squared_error(test_target, clf.predict(test_data))
print("RandomForestRegressor GridSearchCV test MSE:", score_test)
print(sorted(clf.cv_results_.keys())) #包含训练时间和验证指标的一些信息
运行结果:
RandomForestRegressor GridSearchCV test MSE: 0.012637546435789914
['mean_fit_time', 'mean_score_time', 'mean_test_score', 'param_max_depth', 'param_n_estimators', 'params', 'rank_test_score', 'split0_test_score', 'split1_test_score', 'split2_test_score', 'split3_test_score', 'split4_test_score', 'std_fit_time', 'std_score_time', 'std_test_score']
- 随机参数优化
使用数据训练随机森林模型,采用随机参数优化方法调参:
#使用数据训练随机森林模型,采用随即参数优化方法调参
from sklearn.model_selection import RandomizedSearchCV
from sklearn.ensemble import RandomForestRegressor
RandomForestRegressor = RandomForestRegressor()
parameters = {
'n_estimators': [50, 100, 200, 300],
'max_depth': [1, 2, 3, 4, 5]
}
clf = RandomizedSearchCV(RandomForestRegressor, parameters, cv=5)
clf.fit(train_data, train_target)
print('Best parameters found are:', clf.best_params_)
score_test = mean_squared_error(test_target, clf.predict(test_data))
print("RandomForestRegressor RandomizedSearchCV GridSearchCV test MSE:", score_test)
print(sorted(clf.cv_results_.keys())) #包含训练时间和验证指标的一些信息
运行结果:
Best parameters found are: {'n_estimators': 300, 'max_depth': 5}
RandomForestRegressor RandomizedSearchCV GridSearchCV test MSE: 8.52446793094484e-05
['mean_fit_time', 'mean_score_time', 'mean_test_score', 'param_max_depth', 'param_n_estimators', 'params', 'rank_test_score', 'split0_test_score', 'split1_test_score', 'split2_test_score', 'split3_test_score', 'split4_test_score', 'std_fit_time', 'std_score_time', 'std_test_score']
- LGB调参
使用数据训练LGB模型,采用网格搜索方法调参:
import lightgbm as lgb
clf = lgb.LGBMRegressor(num_leaves=31)
parameters = {'learning_rate': [0.01, 0.1, 1], 'n_estimators': [20, 40]}
clf.fit(train_data, train_target)
score_test = mean_squared_error(test_target, clf.predict(test_data))
print("LGBMRegressor GridSearchCV test MSE:", score_test)
# LGBMRegressor GridSearchCV test MSE: 1.560809562908417e-05
- LGB线下验证
下面给出对数据建模、5折交叉验证、划分数据、对LGB模型进行训练、计算MSE评价性能等流程的代码:
# 加载数据
train_data2 = pd.read_csv('../data/zhengqi_train.txt', sep='\t')
test_data2 = pd.read_csv('../data/zhengqi_test.txt', sep='\t')
train_data2_f = train_data2[test_data2.columns].values
train_data2_target = train_data2['target'].values
# lgb 模型
from sklearn.model_selection import KFold
import lightgbm as lgb
import numpy as np
# 5折交叉验证
Folds = 5
kf = KFold(n_splits=Folds, random_state=2022, shuffle=True)
# 记录训练和预测MSE
MSE_DICT = {
'train_mse': [],
'test_mse': []
}
# 线下训练预测
for i, (train_index, test_index) in enumerate(kf.split(train_data2_f)):
# lgb树模型
lgb_reg = lgb.LGBMRegressor(
learning_rate=0.01,
max_depth=-1,
n_estimators=5000,
boosting_type='gbdt',
random_state=2022,
objective='regression',
)
# 切分训练集和预测集
X_train_KFold, X_test_KFold = train_data2_f[train_index], train_data2_f[test_index]
y_train_KFold, y_test_KFold = train_data2_target[train_index], train_data2_target[test_index]
# 训练模型
# reg.fit(X_train_KFold, y_train_KFold)
lgb_reg.fit(
X=X_train_KFold, y=y_train_KFold,
eval_set=[(X_train_KFold, y_train_KFold), (X_test_KFold, y_test_KFold)],
eval_names=['Train', 'Test'],
early_stopping_rounds=100,
eval_metric='MSE',
verbose=50
)
# 训练集预测 测试集预测
y_train_KFold_predict = lgb_reg.predict(X_train_KFold, num_iteration=lgb_reg.best_iteration_)
y_test_KFold_predict = lgb_reg.predict(X_test_KFold, num_iteration=lgb_reg.best_iteration_)
print('第{}折 训练和预测 训练MSE 预测MSE'.format(i + 1))
train_mse = mean_squared_error(y_train_KFold_predict, y_train_KFold)
print('------\n', '训练MSE\n', train_mse, '\n------')
test_mse = mean_squared_error(y_test_KFold_predict, y_test_KFold)
print('------\n', '预测MSE\n', test_mse, '\n------\n')
MSE_DICT['train_mse'].append(train_mse)
MSE_DICT['test_mse'].append(test_mse)
print('------\n', '训练MSE\n', MSE_DICT['train_mse'], '\n', np.mean(MSE_DICT['train_mse']), '\n------')
print('------\n', '预测MSE\n', MSE_DICT['test_mse'], '\n', np.mean(MSE_DICT['test_mse']), '\n------')
5.3.5 学习曲线和验证曲线
- 学习曲线
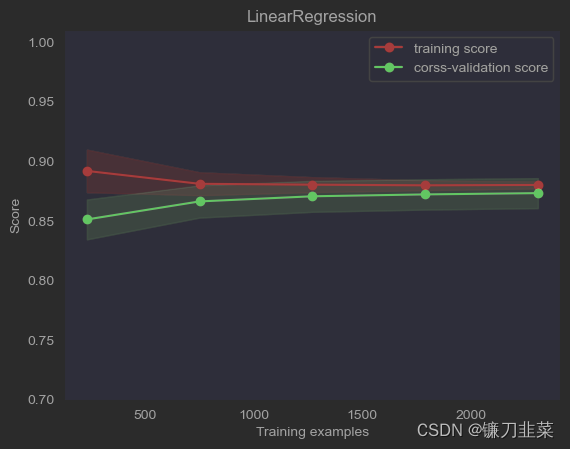
绘制数据的学习曲线,使用模型SGDRegressor
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import ShuffleSplit
from sklearn.linear_model import SGDRegressor
from sklearn.model_selection import learning_curve
train_data_file = "../data/zhengqi_train.txt"
test_data_file = "../data/zhengqi_test.txt"
train_data = pd.read_csv(train_data_file, sep='\t', encoding='utf-8')
test_data = pd.read_csv(test_data_file, sep='\t', encoding='utf-8')
plt.figure(figsize=(18, 10), dpi=150)
def plot_learning_curve(estimator, title, x, y, ylim=None, cv=None, n_jobs=1, train_sizes=np.linspace(.1, 1.0, 5)):
plt.figure()
plt.title(title)
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel("Training examples")
plt.ylabel("Score")
train_sizes, train_scores, test_scores = learning_curve(estimator, x, y, cv=cv, n_jobs=n_jobs,
train_sizes=train_sizes)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.grid()
plt.fill_between(train_sizes, train_scores_mean - train_scores_std, train_scores_mean + train_scores_std, alpha=0.1,
color='r')
plt.fill_between(train_sizes, test_scores_mean - test_scores_std, test_scores_mean + test_scores_std, alpha=0.1,
color='g')
plt.plot(train_sizes, train_scores_mean, 'o-', color='r', label="training score")
plt.plot(train_sizes, test_scores_mean, 'o-', color='g', label="corss-validation score")
plt.legend(loc="best")
return plt
x = train_data[test_data.columns].values
y = train_data['target'].values
title = "LinearRegression"
cv = ShuffleSplit(n_splits=100, test_size=0.2, random_state=0)
estimator = SGDRegressor()
plot_learning_curve(estimator, title, x, y, ylim=(0.7, 1.01), cv=cv, n_jobs=-1).show()
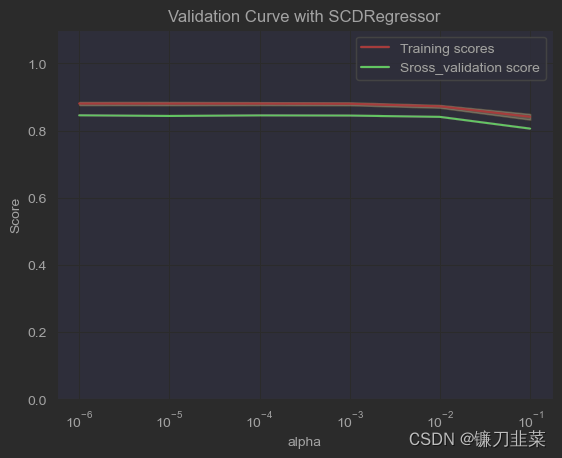
2. 验证曲线
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import SGDRegressor
from sklearn.model_selection import validation_curve
train_data_file = "../data/zhengqi_train.txt"
test_data_file = "../data/zhengqi_test.txt"
train_data = pd.read_csv(train_data_file, sep='\t', encoding='utf-8')
test_data = pd.read_csv(test_data_file, sep='\t', encoding='utf-8')
x = train_data[test_data.columns].values
y = train_data['target'].values
param_range = [0.1, 0.01, 0.001, 0.0001, 0.00001, 0.000001]
train_scores, test_scores = validation_curve(SGDRegressor(max_iter=1000, tol=1e-3, penalty='L1')
, x, y, param_name='alpha', param_range=param_range,
cv=10, scoring='r2', n_jobs=1)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.title("Validation Curve with SCDRegressor")
plt.xlabel("alpha")
plt.ylabel("Score")
plt.ylim(0.0, 1.1)
plt.semilogx(param_range, train_scores_mean, label="Training scores", color='r')
plt.fill_between(param_range, train_scores_mean - train_scores_std, train_scores_mean + train_scores_std, alpha=0.2,
color='r')
plt.semilogx(param_range, test_scores_mean, label="Sross_validation score", color='g')
plt.fill_between(param_range, train_scores_mean - train_scores_std, train_scores_mean + train_scores_std, alpha=0.2,
color='g')
plt.legend(loc="best")
plt.show()
参考资料
[1] 《阿里云天池大赛赛题解析——机器学习篇》