[论文精读|顶刊论文]Relational Triple Extraction: One Step is Enough
2022.5.11 |IJCAI-2022|华中科技大学|2022年SOTA
Relational Triple Extraction: One Step is Enough
过去的步骤:
- 寻找头尾实体的边界位置(实体识别)
- 将特定令牌串联成三元组(关系分类)
存在误差累计问题,每个实体边界识别误差会累积到最终的组合三元组中
论文中的方法:
先通过枚举句子中的令牌序列生成候选实体,然后将三元抽取任务转化为"头->尾"二部图上的连接问题。
基础准备
名词解析:
- 令牌序列:令牌是自然语言的基础。令牌化是一种将文本分成称为令牌的较小单元的方法。在这里,令牌可以是单词,字符或子单词。因此,标记化可以大致分为3种类型:单词,字符和子词(n-gram字符)标记化。
现有的联合抽取方法:
- 序列标注 :即给定一个输入序列,使用模型对这个序列的每一个位置标注一个相应的标签,是一个序列到序列的过程。(使用各种标记序列来确定实体的开始和结束位置,有时还包括关系)
2020用序列标记来识别句子中的所有实体,然后通过各种网络进行关系检测
2021用一个预测潜在关系的组件,约束到预测的关系子集,而不是所有关系
2022提出双向实体提取框架,考虑头尾和尾头的提取顺序、约束条件
- 表格填充 :为一个句子构造一个表,并用对应的正确的标记填充每个表单元格
2019通过关系加权图卷积网络来考虑实体和关系之间的作用
2020三元组抽取转化为令牌对链接问题,引入特定于关系的握手标记方案对其实体对的边界令牌
2021利用一个分区过滤网络,该网络生成任务特殊特征,用于建模实体识别和关系分类之间的交互
- 文本生成:将三元组作为令牌序列,病采用编码器-解码器结构来生成像机器翻译一样的三元组元素
2018用复制机制生成两个对应实体所遵循的关系,但只能预测实体的最后一个单词
2020使用多任务学习框架解决多令牌实体问题
2021一种带有生成变压器的对比三元组提取方法解决长期依赖问题
2021设计一个二进制指针网络来提取显式三元组和隐式三元组
文中的方法:

暴力方法:
穷举一个句子的令牌序列,结果是肯定会包含正确的实体
因此:看是否存在关系,可以直接识别三元
通过枚举令牌序列生成候选实体
为每个关系设计一个链接矩阵来检测两个候选实体是否可能构成有效的三元组
三元组的提取转化为一个关系特定的二部图链接问题
方法详解
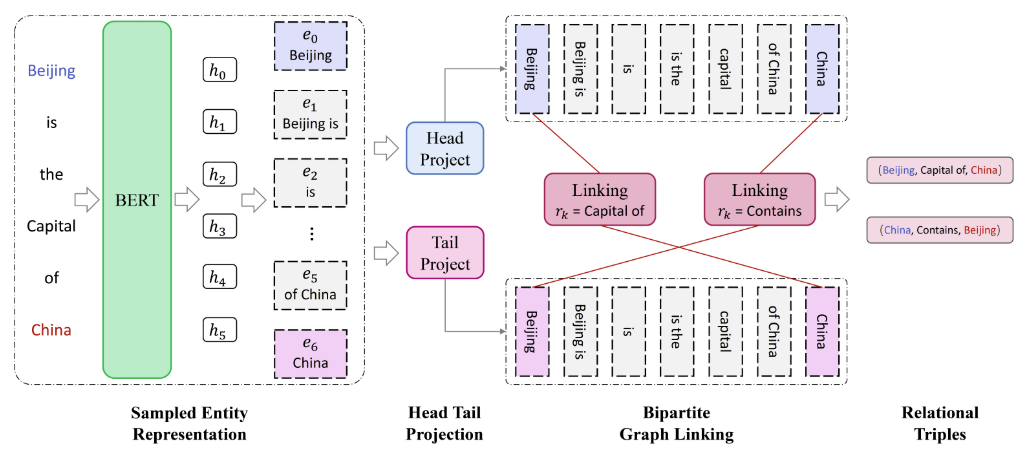
实体:
S
=
{
w
1
,
w
2
,
.
.
.
,
w
L
}
S =\lbrace {w_1, w_2, ..., w_L} \rbrace
S={w1,w2,...,wL}
三元组:
T
=
{
(
h
,
r
,
t
)
∣
h
,
t
∈
ξ
,
r
i
∈
R
}
T =\lbrace {(h, r, t)|h, t ∈ \xi, r_i ∈ R}\rbrace
T={(h,r,t)∣h,t∈ξ,ri∈R},
ξ
\xi
ξ为头部和尾部实体
k个预设的关系:
R
=
{
r
1
,
r
2
,
.
.
.
,
r
K
}
R = \lbrace{r_1, r_2, ..., r_K}\rbrace
R={r1,r2,...,rK}
1. 候选实体生成
例子:
枚举句子中所有长度小于C(C<L)的连续令牌作为候选实体,若C=2
“Beijing is the capital of China“
E = { “Beijing”, “Beijing is”, “is”, “is the”, “the”, “the Capital”, “Capital”, “Capital of”, “of”, “of China”, “China”}.
∣ ξ ∣ = L × C + C 2 − C 2 2 (1) | \xi| = L \times C +\frac{C}{2} - \frac{C^2}{2} \tag{1} ∣ξ∣=L×C+2C−2C2(1)
缺点:
- 负三元组占主导地位,训练偏向负三元组,会降低识别正三元组的能力
- 训练句子多,所以训练效率低
解决:
从 ξ \xi ξ随机提取 n n e g n_{neg} nneg否定实体,与所有基本真值实体一起训练模型,新的子集表示为 ξ ‾ \overline\xi ξ
2. 二部图链接
目的:句子、 ξ ‾ \overline\xi ξ、作为句子的编码器的BERT -> 每个令牌的D维上下文表示 h i h_i hi
[
h
1
,
h
2
,
.
.
.
,
h
L
]
=
B
E
R
T
(
[
x
1
,
x
2
,
.
.
.
,
x
L
]
)
(2)
[h_1,h_2,...,h_L] = BERT([x_1,x_2,...,x_L]) \tag{2}
[h1,h2,...,hL]=BERT([x1,x2,...,xL])(2)
其中的
x
i
x_i
xi是第i的令牌的输入表示,是令牌嵌入和位置嵌入的总和
e
i
=
h
s
t
a
r
t
+
h
e
n
d
2
(3)
e_i = \frac{h^{start} + h ^ {end}}{2} \tag{3}
ei=2hstart+hend(3)
取实体
e
i
∈
ξ
‾
e_i\in\overline\xi
ei∈ξ,即开始令牌和结束令牌之间的平均向量
为实体通常由多个令牌组成,为了便于并行计算,需要保持不同实体表示的维度一致

使用一个有向的“头->尾“二部图提取三元组,将投影实体表示为
E
h
e
a
d
=
W
h
T
E
+
b
h
E_{head}= W_h^TE + b_h
Ehead=WhTE+bh、
E
t
a
i
l
=
W
t
T
E
+
b
t
E_{tail}=W_t^TE+b_t
Etail=WtTE+bt
E E E是由(3)式计算得出
W h , W t W_h,W_t Wh,Wt是两个project matrices, 从令牌的特征空间 到 D维的头部实体空间到尾部实体空间,都允许模型识别每个实体的头部或尾部角色
b ( ⋅ ) b_{(·)} b(⋅)是偏差
对于每个关系
r
k
r_k
rk,可以通过预测之间的链接来判断是否是一个有效的实体对儿
P
k
=
σ
(
E
h
e
a
d
T
U
k
E
t
a
i
l
)
(4)
P^k = \sigma(E_{head}^{T}U_kE_{tail}) \tag{4}
Pk=σ(EheadTUkEtail)(4)
σ \sigma σ是sigma激活函数
U k d e × d e U_k^{d_e \times d_e} Ukde×de是链接矩阵,根据第k个关系的两个实体之间的相关性生成的
如果概率超过某个阈值 θ \theta θ,则 ( e i , r k , e j ) (e_i, r_k, e_j) (ei,rk,ej)判定为是正确的
而且实体的跨度在预处理就确定了,解码更容易
即,对于每个关系 r k r_k rk,如果 p i j k > θ p_{ij}^k > \theta pijk>θ,则预测的三元组是 ( e i ⋅ s p a n , r k , e j ⋅ s p a n ) (e_i\cdot span,r_k,e_j \cdot span) (ei⋅span,rk,ej⋅span)
Directrel的目标函数定义为
L
=
−
1
∣
ξ
‾
∣
×
K
×
∣
ξ
‾
∣
×
=
∑
i
=
1
∣
ξ
‾
∣
∑
k
=
1
K
∑
j
=
1
∣
ξ
‾
∣
(
y
t
log
(
P
i
j
k
)
+
(
1
−
y
t
)
log
(
1
−
P
i
j
k
)
)
(4)
\begin{aligned} \mathcal{L} &= - \frac{1}{|\overline\xi| \times K \times |\overline\xi|}\times \\ &=\sum_{i=1}^{|\overline\xi|} \sum_{k=1}^K \sum_{j=1}^{|\overline\xi|}(y^t\log(P_{ij}^k) + (1-y_t)\log(1-P_{ij}^k)) \tag{4} \end{aligned}
L=−∣ξ∣×K×∣ξ∣1×=i=1∑∣ξ∣k=1∑Kj=1∑∣ξ∣(ytlog(Pijk)+(1−yt)log(1−Pijk))(4)
实验

使用了NYT与WebNLG数据集进行实验
NYT:将FreeBase中的相关事件与纽约时报语料库对其,包含56k个训练句子和5k个测试句子
WebNLG:最初为自然语言生成开发,从给定的三元组生成相应的描述,包含5k个训练句子和703个测试句子
NYT*表示只注释实体的最后一个词的版本,NYT注释了整个实体,webNLG同理
采用Precision(Prec.),Recall(Rec.),F1-score(F1)评价性能,只有当头部h,尾部t和关系r是与事实完全一致时视为正确的
P r e c i s i o n = T P T P + F P Precision = \frac{TP}{TP+FP} Precision=TP+FPTP 预测为正确的数据中,真实值为正确的比例。抽取出的三元组准确与否
R e c a l l = T P T P + F N Recall = \frac{TP}{TP+FN} Recall=TP+FNTP 在所有的真实值为正确的数据中,有多少能预测正确。抽取出的正确三元组是否全面
F 1 = 2 × P r e c i s i o n × R e c a l l P r e c i s i o n + R e c a l l F1 = \frac {2 \times Precision \times Recall} {Precision + Recall} F1=Precision+Recall2×Precision×RecallF1 得分反映了模型抽取三元组的综合能力
| 样本本身 | 预测模型 | |
|---|---|---|
| TP | 正 | 正 |
| FP | 负 | 正 |
| FN | 正 | 负 |
主要结果:
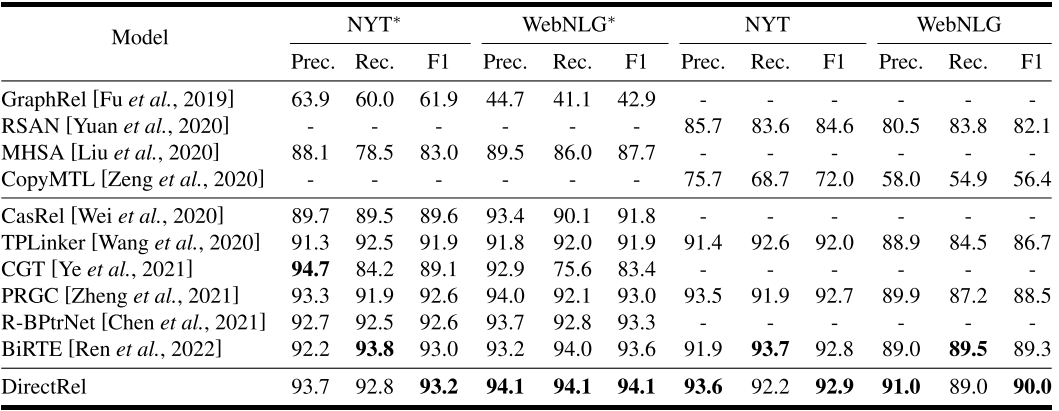
F1得分优于所有其他模型
详细结果:
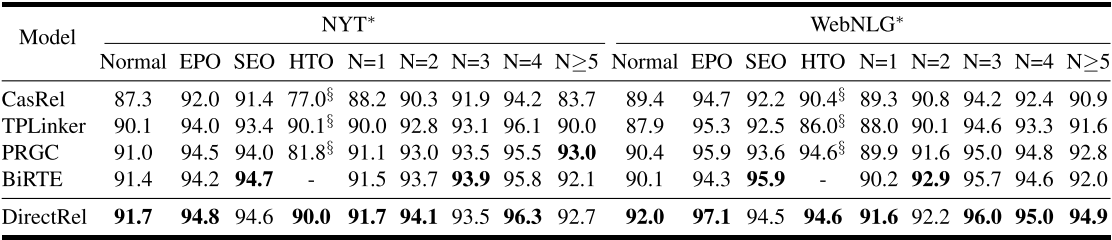
通过重叠模式和三元数拆分了NYT和WebNLG的测试集
第一,它有效地缓解了误差积累问题,保证了提取三元组的精度。
其次,在每个实体对之间采用特定于关系的链接,保证了三重抽取的召回性。

在两个子任务上的性能试验对比,选择了PRGC(最先进的三元模型之一,在关系判断和头尾对齐方面很强)
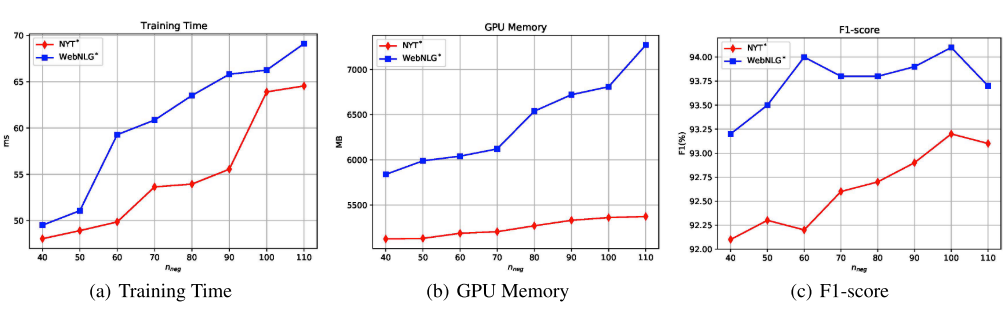
不同
n
n
e
g
n_{neg}
nneg对NYT和WebNLG的影响。
训练时间(ms)是指训练一个小批处理所需的平均时间
GPU内存(MB)是训练一个Epoch所需的平均GPU内存

在WebNLG上的不足之处:跨度分裂错误、未找到实体和实体角色错误。
“跨度分裂误差”所占比例相对较小,证明了在一个有向的“头→尾”二分图上通过链接预测直接提取三元组的有效性。
“实体角色错误”最具挑战性。 其主要原因是在三重提取过程中忽略了实体的上下文信息。
感悟
作者使用了另一角度去解决三元组抽取的难题,从过去的分步抽取到该方法的直接关注抽象出来的方法,从而无需确定实体的开始和结束的位置。
使用
n
n
e
g
n_neg
nneg解决了样本中错误样本会影响识别的问题,使用二部图法直接抽取关系