八股文之设计原则
单依职责原则
第1章 单一职责原则
单一职责原则要求一个接口或类只有一个原因引起变化,也就是一个接口或类只有一个职责,它就负责一件事情
1.1 我是“牛”类,我可以担任多职吗
单一职责原则的英文名称是Single Responsibility Principle,简称是SRP。这个设计原则备受争议,只要你想和别人争执、怄气或者是吵架,这个原则是屡试不爽的。如果你是老大,看到一个接口或类是这样或那样设计的,你就问一句:“你设计的类符合SRP原则吗?”保准对方立马“萎缩”掉,而且还一脸崇拜地看着你,心想:“老大确实英明”。这个原则存在争议之处在哪里呢?就是对职责的定义,什么是类的职责,以及怎么划分类的职责。我们先举个例子来说明什么是单一职责原则。
只要做过项目,肯定要接触到用户、机构、角色管理这些模块,基本上使用的都是RBAC模型(Role-Based Access Control,基于角色的访问控制,通过分配和取消角色来完成用户权限的授予和取消,使动作主体(用户)与资源的行为(权限)分离),确实是一个很好的解决办法。我们这里要讲的是用户管理、修改用户的信息、增加机构(一个人属于多个机构)、增加角色等,用户有这么多的信息和行为要维护,我们就把这些写到一个接口中,都是用户管理类嘛,我们先来看它的类图,如图1-1所示。
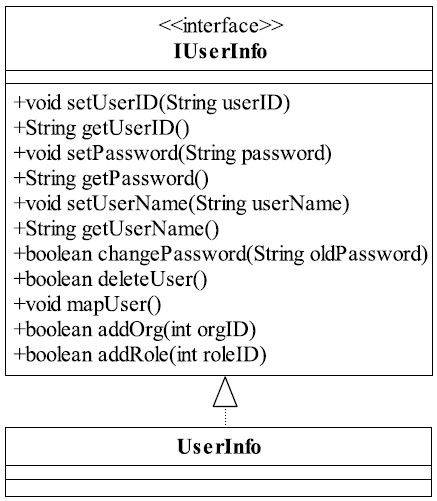
图1-1 用户信息维护类图
太Easy的类图了,我相信,即使是一个初级的程序员也可以看出这个接口设计得有问题,用户的属性和用户的行为没有分开,这是一个严重的错误!这个接口确实设计得一团糟,应该把用户的信息抽取成一个BO(Business Object,业务对象),把行为抽取成一个Biz(Business Logic,业务逻辑),按照这个思路对类图进行修正,如图1-2所示。
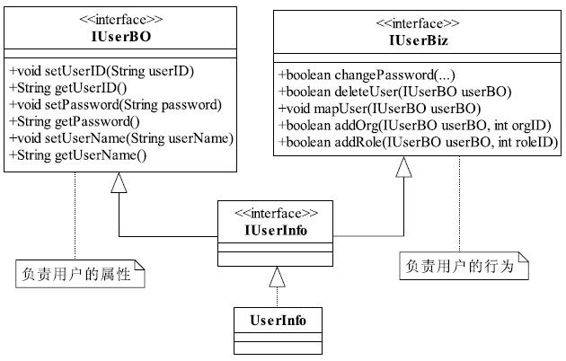
图1-2 职责划分后的类图
重新拆封成两个接口,IUserBO负责用户的属性,简单地说,IUserBO的职责就是收集和反馈用户的属性信息;IUserBiz负责用户的行为,完成用户信息的维护和变更。各位可能要说了,这个与我实际工作中用到的User类还是有差别的呀!别着急,我们先来看一看分拆成两个接口怎么使用。OK,我们现在是面向接口编程,所以产生了这个UserInfo对象之后,当然可以把它当IUserBO接口使用。也可以当IUserBiz接口使用,这要看你在什么地方使用了。要获得用户信息,就当是IUserBO的实现类;要是希望维护用户的信息,就把它当作IUserBiz的实现类就成了,如代码清单1-1所示。
代码清单1-1 分清职责后的代码示例
......
IUserInfo userInfo = new UserInfo();
//我要赋值了,我就认为它是一个纯粹的BO
IUserBO userBO = (IUserBO)userInfo;
userBO.setPassword("abc");
//我要执行动作了,我就认为是一个业务逻辑类
IUserBiz userBiz = (IUserBiz)userInfo;
userBiz.deleteUser();
......
确实可以如此,问题也解决了,但是我们来分析一下刚才的动作,为什么要把一个接口拆分成两个呢?其实,在实际的使用中,我们更倾向于使用两个不同的类或接口:一个是IUserBO,一个是IUserBiz,类图如图1-3所示。
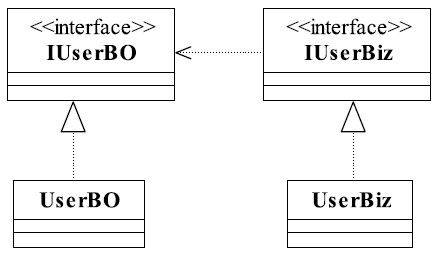
图1-3 项目中经常采用的SRP类图
以上我们把一个接口拆分成两个接口的动作,就是依赖了单一职责原则,那什么是单一职责原则呢?单一职责原则的定义是:应该有且仅有一个原因引起类的变更。
1.2 绝杀技,打破你的传统思维
解释到这里,估计你已经很不屑了,“切!这么简单的东西还要讲?!”好,我们来讲点复杂的。SRP的原话解释是:
There should never be more than one reason for a class to change.
这句话初中生都能看懂,不多说,但是看懂是一码事,实施就是另外一码事了。上面讲的例子很好理解,在实际项目中大家都已经这么做了,那我们再来看看下面这个例子是否好理解。电话这玩意,是现代人都离不了,电话通话的时候有4个过程发生:拨号、通话、回应、挂机,那我们写一个接口,其类图如图1-4所示。
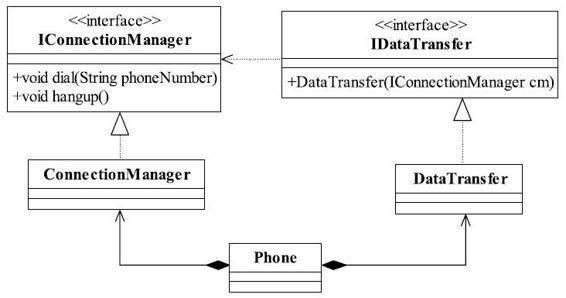
图1-4 电话类图
我不是有意要冒犯IPhone的,同名纯属巧合,我们来看一个这个过程的代码,如代码清单1-2所示。
代码清单1-2 电话过程
public interface IPhone {
//拨通电话
public void dial(String phoneNumber);
//通话
public void chat(Object o);
//通话完毕,挂电话
public void hangup();
}
实现类也比较简单,我就不再写了,大家看看这个接口有没有问题?我相信大部分的读者都会说这个没有问题呀,以前我就是这么做的呀,某某书上也是这么写的呀,还有什么什么的源码也是这么写的!是的,这个接口接近于完美,看清楚了,是“接近”!单一职责原则要求一个接口或类只有一个原因引起变化,也就是一个接口或类只有一个职责,它就负责一件事情,看看上面的接口只负责一件事情吗?是只有一个原因引起变化吗?好像不是!
IPhone这个接口可不是只有一个职责,它包含了两个职责:一个是协议管理,一个是数据传送。dial()和hangup()两个方法实现的是协议管理,分别负责拨号接通和挂机;chat()实现的是数据的传送,把我们说的话转换成模拟信号或数字信号传递到对方,然后再把对方传递过来的信号还原成我们听得懂的语言。我们可以这样考虑这个问题,协议接通的变化会引起这个接口或实现类的变化吗?会的!那数据传送(想想看,电话不仅仅可以通话,还可以上网)的变化会引起这个接口或实现类的变化吗?会的!那就很简单了,这里有两个原因都引起了类的变化。这两个职责会相互影响吗?电话拨号,我只要能接通就成,甭管是电信的还是网通的协议;电话连接后还关心传递的是什么数据吗?通过这样的分析,我们发现类图上的IPhone接口包含了两个职责,而且这两个职责的变化不相互影响,那就考虑拆分成两个接口,其类图如图1-5所示。
图1-5 职责分明的电话类图
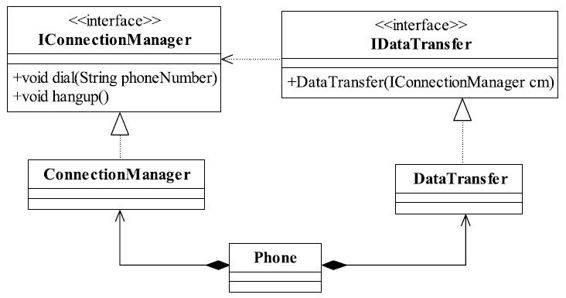
图1-6 简洁清晰、职责分明的电话类图
这个类图看上去有点复杂了,完全满足了单一职责原则的要求,每个接口职责分明,结构清晰,但是我相信你在设计的时候肯定不会采用这种方式,一个手机类要把ConnectionManager和DataTransfer组合在一块才能使用。组合是一种强耦合关系,你和我都有共同的生命期,这样的强耦合关系还不如使用接口实现的方式呢,而且还增加了类的复杂性,多了两个类。经过这样的思考后,我们再修改一下类图,如图1-6所示。
这样的设计才是完美的,一个类实现了两个接口,把两个职责融合在一个类中。你会觉得这个Phone有两个原因引起变化了呀,是的,但是别忘记了我们是面向接口编程,我们对外公布的是接口而不是实现类。而且,如果真要实现类的单一职责,这个就必须使用上面的组合模式了,这会引起类间耦合过重、类的数量增加等问题,人为地增加了设计的复杂性。
通过上面的例子,我们来总结一下单一职责原则有什么好处:
● 类的复杂性降低,实现什么职责都有清晰明确的定义;
● 可读性提高,复杂性降低,那当然可读性提高了;
● 可维护性提高,可读性提高,那当然更容易维护了;
● 变更引起的风险降低,变更是必不可少的,如果接口的单一职责做得好,一个接口修改只对相应的实现类有影响,对其他的接口无影响,这对系统的扩展性、维护性都有非常大的帮助。
看过电话这个例子后,是不是想反思一下了,我以前的设计是不是有点问题了?不,不是的,不要怀疑自己的技术能力,单一职责原则最难划分的就是职责。一个职责一个接口,但问题是“职责”没有一个量化的标准,一个类到底要负责那些职责?这些职责该怎么细化?细化后是否都要有一个接口或类?这些都需要从实际的项目去考虑,从功能上来说,定义一个IPhone接口也没有错,实现了电话的功能,而且设计还很简单,仅仅一个接口一个实现类,实际的项目我想大家都会这么设计。项目要考虑可变因素和不可变因素,以及相关的收益成本比率,因此设计一个IPhone接口也可能是没有错的。但是,如果纯从“学究”理论上分析就有问题了,有两个可以变化的原因放到了一个接口中,这就为以后的变化带来了风险。如果以后模拟电话升级到数字电话,我们提供的接口IPhone是不是要修改了?接口修改对其他的Invoker类是不是有很大影响?
注意 单一职责原则提出了一个编写程序的标准,用“职责”或“变化原因”来衡量接口或类设计得是否优良,但是“职责”和“变化原因”都是不可度量的,因项目而异,因环境而异。
1.3 我单纯,所以我快乐
对于接口,我们在设计的时候一定要做到单一,但是对于实现类就需要多方面考虑了。生搬硬套单一职责原则会引起类的剧增,给维护带来非常多的麻烦,而且过分细分类的职责也会人为地增加系统的复杂性。本来一个类可以实现的行为硬要拆成两个类,然后再使用聚合或组合的方式耦合在一起,人为制造了系统的复杂性。所以原则是死的,人是活的,这句话很有道理。
单一职责原则很难在项目中得到体现,非常难,为什么?在国内,技术人员的地位和话语权都比较低,因此在项目中需要考虑环境,考虑工作量,考虑人员的技术水平,考虑硬件的资源情况,等等,最终妥协的结果是经常违背单一职责原则。而且,我们中华文明就有很多属于混合型的产物,比如筷子,我们可以把筷子当做刀来使用,分割食物;还可以当叉使用,把食物从盘子中移动到口中。而在西方的文化中,刀就是刀,叉就是叉,你去吃西餐的时候这两样肯定都是有的,刀就是切割食物,叉就是固定食物或者移动食物,分工很明晰。这种文化的差异很难一步改造过来,但是我相信随着技术的深入,单一职责原则必然会深入到项目的设计中,而且这个原则是那么的简单,简单得不需要我们更加深入地思考,单从字面上大家都应该知道是什么意思,单一职责嘛!
单一职责适用于接口、类,同时也适用于方法,什么意思呢?一个方法尽可能做一件事情,比如一个方法修改用户密码,不要把这个方法放到“修改用户信息”方法中,这个方法的颗粒度很粗,比如图1-7中所示的方法。

图1-7 一个方法承担多个职责
在IUserManager中定义了一个方法changeUser,根据传递的类型不同,把可变长度参数changeOptions修改到userBO这个对象上,并调用持久层的方法保存到数据库中。在我的项目组中,如果有人写了这样一个方法,我不管他写了多少程序,花了多少工夫,一律重写!原因很简单:方法职责不清晰,不单一,不要让别人猜测这个方法可能是用来处理什么逻辑的。比较好的设计如图1-8所示。
通过类图可知,如果要修改用户名称,就调用changeUserName方法;要修改家庭地址,就调用changeHomeAddress方法;要修改单位电话,就调用changeOfficeTel方法。每个方法的职责非常清晰明确,不仅开发简单,而且日后的维护也非常容易,大家可以逐渐养成这样的习惯。
图1-8 一个方法承担一个职责
所以,如果对接口、类、方法使用了单一职责原则,那么快乐的就不仅仅是你了,还有你的项目组成员,大家可以轻松而又愉快地进行开发;还有你的老板,减少了因为变更引起的工作量,减少了无谓的人员和资金消耗。当然,最快乐的也许就是你了,因为加官晋爵可能等着你哟!
总结
单一职责适用于接口、类,同时也适用于方法,什么意思呢?一个方法尽可能做一件事情,比如一个方法修改用户密码,不要把这个方法放到“修改用户信息”方法中,这个方法的颗粒度很粗
对于单一职责原则,我的建议是接口一定要做到单一职责,类的设计尽量做到只有一个原因引起变化。
是的,类的单一职责确实受非常多因素的制约,纯理论地来讲,这个原则是非常优秀的,但是现实有现实的难处,你必须去考虑项目工期、成本、人员技术水平、硬件情况、网络情况甚至有时候还要考虑政府政策、垄断协议等因素。比如,2004年我就做过一个项目,做加密处理的,甲方就甩过来一句话,你什么都不用管,调用这个API就可以了,不用考虑什么传输协议、异常处理、安全连接等。
里氏替换原则
第2章 里氏替换原则
2.1 爱恨纠葛的父子关系
在面向对象的语言中,继承是必不可少的、非常优秀的语言机制,它有如下优点:
● 代码共享,减少创建类的工作量,每个子类都拥有父类的方法和属性;
● 提高代码的重用性;
● 子类可以形似父类,但又异于父类,“龙生龙,凤生凤,老鼠生来会打洞”是说子拥有父的“种”,“世界上没有两片完全相同的叶子”是指明子与父的不同;
● 提高代码的可扩展性,实现父类的方法就可以“为所欲为”了,君不见很多开源框架的扩展接口都是通过继承父类来完成的;
● 提高产品或项目的开放性。
自然界的所有事物都是优点和缺点并存的,即使是鸡蛋,有时候也能挑出骨头来,继承的缺点如下:
● 继承是侵入性的。只要继承,就必须拥有父类的所有属性和方法;
● 降低代码的灵活性。子类必须拥有父类的属性和方法,让子类自由的世界中多了些约束;
● 增强了耦合性。当父类的常量、变量和方法被修改时,需要考虑子类的修改,而且在缺乏规范的环境下,这种修改可能带来非常糟糕的结果——大段的代码需要重构。
Java使用extends关键字来实现继承,它采用了单一继承的规则,C++则采用了多重继承的规则,一个子类可以继承多个父类。从整体上来看,利大于弊,怎么才能让“利”的因素发挥最大的作用,同时减少“弊”带来的麻烦呢?解决方案是引入里氏替换原则(Liskov Substitution Principle,LSP),什么是里氏替换原则呢?它有两种定义:
● 第一种定义,也是最正宗的定义:If for each object o1 of type S there is an object o2 of type T such that for all programs P defined in terms of T,the behavior of P is unchanged when o1 is substituted for o2 then S is a subtype of T.(如果对每一个类型为S的对象o1,都有类型为T的对象o2,使得以T定义的所有程序P在所有的对象o1都代换成o2时,程序P的行为没有发生变化,那么类型S是类型T的子类型。)
● 第二种定义:Functions that use pointers or references to base classes must be able to use objects of derived classes without knowing it.(所有引用基类的地方必须能透明地使用其子类的对象。)
第二个定义是最清晰明确的,通俗点讲,只要父类能出现的地方子类就可以出现,而且替换为子类也不会产生任何错误或异常,使用者可能根本就不需要知道是父类还是子类。但是,反过来就不行了,有子类出现的地方,父类未必就能适应。
2.2 纠纷不断,规则压制
里氏替换原则为良好的继承定义了一个规范,一句简单的定义包含了4层含义。
1.子类必须完全实现父类的方法
我们在做系统设计时,经常会定义一个接口或抽象类,然后编码实现,调用类则直接传入接口或抽象类,其实这里已经使用了里氏替换原则。我们举个例子来说明这个原则,大家都打过CS吧,非常经典的FPS类游戏,我们来描述一下里面用到的枪,类图如图2-1所示。
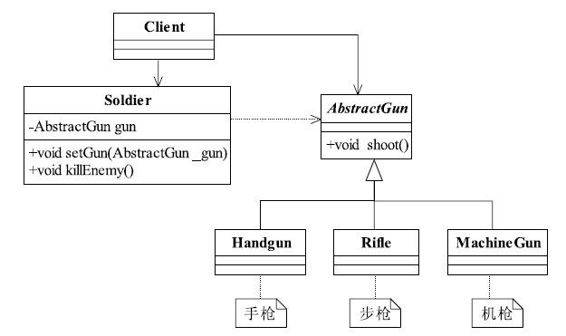
图2-1 CS游戏中的枪支类图
枪的主要职责是射击,如何射击在各个具体的子类中定义,手枪是单发射程比较近,步枪威力大射程远,机枪用于扫射。在士兵类中定义了一个方法killEnemy,使用枪来杀敌人,具体使用什么枪来杀敌人,调用的时候才知道,AbstractGun类的源程序如代码清单2-1所示。
代码清单2-1 枪支的抽象类
public abstract class AbstractGun {
//枪用来干什么的?杀敌!
public abstract void shoot();
}
手枪、步枪、机枪的实现类如代码清单2-2所示。
代码清单2-2 手枪、步枪、机枪的实现类
public class Handgun extends AbstractGun {
//手枪的特点是携带方便,射程短
@Override
public void shoot() {
System.out.println("手枪射击...");
}
}
public class Rifle extends AbstractGun{
//步枪的特点是射程远,威力大
public void shoot(){
System.out.println("步枪射击...");
}
}
public class MachineGun extends AbstractGun{
public void shoot(){
System.out.println("机枪扫射...");
}
}
有了枪支,还要有能够使用这些枪支的士兵,其源程序如代码清单2-3所示。
代码清单2-3 士兵的实现类
public class Soldier {
//定义士兵的枪支
private AbstractGun gun;
//给士兵一支枪
public void setGun(AbstractGun _gun){
this.gun = _gun;
}
public void killEnemy(){
System.out.println("士兵开始杀敌人...");
gun.shoot();
}
}
注意粗体部分,定义士兵使用枪来杀敌,但是这把枪是抽象的,具体是手枪还是步枪需要在上战场前(也就是场景中)前通过setGun方法确定。场景类Client的源代码如代码清单2-4所示。
代码清单2-4 场景类
public class Client {
public static void main(String[] args) {
//产生三毛这个士兵
Soldier sanMao = new Soldier();
//给三毛一支枪
sanMao.setGun(new Rifle());
sanMao.killEnemy();
}
}
有人,有枪,也有场景,运行结果如下所示。
士兵开始杀敌人…
步枪射击…
在这个程序中,我们给三毛这个士兵一把步枪,然后就开始杀敌了。如果三毛要使用机枪,当然也可以,直接把sanMao.setGun(new Rifle())修改为sanMao.setGun(new MachineGun())即可,在编写程序时Solider士兵类根本就不用知道是哪个型号的枪(子类)被传入。
注意 在类中调用其他类时务必要使用父类或接口,如果不能使用父类或接口,则说明类的设计已经违背了LSP原则。
我们再来想一想,如果我们有一个玩具手枪,该如何定义呢?我们先在类图2-1上增加一个类ToyGun,然后继承于AbstractGun类,修改后的类图如图2-2所示。
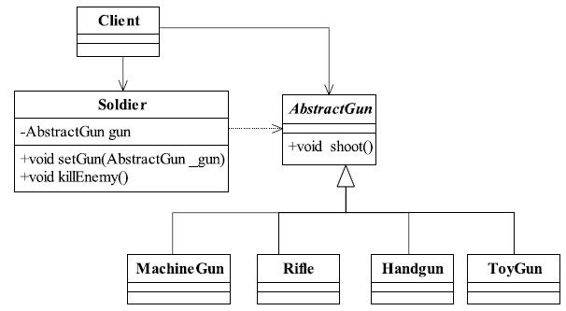
图2-2 枪支类图
首先我们想,玩具枪是不能用来射击的,杀不死人的,这个不应该写在shoot方法中。新增加的ToyGun的源代码如代码清单2-5所示。
代码清单2-5 玩具枪源代码
public class ToyGun extends AbstractGun {
//玩具枪是不能射击的,但是编译器又要求实现这个方法,怎么办?虚构一个呗!
@Override
public void shoot() {
//玩具枪不能射击,这个方法就不实现了
}
}
由于引入了新的子类,场景类中也使用了该类,Client稍作修改,源代码如代码清单2-6所示。
代码清单2-6 场景类
public class Client {
public static void main(String[] args) {
//产生三毛这个士兵
Soldier sanMao = new Soldier();
sanMao.setGun(new ToyGun());
sanMao.killEnemy();
}
}
修改了粗体部分,把玩具枪传递给三毛用来杀敌,代码运行结果如下所示:
士兵开始杀敌人…
坏了,士兵拿着玩具枪来杀敌人,射不出子弹呀!如果在CS游戏中有这种事情发生,那你就等着被人爆头吧,然后看着自己凄惨地倒地。在这种情况下,我们发现业务调用类已经出现了问题,正常的业务逻辑已经不能运行,那怎么办?好办,有两种解决办法:
● 在Soldier类中增加instanceof的判断,如果是玩具枪,就不用来杀敌人。这个方法可以解决问题,但是你要知道,在程序中,每增加一个类,所有与这个父类有关系的类都必须修改,你觉得可行吗?如果你的产品出现了这个问题,因为修正了这样一个Bug,就要求所有与这个父类有关系的类都增加一个判断,客户非跳起来跟你干架不可!你还想要客户忠诚于你吗?显然,这个方案被否定了。
● ToyGun脱离继承,建立一个独立的父类,为了实现代码复用,可以与AbastractGun建立关联委托关系,如图2-3所示。
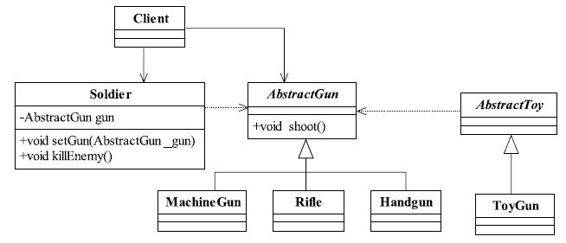
图2-3 玩具枪与真实枪分离的类图
例如,可以在AbstractToy中声明将声音、形状都委托给AbstractGun处理,仿真枪嘛,形状和声音都要和真实的枪一样了,然后两个基类下的子类自由延展,互不影响。
在Java的基础知识中都会讲到继承,Java的三大特征嘛,封装、继承、多态。继承就是告诉你拥有父类的方法和属性,然后你就可以重写父类的方法。按照继承原则,我们上面的玩具枪继承AbstractGun是绝对没有问题的,玩具枪也是枪嘛,但是在具体应用场景中就要考虑下面这个问题了:子类是否能够完整地实现父类的业务,否则就会出现像上面的拿枪杀敌人时却发现是把玩具枪的笑话。
注意 如果子类不能完整地实现父类的方法,或者父类的某些方法在子类中已经发生“畸变”,则建议断开父子继承关系,采用依赖、聚集、组合等关系代替继承。
2.子类可以有自己的个性
子类当然可以有自己的行为和外观了,也就是方法和属性,那这里为什么要再提呢?是因为里氏替换原则可以正着用,但是不能反过来用。在子类出现的地方,父类未必就可以胜任。还是以刚才的关于枪支的例子为例,步枪有几个比较“响亮”的型号,比如AK47、AUG狙击步枪等,把这两个型号的枪引入后的Rifle子类图如图2-4所示。
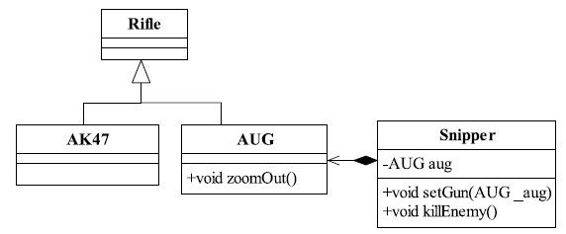
图2-4 增加AK47和AUG后的Rifle子类图
很简单,AUG继承了Rifle类,狙击手(Snipper)则直接使用AUG狙击步枪,源代码如代码清单2-7所示。
代码清单2-7 AUG狙击枪源码代码
public class AUG extends Rifle {
//狙击枪都携带一个精准的望远镜
public void zoomOut(){
System.out.println("通过望远镜察看敌人...");
}
public void shoot(){
System.out.println("AUG射击...");
}
}
有狙击枪就有狙击手,狙击手类的源代码如代码清单2-8所示。
代码清单2-8 AUG狙击手类的源码代码
public class Snipper {
public void killEnemy(AUG aug){
//首先看看敌人的情况,别杀死敌人,自己也被人干掉
aug.zoomOut();
//开始射击
aug.shoot();
}
}
狙击手,为什么叫Snipper?Snipe翻译过来就是鹬,就是“鹬蚌相争,渔人得利”中的那只鸟,英国贵族到印度打猎,发现这个鹬很聪明,人一靠近就飞走了,没办法就开始伪装、远程精准射击,于是乎Snipper就诞生了。
狙击手使用狙击枪来杀死敌人,业务场景Client类的源代码如代码清单2-9所示。
代码清单2-9 狙击手使用AUG杀死敌人
public class Client {
public static void main(String[] args) {
//产生三毛这个狙击手
Snipper sanMao = new Snipper();
sanMao.setRifle(new AUG());
sanMao.killEnemy();
}
}
狙击手使用G3杀死敌人,运行结果如下所示:
通过望远镜察看敌人…
AUG射击…
在这里,系统直接调用了子类,狙击手是很依赖枪支的,别说换一个型号的枪了,就是换一个同型号的枪也会影响射击,所以这里就直接把子类传递了进来。这个时候,我们能不能直接使用父类传递进来呢?修改一下Client类,如代码清单2-10所示。
代码清单2-10 使用父类作为参数
public class Client {
public static void main(String[] args) {
//产生三毛这个狙击手
Snipper sanMao = new Snipper();
sanMao.setRifle((AUG)(new Rifle()));
sanMao.killEnemy();
}
}
显示是不行的,会在运行期抛出java.lang.ClassCastException异常,这也是大家经常说的向下转型(downcast)是不安全的,从里氏替换原则来看,就是有子类出现的地方父类未必就可以出现。
3.覆盖或实现父类的方法时输入参数可以被放大
方法中的输入参数称为前置条件,这是什么意思呢?大家做过Web Service开发就应该知道有一个“契约优先”的原则,也就是先定义出WSDL接口,制定好双方的开发协议,然后再各自实现。里氏替换原则也要求制定一个契约,就是父类或接口,这种设计方法也叫做Design by Contract(契约设计),与里氏替换原则有着异曲同工之妙。契约制定了,也就同时制定了前置条件和后置条件,前置条件就是你要让我执行,就必须满足我的条件;后置条件就是我执行完了需要反馈,标准是什么。这个比较难理解,我们来看一个例子,我们先定义一个Father类,如代码清单2-11所示。
代码清单2-11 Father类源代码
public class Father {
public Collection doSomething(HashMap map){
System.out.println("父类被执行...");
return map.values();
}
}
这个类非常简单,就是把HashMap转换为Collection集合类型,然后再定义一个子类,源代码如代码清单2-12所示。
代码清单2-12 子类源代码
public class Son extends Father {
//放大输入参数类型
public Collection doSomething(Map map){
System.out.println("子类被执行...");
return map.values();
}
}
请注意粗体部分,与父类的方法名相同,但又不是覆写(Override)父类的方法。你加个@Override试试看,会报错的,为什么呢?方法名虽然相同,但方法的输入参数不同,就不是覆写,那这是什么呢?是重载(Overload)!不用大惊小怪的,不在一个类就不能是重载了?继承是什么意思,子类拥有父类的所有属性和方法,方法名相同,输入参数类型又不相同,当然是重载了。父类和子类都已经声明了,场景类的调用如代码清单2-13所示。
代码清单2-13 场景类源代码
public class Client {
public static void invoker(){
//父类存在的地方,子类就应该能够存在
Father f = new Father();
HashMap map = new HashMap();
f.doSomething(map);
}
public static void main(String[] args) {
invoker();
}
}
代码运行后的结果如下所示:
父类被执行…
根据里氏替换原则,父类出现的地方子类就可以出现,我们把上面的粗体部分修改为子类,如代码清单2-14所示。
代码清单2-14 子类替换父类后的源代码
public class Client {
public static void invoker(){
//父类存在的地方,子类就应该能够存在
Son f =new Son();
HashMap map = new HashMap();
f.doSomething(map);
}
public static void main(String[] args) {
invoker();
}
}
运行结果还是一样,看明白是怎么回事了吗?父类方法的输入参数是HashMap类型,子类的输入参数是Map类型,也就是说子类的输入参数类型的范围扩大了,子类代替父类传递到调用者中,子类的方法永远都不会被执行。这是正确的,如果你想让子类的方法运行,就必须覆写父类的方法。大家可以这样想,在一个Invoker类中关联了一个父类,调用了一个父类的方法,子类可以覆写这个方法,也可以重载这个方法,前提是要扩大这个前置条件,就是输入参数的类型宽于父类的类型覆盖范围。这样说可能比较难理解,我们再反过来想一下,如果Father类的输入参数类型宽于子类的输入参数类型,会出现什么问题呢?会出现父类存在的地方,子类就未必可以存在,因为一旦把子类作为参数传入,调用者就很可能进入子类的方法范畴。我们把上面的例子修改一下,扩大父类的前置条件,源代码如代码清单2-15所示。
代码清单2-15 父类的前置条件较大
public class Father {
public Collection doSomething(Map map){
System.out.println("父类被执行...");
return map.values();
}
}
把父类的前置条件修改为Map类型,我们再修改一下子类方法的输入参数,相对父类缩小输入参数的类型范围,也就是缩小前置条件,源代码如代码清单2-16所示。
代码清单2-16 子类的前置条件较小
public class Son extends Father {
//缩小输入参数范围
public Collection doSomething(HashMap map){
System.out.println("子类被执行...");
return map.values();
}
}
在父类的前置条件大于子类的前置条件的情况下,业务场景的源代码如代码清单2-17所示。
代码清单2-17 子类的前置条件较小
public class Client {
public static void invoker(){
//有父类的地方就有子类
Father f= new Father();
HashMap map = new HashMap();
f.doSomething(map);
}
public static void main(String[] args) {
invoker();
}
}
代码运行结果如下所示:
父类被执行…
那我们再把里氏替换原则引入进来会有什么问题?有父类的地方子类就可以使用,好,我们把这个Client类修改一下,源代码如代码清单2-18所示。
代码清单2-18 采用里氏替换原则后的业务场景类
public class Client {
public static void invoker(){
//有父类的地方就有子类
Son f =new Son();
HashMap map = new HashMap();
f.doSomething(map);
}
public static void main(String[] args) {
invoker();
}
}
代码运行后的结果如下所示:
子类被执行…
完蛋了吧?!子类在没有覆写父类的方法的前提下,子类方法被执行了,这会引起业务逻辑混乱,因为在实际应用中父类一般都是抽象类,子类是实现类,你传递一个这样的实现类就会“歪曲”了父类的意图,引起一堆意想不到的业务逻辑混乱,所以子类中方法的前置条件必须与超类中被覆写的方法的前置条件相同或者更宽松。
- 覆写或实现父类的方法时输出结果可以被缩小
这是什么意思呢,父类的一个方法的返回值是一个类型T,子类的相同方法(重载或覆写)的返回值为S,那么里氏替换原则就要求S必须小于等于T,也就是说,要么S和T是同一个类型,要么S是T的子类,为什么呢?分两种情况,如果是覆写,父类和子类的同名方法的输入参数是相同的,两个方法的范围值S小于等于T,这是覆写的要求,这才是重中之重,子类覆写父类的方法,天经地义。如果是重载,则要求方法的输入参数类型或数量不相同,在里氏替换原则要求下,就是子类的输入参数宽于或等于父类的输入参数,也就是说你写的这个方法是不会被调用的,参考上面讲的前置条件。
采用里氏替换原则的目的就是增强程序的健壮性,版本升级时也可以保持非常好的兼容性。即使增加子类,原有的子类还可以继续运行。在实际项目中,每个子类对应不同的业务含义,使用父类作为参数,传递不同的子类完成不同的业务逻辑,非常完美!
2.3 最佳实践
在项目中,采用里氏替换原则时,尽量避免子类的“个性”,一旦子类有“个性”,这个子类和父类之间的关系就很难调和了,把子类当做父类使用,子类的“个性”被抹杀——委屈了点;把子类单独作为一个业务来使用,则会让代码间的耦合关系变得扑朔迷离——缺乏类替换的标准。
依赖倒置原则
第3章 依赖倒置原则
3.1 依赖倒置原则的定义
依赖倒置原则(Dependence Inversion Principle,DIP)这个名字看着有点别扭,“依赖”还“倒置”,这到底是什么意思?依赖倒置原则的原始定义是:
High level modules should not depend upon low level modules.Both should depend upon abstractions.Abstractions should not depend upon details.Details should depend upon abstractions.
翻译过来,包含三层含义:
● 高层模块不应该依赖低层模块,两者都应该依赖其抽象;
● 抽象不应该依赖细节;
● 细节应该依赖抽象。
高层模块和低层模块容易理解,每一个逻辑的实现都是由原子逻辑组成的,不可分割的原子逻辑就是低层模块,原子逻辑的再组装就是高层模块。那什么是抽象?什么又是细节呢?在Java语言中,抽象就是指接口或抽象类,两者都是不能直接被实例化的;细节就是实现类,实现接口或继承抽象类而产生的类就是细节,其特点就是可以直接被实例化,也就是可以加上一个关键字new产生一个对象。依赖倒置原则在Java语言中的表现就是:
● 模块间的依赖通过抽象发生,实现类之间不发生直接的依赖关系,其依赖关系是通过接口或抽象类产生的;
● 接口或抽象类不依赖于实现类;
● 实现类依赖接口或抽象类。
更加精简的定义就是“面向接口编程”——OOD(Object-Oriented Design,面向对象设计)的精髓之一。
3.2 言而无信,你太需要契约
采用依赖倒置原则可以减少类间的耦合性,提高系统的稳定性,降低并行开发引起的风险,提高代码的可读性和可维护性。
证明一个定理是否正确,有两种常用的方法:一种是根据提出的论题,经过一番论证,推出和定理相同的结论,这是顺推证法;还有一种是首先假设提出的命题是伪命题,然后推导出一个荒谬、与已知条件互斥的结论,这是反证法。我们今天就用反证法来证明依赖倒置原则是多么优秀和伟大!
论题:依赖倒置原则可以减少类间的耦合性,提高系统的稳定性,降低并行开发引起的风险,提高代码的可读性和可维护性。
反论题:不使用依赖倒置原则也可以减少类间的耦合性,提高系统的稳定性,降低并行开发引起的风险,提高代码的可读性和可维护性。
我们通过一个例子来说明反论题是不成立的。现在的汽车越来越便宜了,一个卫生间的造价就可以买到一辆不错的汽车,有汽车就必然有人来驾驶,司机驾驶奔驰车的类图如图3-1所示。
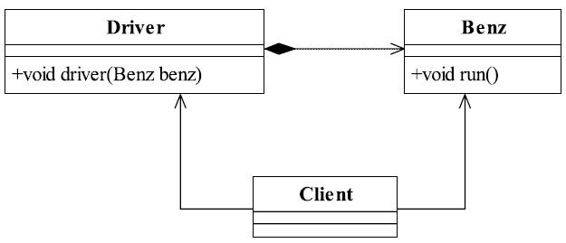
图3-1 司机驾驶奔驰车类图
奔驰车可以提供一个方法run,代表车辆运行,实现过程如代码清单3-1所示。
代码清单3-1 司机源代码
public class Driver {
//司机的主要职责就是驾驶汽车
public void drive(Benz benz){
benz.run();
}
}
司机通过调用奔驰车的run方法开动奔驰车,其源代码如代码清单3-2所示。
代码清单3-2 奔驰车源代码
public class Benz {
//汽车肯定会跑
public void run(){
System.out.println("奔驰汽车开始运行...");
}
}
有车,有司机,在Client场景类产生相应的对象,其源代码如代码清单3-3所示。
代码清单3-3 场景类源代码
public class Client {
public static void main(String[] args) {
Driver zhangSan = new Driver();
Benz benz = new Benz();
//张三开奔驰车
zhangSan.drive(benz);
}
}
通过以上的代码,完成了司机开动奔驰车的场景,到目前为止,这个司机开奔驰车的项目没有任何问题。我们常说“危难时刻见真情”,我们把这句话移植到技术上就成了“变更才显真功夫”,业务需求变更永无休止,技术前进就永无止境,在发生变更时才能发觉我们的设计或程序是否是松耦合。我们在一段貌似磐石的程序上加上一块小石头:张三司机不仅要开奔驰车,还要开宝马车,又该怎么实现呢?麻烦出来了,那好,我们走一步是一步,我们先把宝马车产生出来,实现过程如代码清单3-4所示。
代码清单3-4 宝马车源代码
public class BMW {
//宝马车当然也可以开动了
public void run(){
System.out.println("宝马汽车开始运行...");
}
}
宝马车也产生了,但是我们却没有办法让张三开动起来,为什么?张三没有开动宝马车的方法呀!一个拿有C驾照的司机竟然只能开奔驰车而不能开宝马车,这也太不合理了!在现实世界都不允许存在这种情况,何况程序还是对现实世界的抽象,我们的设计出现了问题:司机类和奔驰车类之间是紧耦合的关系,其导致的结果就是系统的可维护性大大降低,可读性降低,两个相似的类需要阅读两个文件,你乐意吗?还有稳定性,什么是稳定性?固化的、健壮的才是稳定的,这里只是增加了一个车类就需要修改司机类,这不是稳定性,这是易变性。被依赖者的变更竟然让依赖者来承担修改的成本,这样的依赖关系谁肯承担!证明到这里,我们已经知道反论题已经部分不成立了。
注意 设计是否具备稳定性,只要适当地“松松土”,观察“设计的蓝图”是否还可以茁壮地成长就可以得出结论,稳定性较高的设计,在周围环境频繁变化的时候,依然可以做到“我自岿然不动”。
我们继续证明,“减少并行开发引起的风险”,什么是并行开发的风险?并行开发最大的风险就是风险扩散,本来只是一段程序的错误或异常,逐步波及一个功能,一个模块,甚至到最后毁坏了整个项目。为什么并行开发就有这样的风险呢?一个团队,20个开发人员,各人负责不同的功能模块,甲负责汽车类的建造,乙负责司机类的建造,在甲没有完成的情况下,乙是不能完全地编写代码的,缺少汽车类,编译器根本就不会让你通过!在缺少Benz类的情况下,Driver类能编译吗?更不要说是单元测试了!在这种不使用依赖倒置原则的环境中,所有的开发工作都是“单线程”的,甲做完,乙再做,然后是丙继续……这在20世纪90年代“个人英雄主义”编程模式中还是比较适用的,一个人完成所有的代码工作。但在现在的大中型项目中已经是完全不能胜任了,一个项目是一个团队协作的结果,一个“英雄”再牛也不可能了解所有的业务和所有的技术,要协作就要并行开发,要并行开发就要解决模块之间的项目依赖关系,那然后呢?依赖倒置原则就隆重出场了!
根据以上证明,如果不使用依赖倒置原则就会加重类间的耦合性,降低系统的稳定性,增加并行开发引起的风险,降低代码的可读性和可维护性。承接上面的例子,引入依赖倒置原则后的类图如图3-2所示。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oarIutPp-1670180212551)(https://box.kancloud.cn/2016-08-14_57b0032281df0.jpg)]
图3-2 引入依赖倒置原则后的类图
建立两个接口:IDriver和ICar,分别定义了司机和汽车的各个职能,司机就是驾驶汽车,必须实现drive()方法,其实现过程如代码清单3-5所示。
代码清单3-5 司机接口
public interface IDriver {
//是司机就应该会驾驶汽车
public void drive(ICar car);
}
接口只是一个抽象化的概念,是对一类事物的最抽象描述,具体的实现代码由相应的实现类来完成,Driver实现类如代码清单3-6所示。
代码清单3-6 司机类的实现
public class Driver implements IDriver{
//司机的主要职责就是驾驶汽车
public void drive(ICar car){
car.run();
}
}
在IDriver中,通过传入ICar接口实现了抽象之间的依赖关系,Driver实现类也传入了ICar接口,至于到底是哪个型号的Car,需要在高层模块中声明。
ICar及其两个实现类的实现过程如代码清单3-7所示。
代码清单3-7 汽车接口及两个实现类
public interface ICar {
//是汽车就应该能跑
public void run();
}
public class Benz implements ICar{
//汽车肯定会跑
public void run(){
System.out.println("奔驰汽车开始运行...");
}
}
public class BMW implements ICar{
//宝马车当然也可以开动了
public void run(){
System.out.println("宝马汽车开始运行...");
}
}
在业务场景中,我们贯彻“抽象不应该依赖细节”,也就是我们认为抽象(ICar接口)不依赖BMW和Benz两个实现类(细节),因此在高层次的模块中应用都是抽象,Client的实现过程如代码清单3-8所示。
代码清单3-8 业务场景
public class Client {
public static void main(String[] args) {
IDriver zhangSan = new Driver();
ICar benz = new Benz();
//张三开奔驰车
zhangSan.drive(benz);
}
}
Client属于高层业务逻辑,它对低层模块的依赖都建立在抽象上,zhangSan的表面类型是IDriver,Benz的表面类型是ICar,也许你要问,在这个高层模块中也调用到了低层模块,比如new Driver()和new Benz()等,如何解释?确实如此,zhangSan的表面类型是IDriver,是一个接口,是抽象的、非实体化的,在其后的所有操作中,zhangSan都是以IDriver类型进行操作,屏蔽了细节对抽象的影响。当然,张三如果要开宝马车,也很容易,我们只要修改业务场景类就可以,实现过程如代码清单3-9所示。
代码清单3-9 张三驾驶宝马车的实现过程
public class Client {
public static void main(String[] args) {
IDriver zhangSan = new Driver();
ICar bmw = new BMW();
//张三开奔驰车
zhangSan.drive(bmw);
}
}
在新增加低层模块时,只修改了业务场景类,也就是高层模块,对其他低层模块如Driver类不需要做任何修改,业务就可以运行,把“变更”引起的风险扩散降到最低。
注意 在Java中,只要定义变量就必然要有类型,一个变量可以有两种类型:表面类型和实际类型,表面类型是在定义的时候赋予的类型,实际类型是对象的类型,如zhangSan的表面类型是IDriver,实际类型是Driver。
我们再来思考依赖倒置对并行开发的影响。两个类之间有依赖关系,只要制定出两者之间的接口(或抽象类)就可以独立开发了,而且项目之间的单元测试也可以独立地运行,而TDD(Test-Driven Development,测试驱动开发)开发模式就是依赖倒置原则的最高级应用。我们继续回顾上面司机驾驶汽车的例子,甲程序员负责IDriver的开发,乙程序员负责ICar的开发,两个开发人员只要制定好了接口就可以独立地开发了,甲开发进度比较快,完成了IDriver以及相关的实现类Driver的开发工作,而乙程序员滞后开发,那甲是否可以进行单元测试呢?答案是可以,我们引入一个JMock工具,其最基本的功能是根据抽象虚拟一个对象进行测试,测试类如代码清单3-10所示。
代码清单3-10 测试类
public class DriverTest extends TestCase{
Mockery context = new JUnit4Mockery();
@Test
public void testDriver() {
//根据接口虚拟一个对象
final ICar car = context.mock(ICar.class);
IDriver driver = new Driver();
//内部类
context.checking(new Expectations(){{
oneOf (car).run();
}});
driver.drive(car);
}
}
注意粗体部分,我们只需要一个ICar的接口,就可以对Driver类进行单元测试。从这一点来看,两个相互依赖的对象可以分别进行开发,孤立地进行单元测试,进而保证并行开发的效率和质量,TDD开发的精髓不就在这里吗?测试驱动开发,先写好单元测试类,然后再写实现类,这对提高代码的质量有非常大的帮助,特别适合研发类项目或在项目成员整体水平比较低的情况下采用。
抽象是对实现的约束,对依赖者而言,也是一种契约,不仅仅约束自己,还同时约束自己与外部的关系,其目的是保证所有的细节不脱离契约的范畴,确保约束双方按照既定的契约(抽象)共同发展,只要抽象这根基线在,细节就脱离不了这个圈圈,始终让你的对象做到“言必信,行必果”。
3.3 依赖的三种写法
依赖是可以传递的,A对象依赖B对象,B又依赖C,C又依赖D……生生不息,依赖不止,记住一点:只要做到抽象依赖,即使是多层的依赖传递也无所畏惧!
对象的依赖关系有三种方式来传递,如下所示。
1.构造函数传递依赖对象
在类中通过构造函数声明依赖对象,按照依赖注入的说法,这种方式叫做构造函数注入,按照这种方式的注入,IDriver和Driver的程序修改后如代码清单3-11所示。
代码清单3-11 构造函数传递依赖对象
public interface IDriver {
//是司机就应该会驾驶汽车
public void drive();
}
public class Driver implements IDriver{
private ICar car;
//构造函数注入
public Driver(ICar _car){
this.car = _car;
}
//司机的主要职责就是驾驶汽车
public void drive(){
this.car.run();
}
}
2.Setter方法传递依赖对象
在抽象中设置Setter方法声明依赖关系,依照依赖注入的说法,这是Setter依赖注入,按照这种方式的注入,IDriver和Driver的程序修改后如代码清单3-12所示。
代码清单3-12 Setter依赖注入
public interface IDriver {
//车辆型号
public void setCar(ICar car);
//是司机就应该会驾驶汽车
public void drive();
}
public class Driver implements IDriver{
private ICar car;
public void setCar(ICar car){
this.car = car;
}
//司机的主要职责就是驾驶汽车
public void drive(){
this.car.run();
}
}
3.接口声明依赖对象
在接口的方法中声明依赖对象,3.2节的例子就采用了接口声明依赖的方式,该方法也叫做接口注入。
3.4 最佳实践
依赖倒置原则的本质就是通过抽象(接口或抽象类)使各个类或模块的实现彼此独立,不互相影响,实现模块间的松耦合,我们怎么在项目中使用这个规则呢?只要遵循以下的几个规则就可以:
● 每个类尽量都有接口或抽象类,或者抽象类和接口两者都具备
这是依赖倒置的基本要求,接口和抽象类都是属于抽象的,有了抽象才可能依赖倒置。
● 变量的表面类型尽量是接口或者是抽象类
很多书上说变量的类型一定要是接口或者是抽象类,这个有点绝对化了,比如一个工具类,xxxUtils一般是不需要接口或是抽象类的。还有,如果你要使用类的clone方法,就必须使用实现类,这个是JDK提供的一个规范。
● 任何类都不应该从具体类派生
如果一个项目处于开发状态,确实不应该有从具体类派生出子类的情况,但这也不是绝对的,因为人都是会犯错误的,有时设计缺陷是在所难免的,因此只要不超过两层的继承都是可以忍受的。特别是负责项目维护的同志,基本上可以不考虑这个规则,为什么?维护工作基本上都是进行扩展开发,修复行为,通过一个继承关系,覆写一个方法就可以修正一个很大的Bug,何必去继承最高的基类呢?(当然这种情况尽量发生在不甚了解父类或者无法获得父类代码的情况下。)
● 尽量不要覆写基类的方法
如果基类是一个抽象类,而且这个方法已经实现了,子类尽量不要覆写。类间依赖的是抽象,覆写了抽象方法,对依赖的稳定性会产生一定的影响。
● 结合里氏替换原则使用
在第2章中我们讲解了里氏替换原则,父类出现的地方子类就能出现,再结合本章的讲解,我们可以得出这样一个通俗的规则: 接口负责定义public属性和方法,并且声明与其他对象的依赖关系,抽象类负责公共构造部分的实现,实现类准确的实现业务逻辑,同时在适当的时候对父类进行细化。
讲了这么多,估计大家对“倒置”这个词还是有点不理解,那到底什么是“倒置”呢?我们先说“正置”是什么意思,依赖正置就是类间的依赖是实实在在的实现类间的依赖,也就是面向实现编程,这也是正常人的思维方式,我要开奔驰车就依赖奔驰车,我要使用笔记本电脑就直接依赖笔记本电脑,而编写程序需要的是对现实世界的事物进行抽象,抽象的结果就是有了抽象类和接口,然后我们根据系统设计的需要产生了抽象间的依赖,代替了人们传统思维中的事物间的依赖,“倒置”就是从这里产生的。
依赖倒置原则的优点在小型项目中很难体现出来,例如小于10个人月的项目,使用简单的SSH架构,基本上不费太大力气就可以完成,是否采用依赖倒置原则影响不大。但是,在一个大中型项目中,采用依赖倒置原则有非常多的优点,特别是规避一些非技术因素引起的问题。项目越大,需求变化的概率也越大,通过采用依赖倒置原则设计的接口或抽象类对实现类进行约束,可以减少需求变化引起的工作量剧增的情况。人员的变动在大中型项目中也是时常存在的,如果设计优良、代码结构清晰,人员变化对项目的影响基本为零。大中型项目的维护周期一般都很长,采用依赖倒置原则可以让维护人员轻松地扩展和维护。
依赖倒置原则是6个设计原则中最难以实现的原则,它是实现开闭原则的重要途径,依赖倒置原则没有实现,就别想实现对扩展开放,对修改关闭。在项目中,大家只要记住是“面向接口编程”就基本上抓住了依赖倒置原则的核心。
讲了这么多依赖倒置原则的优点,我们也来打击一下大家,在现实世界中确实存在着必须依赖细节的事物,比如法律,就必须依赖细节的定义。“杀人偿命”在中国的法律中古今有之[1],那这里的“杀人”就是一个抽象的含义,怎么杀,杀什么人,为什么杀人,都没有定义,只要是杀人就统统得偿命,这就是有问题了,好人杀了坏人,还要陪上自己的一条性命,这是不公正的,从这一点看,我们在实际的项目中使用依赖倒置原则时需要审时度势,不要抓住一个原则不放,每一个原则的优点都是有限度的,并不是放之四海而皆准的真理,所以别为了遵循一个原则而放弃了一个项目的终极目标:投产上线和盈利。作为一个项目经理或架构师,应该懂得技术只是实现目的的工具,惹恼了顶头上司,设计做得再漂亮,代码写得再完美,项目做得再符合标准,一旦项目亏本,产品投入大于产出,那整体就是扯淡!你自己也别想混得更好!
[1]当年汉高祖刘邦入关后与老百姓约法三章,其中有一条就是:“杀人者死,伤人及盗抵罪。”
接口隔离原则
第4章 接口隔离原则
4.1 接口隔离原则的定义
在讲接口隔离原则之前,先明确一下我们的主角——接口。接口分为两种:
● 实例接口(Object Interface),在Java中声明一个类,然后用new关键字产生一个实例,它是对一个类型的事物的描述,这是一种接口。比如你定义Person这个类,然后使用Person zhangSan=new Person()产生了一个实例,这个实例要遵从的标准就是Person这个类,Person类就是zhangSan的接口。疑惑?看不懂?不要紧,那是因为让Java语言浸染的时间太长了,只要知道从这个角度来看,Java中的类也是一种接口。
● 类接口(Class Interface),Java中经常使用的interface关键字定义的接口。
主角已经定义清楚了,那什么是隔离呢?它有两种定义,如下所示:
● Clients should not be forced to depend upon interfaces that they don’t use.(客户端不应该依赖它不需要的接口。)
● The dependency of one class to another one should depend on the smallest possible interface.(类间的依赖关系应该建立在最小的接口上。)
新事物的定义一般都比较难理解,晦涩难懂是正常的。我们把这两个定义剖析一下,先说第一种定义:“客户端不应该依赖它不需要的接口”,那依赖什么?依赖它需要的接口,客户端需要什么接口就提供什么接口,把不需要的接口剔除掉,那就需要对接口进行细化,保证其纯洁性;再看第二种定义:“类间的依赖关系应该建立在最小的接口上”,它要求是最小的接口,也是要求接口细化,接口纯洁,与第一个定义如出一辙,只是一个事物的两种不同描述。
我们可以把这两个定义概括为一句话:建立单一接口,不要建立臃肿庞大的接口。再通俗一点讲:接口尽量细化,同时接口中的方法尽量少。看到这里大家有可能要疑惑了,这与单一职责原则不是相同的吗?错,接口隔离原则与单一职责的审视角度是不相同的,单一职责要求的是类和接口职责单一,注重的是职责,这是业务逻辑上的划分,而接口隔离原则要求接口的方法尽量少。例如一个接口的职责可能包含10个方法,这10个方法都放在一个接口中,并且提供给多个模块访问,各个模块按照规定的权限来访问,在系统外通过文档约束“不使用的方法不要访问”,按照单一职责原则是允许的,按照接口隔离原则是不允许的,因为它要求“尽量使用多个专门的接口”。专门的接口指什么?就是指提供给每个模块的都应该是单一接口,提供给几个模块就应该有几个接口,而不是建立一个庞大的臃肿的接口,容纳所有的客户端访问。
4.2 美女何其多,观点各不同
我们举例来说明接口隔离原则到底对我们提出了什么要求。现在男生对小姑娘的称呼,使用频率最高的应该是“美女”了吧,你在大街上叫一声:“嗨,美女!”估计10个有8个回头,其中包括那位著名的如花。美女的标准各不相同,首先就需要定义一下什么是美女:首先要面貌好看,其次是身材要窈窕,然后要有气质,当然了,这三者各人的排列顺序不一样,总之要成为一名美女就必须具备:面貌、身材和气质,我们用类图体现一下星探(当然,你也可以把自己想象成星探)找美女的过程,如图4-1所示。
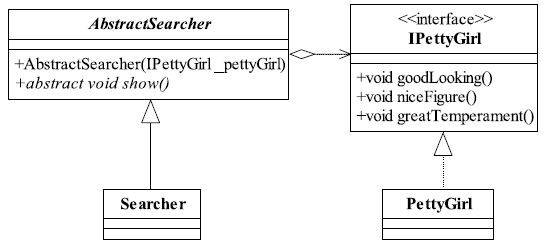
图4-1 星探寻找美女的类图
定义了一个IPettyGirl接口,声明所有的美女都应该有goodLooking、niceFigure和great-Temperament,然后又定义了一个抽象类AbstractSearcher,其作用就是搜索美女并显示其信息,只要美女都按照这个规范定义,Searcher(星探)就轻松多了,美女类的实现如代码清单4-1所示。
代码清单4-1 美女类
public interface IPettyGirl {
//要有姣好的面孔
public void goodLooking();
//要有好身材
public void niceFigure();
//要有气质
public void greatTemperament();
}
美女的标准定义完毕,具体的美女实现类如代码清单4-2所示。
代码清单4-2 美女实现类
public class PettyGirl implements IPettyGirl {
private String name;
//美女都有名字
public PettyGirl(String _name){
this.name=_name;
}
//脸蛋漂亮
public void goodLooking() {
System.out.println(this.name + “—脸蛋很漂亮!”);
}
//气质要好
public void greatTemperament() {
System.out.println(this.name + “—气质非常好!”);
}
//身材要好
public void niceFigure() {
System.out.println(this.name + “—身材非常棒!”);
}
}
通过三个方法,把对美女的要求都定义出来了,按照这个标准,如花姑娘被排除在美女标准之外了。有美女,就有搜索美女的星探,其具体实现如代码清单4-3所示。
代码清单4-3 星探抽象类源代码
public abstract class AbstractSearcher {
protected IPettyGirl pettyGirl;
public AbstractSearcher(IPettyGirl _pettyGirl){
this.pettyGirl = _pettyGirl;
}
//搜索美女,列出美女信息
public abstract void show();
}
星探的实现类就比较简单了,其源代码如代码清单4-4所示。
代码清单4-4 星探类
public class Searcher extends AbstractSearcher{
public Searcher(IPettyGirl _pettyGirl){
super(_pettyGirl);
}
//展示美女的信息
public void show(){
System.out.println(“--------美女的信息如下:---------------”);
//展示面容
super.pettyGirl.goodLooking();
//展示身材
super.pettyGirl.niceFigure();
//展示气质
super.pettyGirl.greatTemperament();
}
}
场景中的两个角色美女和星探都已经出现了,需要写一个场景类来串联起各个角色,场景类的实现如代码清单4-5所示。
代码清单4-5 场景类
public class Client {
//搜索并展示美女信息
public static void main(String[] args) {
//定义一个美女
IPettyGirl yanYan = new PettyGirl(“嫣嫣”);
AbstractSearcher searcher = new Searcher(yanYan);
searcher.show();
}
}
星探搜索美女的运行结果如下所示:
--------美女的信息如下:---------------
嫣嫣—脸蛋很漂亮!
嫣嫣—身材非常棒!
嫣嫣—气质非常好!
星探寻找美女的程序开发完毕了,运行结果也正确。我们回头来想想这个程序有没有问题,思考一下IPettyGirl这个接口,这个接口是否做到了最优化设计?答案是没有,还可以对接口进行优化。
我们的审美观点都在改变,美女的定义也在变化。唐朝的杨贵妃如果活在现在这个年代非羞愧而死不可,为什么?胖呀!但是胖并不影响她入选中国四大美女,说明当时的审美观与现在是有差异的。当然,随着时代的发展我们的审美观也在变化,当你发现有一个女孩,脸蛋不怎么样,身材也一般般,但是气质非常好,我相信大部分人都会把这样的女孩叫美女,审美素质提升了,就产生了气质型美女,但是我们的接口却定义了美女必须是三者都具备,按照这个标准,气质型美女就不能算美女,那怎么办?可能你要说了,我重新扩展一个美女类,只实现greatTemperament方法,其他两个方法置空,什么都不写,不就可以了吗?聪明,但是行不通!为什么呢?星探AbstractSearcher依赖的是IPettyGirl接口,它有三个方法,你只实现了两个方法,星探的方法是不是要修改?我们上面的程序打印出来的信息少了两条,还让星探怎么去辨别是不是美女呢?
分析到这里,我们发现接口IPettyGirl的设计是有缺陷的,过于庞大了,容纳了一些可变的因素,根据接口隔离原则,星探AbstractSearcher应该依赖于具有部分特质的女孩子,而我们却把这些特质都封装了起来,放到了一个接口中,封装过度了!问题找到了,我们重新设计一下类图,修改后的类图如图4-2所示。
把原IPettyGirl接口拆分为两个接口,一种是外形美的美女IGoodBodyGirl,这类美女的特点就是脸蛋和身材极棒,超一流,但是没有审美素质,比如随地吐痰,文化程度比较低;另外一种是气质美的美女IGreatTemperamentGirl,谈吐和修养都非常高。我们把一个比较臃肿的接口拆分成了两个专门的接口,灵活性提高了,可维护性也增加了,不管以后是要外形美的美女还是气质美的美女都可以轻松地通过PettyGirl定义。两种类型的美女定义如代码清单4-6所示。
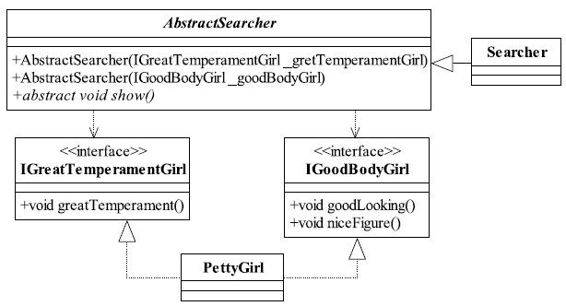
图4-2 修改后的星探寻找美女类图
代码清单4-6 两种类型的美女定义
public interface IGoodBodyGirl {
//要有姣好的面孔
public void goodLooking();
//要有好身材
public void niceFigure();
}
public interface IGreatTemperamentGirl {
//要有气质
public void greatTemperament();
}
按照脸蛋、身材、气质都具备才算美女,实现类实现两个接口,如代码清单4-7所示。
代码清单4-7 最标准的美女
public class PettyGirl implements IGoodBodyGirl,IGreatTemperamentGirl {
private String name;
//美女都有名字
public PettyGirl(String _name){
this.name=_name;
}
//脸蛋漂亮
public void goodLooking() {
System.out.println(this.name + “—脸蛋很漂亮!”);
}
//气质要好
public void greatTemperament() {
System.out.println(this.name + “—气质非常好!”);
}
//身材要好
public void niceFigure() {
System.out.println(this.name + “—身材非常棒!”);
}
}
通过这样的重构以后,不管以后是要气质美女还是要外形美女,都可以保持接口的稳定。当然,你可能要说了,以后可能审美观点再发生改变,只有脸蛋好看就是美女,那这个IGoodBody接口还是要修改的呀,确实是,但是设计是有限度的,不能无限地考虑未来的变更情况,否则就会陷入设计的泥潭中而不能自拔。
以上把一个臃肿的接口变更为两个独立的接口所依赖的原则就是接口隔离原则,让星探AbstractSearcher依赖两个专用的接口比依赖一个综合的接口要灵活。接口是我们设计时对外提供的契约,通过分散定义多个接口,可以预防未来变更的扩散,提高系统的灵活性和可维护性。
4.3 保证接口的纯洁性
接口隔离原则是对接口进行规范约束,其包含以下4层含义:
● 接口要尽量小
这是接口隔离原则的核心定义,不出现臃肿的接口(Fat Interface),但是“小”是有限度的,首先就是不能违反单一职责原则,什么意思呢?我们在单一职责原则中提到一个IPhone的例子,在这里,我们使用单一职责原则把两个职责分解到两个接口中,类图如图4-3所示。
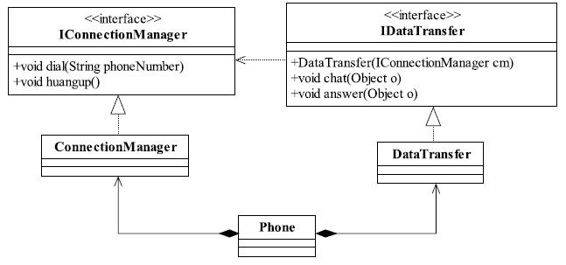
图4-3 电话类图
仔细分析一下IConnectionManager接口是否还可以再继续拆分下去,挂电话有两种方式:一种是正常的电话挂断,一种是电话异常挂机,比如突然没电了,通信当然就断了。这两种方式的处理应该是不同的,为什么呢?正常挂电话,对方接受到挂机信号,计费系统也就停止计费了,那手机没电了这种方式就不同了,它是信号丢失了,中继服务器检查到了,然后通知计费系统停止计费,否则你的费用不是要疯狂地增长了吗?
思考到这里,我们是不是就要动手把IConnectionManager接口拆封成两个,一个接口是负责连接,一个接口是负责挂电话?是要这样做吗?且慢,让我们再思考一下,如果拆分了,那就不符合单一职责原则了,因为从业务逻辑上来讲,通信的建立和关闭已经是最小的业务单位了,再细分下去就是对业务或是协议(其他业务逻辑)的拆分了。想想看,一个电话要关心3G协议,要考虑中继服务器,等等,这个电话还怎么设计得出来呢?从业务层次来看,这样的设计就是一个失败的设计。一个原则要拆,一个原则又不要拆,那该怎么办?好办,根据接口隔离原则拆分接口时,首先必须满足单一职责原则。
● 接口要高内聚
什么是高内聚?高内聚就是提高接口、类、模块的处理能力,减少对外的交互。比如你告诉下属“到奥巴马的办公室偷一个×××文件”,然后听到下属用坚定的口吻回答你:“是,保证完成任务!”一个月后,你的下属还真的把×××文件放到你的办公桌上了,这种不讲任何条件、立刻完成任务的行为就是高内聚的表现。具体到接口隔离原则就是,要求在接口中尽量少公布public方法,接口是对外的承诺,承诺越少对系统的开发越有利,变更的风险也就越少,同时也有利于降低成本。
● 定制服务
一个系统或系统内的模块之间必然会有耦合,有耦合就要有相互访问的接口(并不一定就是Java中定义的Interface,也可能是一个类或单纯的数据交换),我们设计时就需要为各个访问者(即客户端)定制服务,什么是定制服务?定制服务就是单独为一个个体提供优良的服务。我们在做系统设计时也需要考虑对系统之间或模块之间的接口采用定制服务。采用定制服务就必然有一个要求:只提供访问者需要的方法,这是什么意思?我们举个例子来说明,比如我们开发了一个图书管理系统,其中有一个查询接口,方便管理员查询图书,其类图如图4-4所示。

图4-4 图书查询类图
在接口中定义了多个查询方法,分别可以按照作者、标题、出版社、分类进行查询,最后还提供了混合查询方式。程序写好了,投产上线了,突然有一天发现系统速度非常慢,然后就开始痛苦地分析,最终发现是访问接口中的complexSearch(Map map)方法并发量太大,导致应用服务器性能下降,然后继续跟踪下去发现这些查询都是从公网上发起的,进一步分析,找到问题:提供给公网(公网项目是另外一个项目组开发的)的查询接口和提供给系统内管理人员的接口是相同的,都是IBookSearcher接口,但是权限不同,系统管理人员可以通过接口的complexSearch方法查询到所有的书籍,而公网的这个方法是被限制的,不返回任何值,在设计时通过口头约束,这个方法是不可被调用的,但是由于公网项目组的疏忽,这个方法还是公布了出去,虽然不能返回结果,但是还是引起了应用服务器的性能巨慢的情况发生,这就是一个臃肿接口引起性能故障的案例。
问题找到了,就需要把这个接口进行重构,将IBookSearcher拆分为两个接口,分别为两个模块提供定制服务,修改后的类图如图4-5所示。
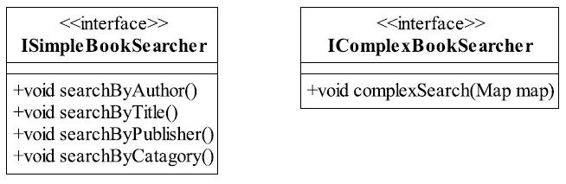
图4-5 修改后的图书查询类图
提供给管理人员的实现类同时实现了ISimpleBookSearcher和IComplexBookSearcher两个接口,原有程序不用做任何改变,而提供给公网的接口变为ISimpleBookSearcher,只允许进行简单的查询,单独为其定制服务,减少可能引起的风险。
● 接口设计是有限度的
接口的设计粒度越小,系统越灵活,这是不争的事实。但是,灵活的同时也带来了结构的复杂化,开发难度增加,可维护性降低,这不是一个项目或产品所期望看到的,所以接口设计一定要注意适度,这个“度”如何来判断呢?根据经验和常识判断,没有一个固化或可测量的标准。
4.4 最佳实践
接口隔离原则是对接口的定义,同时也是对类的定义,接口和类尽量使用原子接口或原子类来组装。但是,这个原子该怎么划分是设计模式中的一大难题,在实践中可以根据以下几个规则来衡量:
● 一个接口只服务于一个子模块或业务逻辑;
● 通过业务逻辑压缩接口中的public方法,接口时常去回顾,尽量让接口达到“满身筋骨肉”,而不是“肥嘟嘟”的一大堆方法;
● 已经被污染了的接口,尽量去修改,若变更的风险较大,则采用适配器模式进行转化处理;
● 了解环境,拒绝盲从。每个项目或产品都有特定的环境因素,别看到大师是这样做的你就照抄。千万别,环境不同,接口拆分的标准就不同。深入了解业务逻辑,最好的接口设计就出自你的手中!
接口隔离原则和其他设计原则一样,都需要花费较多的时间和精力来进行设计和筹划,但是它带来了设计的灵活性,让你可以在业务人员提出“无理”要求时轻松应付。贯彻使用接口隔离原则最好的方法就是一个接口一个方法,保证绝对符合接口隔离原则(有可能不符合单一职责原则),但你会采用吗?不会,除非你是疯子!那怎么才能正确地使用接口隔离原则呢?答案是根据经验和常识决定接口的粒度大小,接口粒度太小,导致接口数据剧增,开发人员呛死在接口的海洋里;接口粒度太大,灵活性降低,无法提供定制服务,给整体项目带来无法预料的风险。
怎么准确地实践接口隔离原则?实践、经验和领悟!
迪米特法则
第5章 迪米特法则
5.1 迪米特法则的定义
迪米特法则(Law of Demeter,LoD)也称为最少知识原则(Least Knowledge Principle,LKP),虽然名字不同,但描述的是同一个规则:一个对象应该对其他对象有最少的了解。通俗地讲,一个类应该对自己需要耦合或调用的类知道得最少,你(被耦合或调用的类)的内部是如何复杂都和我没关系,那是你的事情,我就知道你提供的这么多public方法,我就调用这么多,其他的我一概不关心。
5.2 我的知识你知道得越少越好
迪米特法则对类的低耦合提出了明确的要求,其包含以下4层含义。
- 只和朋友交流
迪米特法则还有一个英文解释是:Only talk to your immediate friends(只与直接的朋友通信。)什么叫做直接的朋友呢?每个对象都必然会与其他对象有耦合关系,两个对象之间的耦合就成为朋友关系,这种关系的类型有很多,例如组合、聚合、依赖等。下面我们将举例说明如何才能做到只与直接的朋友交流。
传说中有这样一个故事,老师想让体育委员确认一下全班女生来齐没有,就对他说:“你去把全班女生清一下。”体育委员没听清楚,就问道:“呀,……那亲哪个?”老师无语了,我们来看这个笑话怎么用程序来实现,类图如图5-1所示。
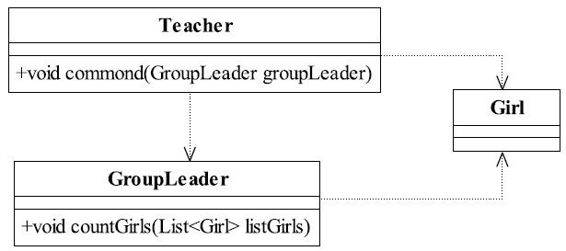
图5-1 老师要求清点女生类图
Teacher类的commond方法负责发送命令给体育会员,命令他清点女生,其实现过程如代码清单5-1所示。
代码清单5-1 老师类
public class Teacher {
//老师对学生发布命令,清一下女生
public void commond(GroupLeader groupLeader){
List listGirls = new ArrayList();
//初始化女生
for(int i=0;i<20;i++){
listGirls.add(new Girl());
}
//告诉体育委员开始执行清查任务
groupLeader.countGirls(listGirls);
}
}
老师只有一个方法commond,先定义出所有的女生,然后发布命令给体育委员,去清点一下女生的数量。体育委员GroupLeader的实现过程如代码清单5-2所示。
代码清单5-2 体育委员类实现过程
public class GroupLeader {
//清查女生数量
public void countGirls(List listGirls){
System.out.println(“女生数量是:”+listGirls.size());
}
}
老师类和体育委员类都对女生类产生依赖,而且女生类不需要执行任何动作,因此定义一个空类,其实现过程如代码清单5-3所示。
代码清单5-3 女生类
public class Girl {
}
故事中的三个角色都已经有了,再定义一个场景类来描述这个故事,其实现过程如代码清单5-4所示。
代码清单5-4 场景类
public class Client {
public static void main(String[] args) {
Teacher teacher= new Teacher();
//老师发布命令
teacher.commond(new GroupLeader());
}
}
运行结果如下所示:
女生数量是:20
体育委员按照老师的要求对女生进行了清点,并得出了数量。我们回过头来思考一下这个程序有什么问题,首先确定Teacher类有几个朋友类,它仅有一个朋友类——GroupLeader。为什么Girl不是朋友类呢?Teacher也对它产生了依赖关系呀!朋友类的定义是这样的:出现在成员变量、方法的输入输出参数中的类称为成员朋友类,而出现在方法体内部的类不属于朋友类,而Girl这个类就是出现在commond方法体内,因此不属于Teacher类的朋友类。迪米特法则告诉我们一个类只和朋友类交流,但是我们刚刚定义的commond方法却与Girl类有了交流,声明了一个List动态数组,也就是与一个陌生的类Girl有了交流,这样就破坏了Teacher的健壮性。方法是类的一个行为,类竟然不知道自己的行为与其他类产生依赖关系,这是不允许的,严重违反了迪米特法则。
问题已经发现,我们修改一下程序,将类图稍作修改,如图5-2所示。
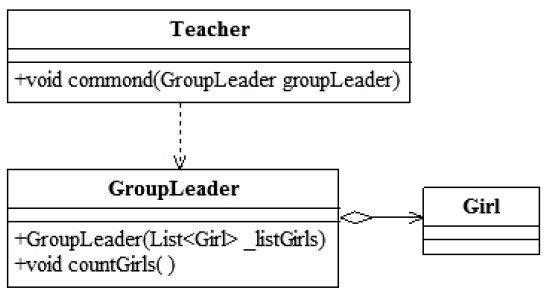
图5-2 修改后的类图
在类图中去掉Teacher对Girl类的依赖关系,修改后的Teacher类如代码清单5-5所示。
代码清单5-5 修改后的老师类
public class Teacher {
//老师对学生发布命令,清一下女生
public void commond(GroupLeader groupLeader){
//告诉体育委员开始执行清查任务
groupLeader.countGirls();
}
}
修改后的GroupLeader类如代码清代5-6所示。
代码清单5-6 修改后的体育委员类
public class GroupLeader {
private List listGirls;
//传递全班的女生进来
public GroupLeader(List _listGirls){
this.listGirls = _listGirls;
}
//清查女生数量
public void countGirls(){
System.out.println(“女生数量是:”+this.listGirls.size());
}
}
在GroupLeader类中定义了一个构造函数,通过构造函数传递了依赖关系。同时,对场景类也进行了一些修改,如代码清单5-7所示。
代码清单5-7 修改后的场景类
public class Client {
public static void main(String[] args) {
//产生一个女生群体
List listGirls = new ArrayList();
//初始化女生
for(int i=0;i<20;i++){
listGirls.add(new Girl());
}
Teacher teacher= new Teacher();
//老师发布命令
teacher.commond(new GroupLeader(listGirls));
}
}
对程序进行了简单的修改,把Teacher中对List的初始化移动到了场景类中,同时在GroupLeader中增加了对Girl的注入,避开了Teacher类对陌生类Girl的访问,降低了系统间的耦合,提高了系统的健壮性。
注意 一个类只和朋友交流,不与陌生类交流,不要出现getA().getB().getC().getD()这种情况(在一种极端的情况下允许出现这种访问,即每一个点号后面的返回类型都相同),类与类之间的关系是建立在类间的,而不是方法间,因此一个方法尽量不引入一个类中不存在的对象,当然,JDK API提供的类除外。
- 朋友间也是有距离的
人和人之间是有距离的,太远关系逐渐疏远,最终形同陌路;太近就相互刺伤。对朋友关系描述最贴切的故事就是:两只刺猬取暖,太远取不到暖,太近刺伤了对方,必须保持一个既能取暖又不刺伤对方的距离。迪米特法则就是对这个距离进行描述,即使是朋友类之间也不能无话不说,无所不知。
我们在安装软件的时候,经常会有一个导向动作,第一步是确认是否安装,第二步确认License,再然后选择安装目录……这是一个典型的顺序执行动作,具体到程序中就是:调用一个或多个类,先执行第一个方法,然后是第二个方法,根据返回结果再来看是否可以调用第三个方法,或者第四个方法,等等,其类图如图5-3所示。

图5-3 软件安装过程类图
很简单的类图,实现软件安装的过程,其中first方法定义第一步做什么,second方法定义第二步做什么,third方法定义第三步做什么,其实现过程如代码清单5-8所示。
代码清单5-8 导向类
public class Wizard {
private Random rand = new Random(System.currentTimeMillis());
//第一步
public int first(){
System.out.println(“执行第一个方法…”);
return rand.nextInt(100);
}
//第二步
public int second(){
System.out.println(“执行第二个方法…”);
return rand.nextInt(100);
}
//第三个方法
public int third(){
System.out.println(“执行第三个方法…”);
return rand.nextInt(100);
}
}
在Wizard类中分别定义了三个步骤方法,每个步骤中都有相关的业务逻辑完成指定的任务,我们使用一个随机函数来代替业务执行的返回值。软件安装InstallSoftware类如代码清单5-9所示。
代码清单5-9 InstallSoftware类
public class InstallSoftware {
public void installWizard(Wizard wizard){
int first = wizard.first();
//根据first返回的结果,看是否需要执行second
if(first>50){
int second = wizard.second();
if(second>50){
int third = wizard.third();
if(third >50){
wizard.first();
}
}
}
}
}
根据每个方法执行的结果决定是否继续执行下一个方法,模拟人工的选择操作。场景类如代码清单5-10所示。
代码清单5-10 场景类
public class Client {
public static void main(String[] args) {
InstallSoftware invoker = new InstallSoftware();
invoker.installWizard(new Wizard());
}
}
以上程序很简单,运行结果和随机数有关,每次的执行结果都不相同,需要读者自己运行并查看结果。程序虽然简单,但是隐藏的问题可不简单,思考一下程序有什么问题。Wizard类把太多的方法暴露给InstallSoftware类,两者的朋友关系太亲密了,耦合关系变得异常牢固。如果要将Wizard类中的first方法返回值的类型由int改为boolean,就需要修改InstallSoftware类,从而把修改变更的风险扩散开了。因此,这样的耦合是极度不合适的,我们需要对设计进行重构,重构后的类图如图5-4所示。
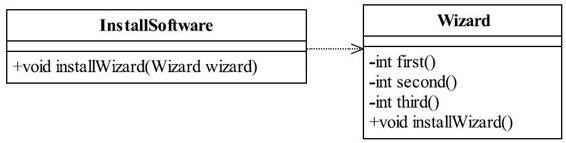
图5-4 重构后的软件安装过程类图
在Wizard类中增加一个installWizard方法,对安装过程进行封装,同时把原有的三个public方法修改为private方法,如代码清单5-11所示。
代码清单5-11 修改后的导向类实现过程
public class Wizard {
private Random rand = new Random(System.currentTimeMillis());
//第一步
private int first(){
System.out.println(“执行第一个方法…”);
return rand.nextInt(100);
}
//第二步
private int second(){
System.out.println(“执行第二个方法…”);
return rand.nextInt(100);
}
//第三个方法
private int third(){
System.out.println(“执行第三个方法…”);
return rand.nextInt(100);
}
//软件安装过程
public void installWizard(){
int first = this.first();
//根据first返回的结果,看是否需要执行second
if(first>50){
int second = this.second();
if(second>50){
int third = this.third();
if(third >50){
this.first();
}
}
}
}
}
将三个步骤的访问权限修改为private,同时把InstallSoftware中的方法installWizad移动到Wizard方法中。通过这样的重构后,Wizard类就只对外公布了一个public方法,即使要修改first方法的返回值,影响的也仅仅只是Wizard本身,其他类不受影响,这显示了类的高内聚特性。
对InstallSoftware类进行少量的修改,如代码清单5-12所示。
代码清单5-12 修改后的InstallSoftware类
public class InstallSoftware {
public void installWizard(Wizard wizard){
//直接调用
wizard.installWizard();
}
}
场景类Client没有任何改变,如代码清单5-10所示。通过进行重构,类间的耦合关系变弱了,结构也清晰了,变更引起的风险也变小了。
一个类公开的public属性或方法越多,修改时涉及的面也就越大,变更引起的风险扩散也就越大。因此,为了保持朋友类间的距离,在设计时需要反复衡量:是否还可以再减少public方法和属性,是否可以修改为private、package-private(包类型,在类、方法、变量前不加访问权限,则默认为包类型)、protected等访问权限,是否可以加上final关键字等。
注意 迪米特法则要求类“羞涩”一点,尽量不要对外公布太多的public方法和非静态的public变量,尽量内敛,多使用private、package-private、protected等访问权限。
- 是自己的就是自己的
在实际应用中经常会出现这样一个方法:放在本类中也可以,放在其他类中也没有错,那怎么去衡量呢?你可以坚持这样一个原则:如果一个方法放在本类中,既不增加类间关系,也对本类不产生负面影响,那就放置在本类中。
- 谨慎使用Serializable
在实际应用中,这个问题是很少出现的,即使出现也会立即被发现并得到解决。是怎么回事呢?举个例子来说,在一个项目中使用RMI(Remote Method Invocation,远程方法调用)方式传递一个VO(Value Object,值对象),这个对象就必须实现Serializable接口(仅仅是一个标志性接口,不需要实现具体的方法),也就是把需要网络传输的对象进行序列化,否则就会出现NotSerializableException异常。突然有一天,客户端的VO修改了一个属性的访问权限,从private变更为public,访问权限扩大了,如果服务器上没有做出相应的变更,就会报序列化失败,就这么简单。但是这个问题的产生应该属于项目管理范畴,一个类或接口在客户端已经变更了,而服务器端却没有同步更新,难道不是项目管理的失职吗?
5.3 最佳实践
迪米特法则的核心观念就是类间解耦,弱耦合,只有弱耦合了以后,类的复用率才可以提高。其要求的结果就是产生了大量的中转或跳转类,导致系统的复杂性提高,同时也为维护带来了难度。读者在采用迪米特法则时需要反复权衡,既做到让结构清晰,又做到高内聚低耦合。
不知道大家有没有听过这样一个理论:“任何两个素不相识的人中间最多只隔着6个人,即只通过6个人就可以将他们联系在一起”,这就是著名的“六度分隔理论”。如果将这个理论应用到我们的项目中,也就是说,我和我要调用的类之间最多有6次传递。呵呵,这只能让大家当个乐子来看,在实际应用中,如果一个类跳转两次以上才能访问到另一个类,就需要想办法进行重构了,为什么是两次以上呢?因为一个系统的成功不仅仅是一个标准或是原则就能够决定的,有非常多的外在因素决定,跳转次数越多,系统越复杂,维护就越困难,所以只要跳转不超过两次都是可以忍受的,这需要具体问题具体分析。
迪米特法则要求类间解耦,但解耦是有限度的,除非是计算机的最小单元——二进制的0和1。那才是完全解耦,在实际的项目中,需要适度地考虑这个原则,别为了套用原则而做项目。原则只是供参考,如果违背了这个原则,项目也未必会失败,这就需要大家在采用原则时反复度量,不遵循是不对的,严格执行就是“过犹不及”。
开闭原则
第6章 开闭原则
6.1 开闭原则的定义
在哲学上,矛盾法则即对立统一的法则,是唯物辩证法的最根本法则。本章要讲的开闭原则是不是也有同样的重要性且具有普遍性呢?确实,开闭原则是Java世界里最基础的设计原则,它指导我们如何建立一个稳定的、灵活的系统,先来看开闭原则的定义:
Software entities like classes,modules and functions should be open for extension but closed for modifications.(一个软件实体如类、模块和函数应该对扩展开放,对修改关闭。)
初看到这个定义,可能会很迷惑,对扩展开放?开放什么?对修改关闭,怎么关闭?没关系,我会一步一步带领大家解开这些疑惑。
我们做一件事情,或者选择一个方向,一般需要经历三个步骤:What——是什么,Why——为什么,How——怎么做(简称3W原则,How取最后一个w)。对于开闭原则,我们也采用这三步来分析,即什么是开闭原则,为什么要使用开闭原则,怎么使用开闭原则。
6.2 开闭原则的庐山真面目
开闭原则的定义已经非常明确地告诉我们:软件实体应该对扩展开放,对修改关闭,其含义是说一个软件实体应该通过扩展来实现变化,而不是通过修改已有的代码来实现变化。那什么又是软件实体呢?软件实体包括以下几个部分:
● 项目或软件产品中按照一定的逻辑规则划分的模块。
● 抽象和类。
● 方法。
一个软件产品只要在生命期内,都会发生变化,既然变化是一个既定的事实,我们就应该在设计时尽量适应这些变化,以提高项目的稳定性和灵活性,真正实现“拥抱变化”。开闭原则告诉我们应尽量通过扩展软件实体的行为来实现变化,而不是通过修改已有的代码来完成变化,它是为软件实体的未来事件而制定的对现行开发设计进行约束的一个原则。我们举例说明什么是开闭原则,以书店销售书籍为例,其类图如图6-1所示。
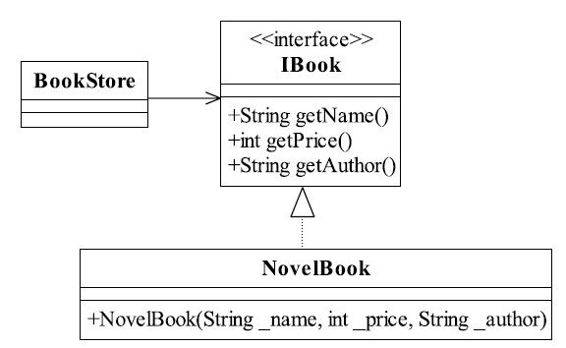
图6-1 书店售书类图
IBook定义了数据的三个属性:名称、价格和作者。小说类NovelBook是一个具体的实现类,是所有小说书籍的总称,BookStore指的是书店,IBook接口如代码清单6-1所示。
代码清单6-1 书籍接口
public interface IBook {
//书籍有名称
public String getName();
//书籍有售价
public int getPrice();
//书籍有作者
public String getAuthor();
}
目前书店只出售小说类书籍,小说类如代码清单6-2所示。
代码清单6-2 小说类
public class NovelBook implements IBook {
//书籍名称
private String name;
//书籍的价格
private int price;
//书籍的作者
private String author;
//通过构造函数传递书籍数据
public NovelBook(String _name,int _price,String _author){
this.name = _name;
this.price = _price;
this.author = _author;
}
//获得作者是谁
public String getAuthor() {
return this.author;
}
//书籍叫什么名字
public String getName() {
return this.name;
}
//获得书籍的价格
public int getPrice() {
return this.price;
}
}
注意 我们把价格定义为int类型并不是错误,在非金融类项目中对货币处理时,一般取2位精度,通常的设计方法是在运算过程中扩大100倍,在需要展示时再缩小100倍,减少精度带来的误差。
书店售书的过程如代码清单6-3所示。
代码清单6-3 书店售书类
public class BookStore {
private final static ArrayList bookList = new ArrayList();
//static静态模块初始化数据,实际项目中一般是由持久层完成
static{
bookList.add(new NovelBook(“天龙八部”,3200,“金庸”));
bookList.add(new NovelBook(“巴黎圣母院”,5600,“雨果”));
bookList.add(new NovelBook(“悲惨世界”,3500,“雨果”));
bookList.add(new NovelBook(“金瓶梅”,4300,“兰陵笑笑生”));
}
//模拟书店买书
public static void main(String[] args) {
NumberFormat formatter = NumberFormat.getCurrencyInstance();
formatter.setMaximumFractionDigits(2);
System.out.println(“-----------书店卖出去的书籍记录如下:-----------”);
for(IBook book:bookList){
System.out.println(“书籍名称:” + book.getName()+“\t书籍作者:” +
book.getAuthor()+“\t书籍价格:”+ formatter.format (book.getPrice()/
100.0)+“元”);
}
}
}
在BookStore中声明了一个静态模块,实现了数据的初始化,这部分应该是从持久层产生的,由持久层框架进行管理,运行结果如下:
-----------------书店卖出去的书籍记录如下:--------------
书籍名称:天龙八部 书籍作者:金庸 书籍价格:¥25.60元
书籍名称:巴黎圣母院 书籍作者:雨果 书籍价格:¥50.40元
书籍名称:悲惨世界 书籍作者:雨果 书籍价格:¥28.00元
书籍名称:金瓶梅 书籍作者:兰陵笑笑生 书籍价格:¥38.70元
项目投产了,书籍正常销售出去,书店也赢利了。从2008年开始,全球经济开始下滑,对零售业影响比较大,书店为了生存开始打折销售:所有40元以上的书籍9折销售,其他的8折销售。对已经投产的项目来说,这就是一个变化,我们应该如何应对这样一个需求变化?有如下三种方法可以解决这个问题:
● 修改接口
在IBook上新增加一个方法getOffPrice(),专门用于进行打折处理,所有的实现类实现该方法。但是这样修改的后果就是,实现类NovelBook要修改,BookStore中的main方法也修改,同时IBook作为接口应该是稳定且可靠的,不应该经常发生变化,否则接口作为契约的作用就失去了效能。因此,该方案否定。
● 修改实现类
修改NovelBook类中的方法,直接在getPrice()中实现打折处理,好办法,我相信大家在项目中经常使用的就是这样的办法,通过class文件替换的方式可以完成部分业务变化(或是缺陷修复)。该方法在项目有明确的章程(团队内约束)或优良的架构设计时,是一个非常优秀的方法,但是该方法还是有缺陷的。例如采购书籍人员也是要看价格的,由于该方法已经实现了打折处理价格,因此采购人员看到的也是打折后的价格,会因信息不对称而出现决策失误的情况。因此,该方案也不是一个最优的方案。
● 通过扩展实现变化
增加一个子类OffNovelBook,覆写getPrice方法,高层次的模块(也就是static静态模块区)通过OffNovelBook类产生新的对象,完成业务变化对系统的最小化开发。好办法,修改也少,风险也小,修改后的类图如图6-2所示。
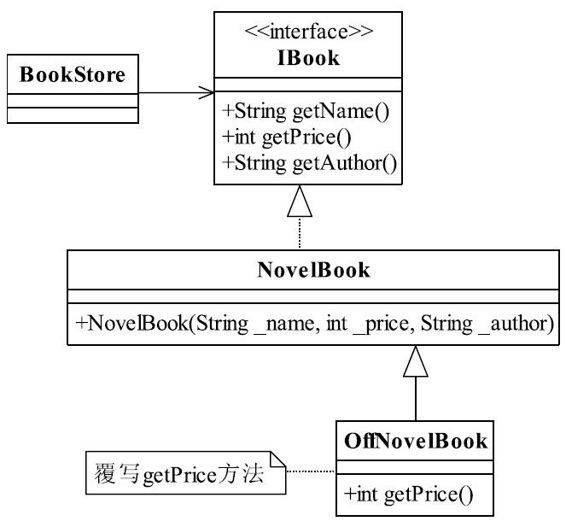
图6-2 扩展后的书店售书类图
OffNovelBook类继承了NovelBook,并覆写了getPrice方法,不修改原有的代码。新增加的子类OffNovelBook如代码清单6-4所示。
代码清单6-4 打折销售的小说类
public class OffNovelBook extends NovelBook {
public OffNovelBook(String _name,int _price,String _author){
super(_name,_price,_author);
}
//覆写销售价格
@Override
public int getPrice(){
//原价
int selfPrice = super.getPrice();
int offPrice=0;
if(selfPrice>4000){ //原价大于40元,则打9折
offPrice = selfPrice * 90 /100;
}else{
offPrice = selfPrice * 80 /100;
}
return offPrice;
}
}
很简单,仅仅覆写了getPrice方法,通过扩展完成了新增加的业务。书店类BookStore需要依赖子类,代码稍作修改,如代码清单6-5所示。
代码清单6-5 书店打折销售类
public class BookStore {
private final static ArrayList bookList = new ArrayList();
//static静态模块初始化数据,实际项目中一般是由持久层完成
static{
bookList.add(new OffNovelBook(“天龙八部”,3200,“金庸”));
bookList.add(new OffNovelBook(“巴黎圣母院”,5600,“雨果”));
bookList.add(new OffNovelBook(“悲惨世界”,3500,“雨果”));
bookList.add(new OffNovelBook(“金瓶梅”,4300,“兰陵笑笑生”));
}
//模拟书店买书
public static void main(String[] args) {
NumberFormat formatter = NumberFormat.getCurrencyInstance();
formatter.setMaximumFractionDigits(2);
System.out.println(“-----------书店卖出去的书籍记录如下:-----------”);
for(IBook book:bookList){
System.out.println(“书籍名称:” + book.getName()+“\t书籍作者:” + book.getAuthor()+ “\t书籍价格:” + formatter.format (book.getPrice()/100.0)+“元”);
}
}
}
我们只修改了粗体部分,其他的部分没有任何改动,运行结果如下所示。
----------------------书店卖出去的书籍记录如下:---------------------
书籍名称:天龙八部 书籍作者:金庸 书籍价格:¥25.60元
书籍名称:巴黎圣母院 书籍作者:雨果 书籍价格:¥50.40元
书籍名称:悲惨世界 书籍作者:雨果 书籍价格:¥28.00元
书籍名称:金瓶梅 书籍作者:兰陵笑笑生 书籍价格:¥38.70元
OK,打折销售开发完成了。看到这里,各位可能有想法了:增加了一个OffNoveBook类后,你的业务逻辑还是修改了,你修改了static静态模块区域。这部分确实修改了,该部分属于高层次的模块,是由持久层产生的,在业务规则改变的情况下高层模块必须有部分改变以适应新业务,改变要尽量地少,防止变化风险的扩散。
注意 开闭原则对扩展开放,对修改关闭,并不意味着不做任何修改,低层模块的变更,必然要有高层模块进行耦合,否则就是一个孤立无意义的代码片段。
我们可以把变化归纳为以下三种类型:
● 逻辑变化
只变化一个逻辑,而不涉及其他模块,比如原有的一个算法是ab+c,现在需要修改为ab*c,可以通过修改原有类中的方法的方式来完成,前提条件是所有依赖或关联类都按照相同的逻辑处理。
● 子模块变化
一个模块变化,会对其他的模块产生影响,特别是一个低层次的模块变化必然引起高层模块的变化,因此在通过扩展完成变化时,高层次的模块修改是必然的,刚刚的书籍打折处理就是类似的处理模块,该部分的变化甚至会引起界面的变化。
● 可见视图变化
可见视图是提供给客户使用的界面,如JSP程序、Swing界面等,该部分的变化一般会引起连锁反应(特别是在国内做项目,做欧美的外包项目一般不会影响太大)。如果仅仅是界面上按钮、文字的重新排布倒是简单,最司空见惯的是业务耦合变化,什么意思呢?一个展示数据的列表,按照原有的需求是6列,突然有一天要增加1列,而且这一列要跨N张表,处理M个逻辑才能展现出来,这样的变化是比较恐怖的,但还是可以通过扩展来完成变化,这就要看我们原有的设计是否灵活。
我们再来回顾一下书店销售书籍的程序,首先是我们有一个还算灵活的设计(不灵活是什么样子?BookStore中所有使用到IBook的地方全部修改为实现类,然后再扩展一个ComputerBook书籍,你就知道什么是不灵活了);然后有一个需求变化,我们通过扩展一个子类拥抱了变化;最后把子类投入运行环境中,新逻辑正式投产。通过分析,我们发现并没有修改原有的模块代码,IBook接口没有改变,NovelBook类没有改变,这属于已有的业务代码,我们保持了历史的纯洁性。放弃修改历史的想法吧,一个项目的基本路径应该是这样的:项目开发、重构、测试、投产、运维,其中的重构可以对原有的设计和代码进行修改,运维尽量减少对原有代码的修改,保持历史代码的纯洁性,提高系统的稳定性。
6.3 为什么要采用开闭原则
每个事物的诞生都有它存在的必要性,存在即合理,那开闭原则的存在也是合理的,为什么这么说呢?
首先,开闭原则非常著名,只要是做面向对象编程的,甭管是什么语言,Java也好,C++也好,或者是Smalltalk,在开发时都会提及开闭原则。
其次,开闭原则是最基础的一个原则,前五章节介绍的原则都是开闭原则的具体形态,也就是说前五个原则就是指导设计的工具和方法,而开闭原则才是其精神领袖。换一个角度来理解,依照Java语言的称谓,开闭原则是抽象类,其他五大原则是具体的实现类,开闭原则在面向对象设计领域中的地位就类似于牛顿第一定律在力学、勾股定律在几何学、质能方程在狭义相对论中的地位,其地位无人能及。
最后,开闭原则是非常重要的,可通过以下几个方面来理解其重要性。
- 开闭原则对测试的影响
所有已经投产的代码都是有意义的,并且都受系统规则的约束,这样的代码都要经过“千锤百炼”的测试过程,不仅保证逻辑是正确的,还要保证苛刻条件(高压力、异常、错误)下不产生“有毒代码”(Poisonous Code),因此有变化提出时,我们就需要考虑一下,原有的健壮代码是否可以不修改,仅仅通过扩展实现变化呢?否则,就需要把原有的测试过程回笼一遍,需要进行单元测试、功能测试、集成测试甚至是验收测试,现在虽然在大力提倡自动化测试工具,但是仍然代替不了人工的测试工作。
以上面提到的书店售书为例,IBook接口写完了,实现类NovelBook也写好了,我们需要写一个测试类进行测试,测试类如代码清单6-6所示。
代码清单6-6 小说类的单元测试
public class NovelBookTest extends TestCase {
private String name = “平凡的世界”;
private int price = 6000;
private String author = “路遥”;
private IBook novelBook = new NovelBook(name,price,author);
//测试getPrice方法
public void testGetPrice() {
//原价销售,根据输入和输出的值是否相等进行断言
super.assertEquals(this.price, this.novelBook.getPrice());
}
}
单元测试通过,显示绿条。在单元测试中,有一句非常有名的话,叫做"Keep the bar green to keep the code clean",即保持绿条有利于代码整洁,这是什么意思呢?绿条就是Junit运行的两种结果中的一种:要么是红条,单元测试失败;要么是绿条,单元测试通过。一个方法的测试方法一般不少于3种,为什么呢?首先是正常的业务逻辑要保证测试到,其次是边界条件要测试到,然后是异常要测试到,比较重要的方法的测试方法甚至有十多种,而且单元测试是对类的测试,类中的方法耦合是允许的,在这样的条件下,如果再想着通过修改一个方法或多个方法代码来完成变化,基本上就是痴人说梦,该类的所有测试方法都要重构,想象一下你在一堆你并不熟悉的代码中进行重构时的感觉吧!
在书店售书的例子中,增加了一个打折销售的需求,如果我们直接修改getPrice方法来实现业务需求的变化,那就要修改单元测试类。想想看,我们举的这个例子是非常简单的,如果是一个复杂的逻辑,你的测试类就要修改得面目全非。还有,在实际的项目中,一个类一般只有一个测试类,其中可以有很多的测试方法,在一堆本来就很复杂的断言中进行大量修改,难免会出现测试遗漏情况,这是项目经理很难容忍的事情。
所以,我们需要通过扩展来实现业务逻辑的变化,而不是修改。上面的例子中通过增加一个子类OffNovelBook来完成了业务需求的变化,这对测试有什么好处呢?我们重新生成一个测试文件OffNovelBookTest,然后对getPrice进行测试,单元测试是孤立测试,只要保证我提供的方法正确就成了,其他的我不管,OffNovelBookTest如代码清单6-7所示。
代码清单6-7 打折销售的小说类单元测试
public class OffNovelBookTest extends TestCase {
private IBook below40NovelBook = new OffNovelBook(“平凡的世界”,3000,“路遥”);
private IBook above40NovelBook = new OffNovelBook(“平凡的世界”,6000,“路遥”);
//测试低于40元的数据是否是打8折
public void testGetPriceBelow40() {
super.assertEquals(2400, this.below40NovelBook.getPrice());
}
//测试大于40的书籍是否是打9折
public void testGetPriceAbove40(){
super.assertEquals(5400, this.above40NovelBook.getPrice());
}
}
新增加的类,新增加的测试方法,只要保证新增加类是正确的就可以了。
- 开闭原则可以提高复用性
在面向对象的设计中,所有的逻辑都是从原子逻辑组合而来的,而不是在一个类中独立实现一个业务逻辑。只有这样代码才可以复用,粒度越小,被复用的可能性就越大。那为什么要复用呢?减少代码量,避免相同的逻辑分散在多个角落,避免日后的维护人员为了修改一个微小的缺陷或增加新功能而要在整个项目中到处查找相关的代码,然后发出对开发人员“极度失望”的感慨。那怎么才能提高复用率呢?缩小逻辑粒度,直到一个逻辑不可再拆分为止。
- 开闭原则可以提高可维护性
一款软件投产后,维护人员的工作不仅仅是对数据进行维护,还可能要对程序进行扩展,维护人员最乐意做的事情就是扩展一个类,而不是修改一个类,甭管原有的代码写得多么优秀还是多么糟糕,让维护人员读懂原有的代码,然后再修改,是一件很痛苦的事情,不要让他在原有的代码海洋里游弋完毕后再修改,那是对维护人员的一种折磨和摧残。
- 面向对象开发的要求
万物皆对象,我们需要把所有的事物都抽象成对象,然后针对对象进行操作,但是万物皆运动,有运动就有变化,有变化就要有策略去应对,怎么快速应对呢?这就需要在设计之初考虑到所有可能变化的因素,然后留下接口,等待“可能”转变为“现实”。
6.4 如何使用开闭原则
开闭原则是一个非常虚的原则,前面5个原则是对开闭原则的具体解释,但是开闭原则并不局限于这么多,它“虚”得没有边界,就像“好好学习,天天向上”的口号一样,告诉我们要好好学习,但是学什么,怎么学并没有告诉我们,需要去体会和掌握,开闭原则也是一个口号,那我们怎么把这个口号应用到实际工作中呢?
- 抽象约束
抽象是对一组事物的通用描述,没有具体的实现,也就表示它可以有非常多的可能性,可以跟随需求的变化而变化。因此,通过接口或抽象类可以约束一组可能变化的行为,并且能够实现对扩展开放,其包含三层含义:第一,通过接口或抽象类约束扩展,对扩展进行边界限定,不允许出现在接口或抽象类中不存在的public方法;第二,参数类型、引用对象尽量使用接口或者抽象类,而不是实现类;第三,抽象层尽量保持稳定,一旦确定即不允许修改。还是以书店为例,目前只是销售小说类书籍,单一经营毕竟是有风险的,于是书店新增加了计算机书籍,它不仅包含书籍名称、作者、价格等信息,还有一个独特的属性:面向的是什么领域,也就是它的范围,比如是和编程语言相关的,还是和数据库相关的,等等,修改后的类图如图6-3所示。
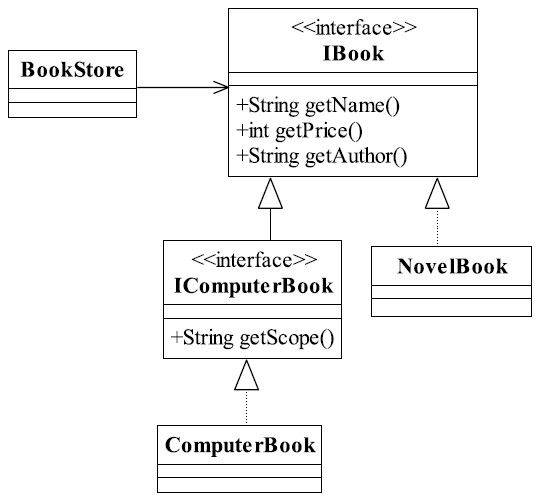
图6-3 增加业务品种后的书店售书类图
增加了一个接口IComputerBook和实现类Computer- Book,而BookStore不用做任何修改就可以完成书店销售计算机书籍的业务。计算机书籍接口如代码清单6-8所示。
代码清单6-8 计算机书籍接口
public interface IComputerBook extends IBook{
//计算机书籍是有一个范围
public String getScope();
}
很简单,计算机书籍增加了一个方法,就是获得该书籍的范围,同时继承IBook接口,毕竟计算机书籍也是书籍,其实现如代码清单6-9所示。
代码清单6-9 计算机书籍类
public class ComputerBook implements IComputerBook {
private String name;
private String scope;
private String author;
private int price;
public ComputerBook(String _name,int _price,String _author,String _scope){
this.name=_name;
this.price = _price;
this.author = _author;
this.scope = _scope;
}
public String getScope() {
return this.scope;
}
public String getAuthor() {
return this.author;
}
public String getName() {
return this.name;
}
public int getPrice() {
return this.price;
}
}
这也很简单,实现IComputerBook就可以,而BookStore类没有做任何的修改,只是在static静态模块中增加一条数据,如代码清单6-10所示。
代码清单6-10 书店销售计算机书籍
public class BookStore {
private final static ArrayList bookList = new ArrayList();
//static静态模块初始化数据,实际项目中一般是由持久层完成
static{
bookList.add(new NovelBook(“天龙八部”,3200,“金庸”));
bookList.add(new NovelBook(“巴黎圣母院”,5600,“雨果”));
bookList.add(new NovelBook(“悲惨世界”,3500,“雨果”));
bookList.add(new NovelBook(“金瓶梅”,4300,“兰陵笑笑生”));
//增加计算机书籍
bookList.add(new ComputerBook(“Think in Java”,4300,“Bruce Eckel”,“编程语言”));
}
//模拟书店卖书
public static void main(String[] args) {
NumberFormat formatter = NumberFormat.getCurrencyInstance();
formatter.setMaximumFractionDigits(2);
System.out.println(“-----------书店卖出去的书籍记录如下:-----------”);
for(IBook book:bookList){
System.out.println(“书籍名称:” + book.getName()+“\t书籍作者:” + book.getAuthor()+ “\t书籍价格:” + formatter.format (book.getPrice()/100.0)+“元”);
}
}
}
书店开始销售计算机书籍,运行结果如下所示。
--------------------书店卖出去的书籍记录如下:---------------------
书籍名称:天龙八部 书籍作者:金庸 书籍价格:¥32.00元
书籍名称:巴黎圣母院 书籍作者:雨果 书籍价格:¥56.00元
书籍名称:悲惨世界 书籍作者:雨果 书籍价格:¥35.00元
书籍名称:金瓶梅 书籍作者:兰陵笑笑生 书籍价格:¥43.00元
书籍名称:Think in Java 书籍作者:Bruce Eckel 书籍价格:¥43.00元
如果我是负责维护的,我就非常乐意做这样的事情,简单而且不需要与其他的业务进行耦合。我唯一需要做的事情就是在原有的代码上添砖加瓦,然后就可以实现业务的变化。我们来看看这段代码有哪几层含义。
首先,ComputerBook类必须实现IBook的三个方法,是通过IComputerBook接口传递进来的约束,也就是我们制定的IBook接口对扩展类ComputerBook产生了约束力,正是由于该约束力,BookStore类才不需要进行大量的修改。
其次,如果原有的程序设计采用的不是接口,而是实现类,那会出现什么问题呢?我们把 BookStore类中的私有变量bookList修改一下,如下面的代码所示。
private final static ArrayList bookList = new ArrayList();
把原有IBook的依赖修改为对NovelBook实现类的依赖,想想看,我们这次的扩展是否还能继续下去呢?一旦这样设计,我们就根本没有办法扩展,需要修改原有的业务逻辑(也就是main方法),这样的扩展基本上就是形同虚设。
最后,如果我们在IBook上增加一个方法getScope,是否可以呢?答案是不可以,因为原有的实现类NovelBook已经在投产运行中,它不需要该方法,而且接口是与其他模块交流的契约,修改契约就等于让其他模块修改。因此,接口或抽象类一旦定义,就应该立即执行,不能有修改接口的思想,除非是彻底的大返工。
所以,要实现对扩展开放,首要的前提条件就是抽象约束。
- 元数据(metadata)控制模块行为
编程是一个很苦很累的活,那怎么才能减轻我们的压力呢?答案是尽量使用元数据来控制程序的行为,减少重复开发。什么是元数据?用来描述环境和数据的数据,通俗地说就是配置参数,参数可以从文件中获得,也可以从数据库中获得。举个非常简单的例子,login方法中提供了这样的逻辑:先检查IP地址是否在允许访问的列表中,然后再决定是否需要到数据库中验证密码(如果采用SSH架构,则可以通过Struts的拦截器来实现),该行为就是一个典型的元数据控制模块行为的例子,其中达到极致的就是控制反转(Inversion of Control),使用最多的就是Spring容器,在SpringContext配置文件中,基本配置如代码清单6-11所示。
代码清单6-11 SpringContext的基本配置文件
然后,通过建立一个Father类的子类Son,完成一个新的业务,同时修改SpringContext文件,修改后的文件如代码清单6-12所示。
代码清单6-12 扩展后的SpringContext配置文件
通过扩展一个子类,修改配置文件,完成了业务变化,这也是采用框架的好处。
- 制定项目章程
在一个团队中,建立项目章程是非常重要的,因为章程中指定了所有人员都必须遵守的约定,对项目来说,约定优于配置。相信大家都做过项目,会发现一个项目会产生非常多的配置文件。举个简单的例子,以SSH项目开发为例,一个项目中的Bean配置文件就非常多,管理非常麻烦。如果需要扩展,就需要增加子类,并修改SpringContext文件。然而,如果你在项目中指定这样一个章程:所有的Bean都自动注入,使用Annotation进行装配,进行扩展时,甚至只用写一个子类,然后由持久层生成对象,其他的都不需要修改,这就需要项目内约束,每个项目成员都必须遵守,该方法需要一个团队有较高的自觉性,需要一个较长时间的磨合,一旦项目成员都熟悉这样的规则,比通过接口或抽象类进行约束效率更高,而且扩展性一点也没有减少。
- 封装变化
对变化的封装包含两层含义:第一,将相同的变化封装到一个接口或抽象类中;第二,将不同的变化封装到不同的接口或抽象类中,不应该有两个不同的变化出现在同一个接口或抽象类中。封装变化,也就是受保护的变化(protected variations),找出预计有变化或不稳定的点,我们为这些变化点创建稳定的接口,准确地讲是封装可能发生的变化,一旦预测到或“第六感”发觉有变化,就可以进行封装,23个设计模式都是从各个不同的角度对变化进行封装的,我们会在各个模式中逐步讲解。
6.5 最佳实践
软件设计最大的难题就是应对需求的变化,但是纷繁复杂的需求变化又是不可预料的。我们要为不可预料的事情做好准备,这本身就是一件非常痛苦的事情,但是大师们还是给我们提出了非常好的6大设计原则以及23个设计模式来“封装”未来的变化,我们在前5章中讲过如下设计原则。
● Single Responsibility Principle:单一职责原则
● Open Closed Principle:开闭原则
● Liskov Substitution Principle:里氏替换原则
● Law of Demeter:迪米特法则
● Interface Segregation Principle:接口隔离原则
● Dependence Inversion Principle:依赖倒置原则
把这6个原则的首字母(里氏替换原则和迪米特法则的首字母重复,只取一个)联合起来就是SOLID(solid,稳定的),其代表的含义也就是把这6个原则结合使用的好处:建立稳定、灵活、健壮的设计,而开闭原则又是重中之重,是最基础的原则,是其他5大原则的精神领袖。我们在使用开闭原则时要注意以下几个问题。
● 开闭原则也只是一个原则
开闭原则只是精神口号,实现拥抱变化的方法非常多,并不局限于这6大设计原则,但是遵循这6大设计原则基本上可以应对大多数变化。因此,我们在项目中应尽量采用这6大原则,适当时候可以进行扩充,例如通过类文件替换的方式完全可以解决系统中的一些缺陷。大家在开发中比较常用的修复缺陷的方法就是类替换,比如一个软件产品已经在运行中,发现了一个缺陷,需要修正怎么办?如果有自动更新功能,则可以下载一个.class文件直接覆盖原有的class,重新启动应用(也不一定非要重新启动)就可以解决问题,也就是通过类文件的替换方式修正了一个缺陷,当然这种方式也可以应用到项目中,正在运行中的项目发现需要增加一个新功能,通过修改原有实现类的方式就可以解决这个问题,前提条件是:类必须做到高内聚、低耦合,否则类文件的替换会引起不可预料的故障。
● 项目规章非常重要
如果你是一位项目经理或架构师,应尽量让自己的项目成员稳定,稳定后才能建立高效的团队文化,章程是一个团队所有成员共同的知识结晶,也是所有成员必须遵守的约定。优秀的章程能带给项目带来非常多的好处,如提高开发效率、降低缺陷率、提高团队士气、提高技术成员水平,等等。
● 预知变化
在实践中过程中,架构师或项目经理一旦发现有发生变化的可能,或者变化曾经发生过,则需要考虑现有的架构是否可以轻松地实现这一变化。架构师设计一套系统不仅要符合现有的需求,还要适应可能发生的变化,这才是一个优良的架构。
开闭原则是一个终极目标,任何人包括大师级人物都无法百分之百做到,但朝这个方向努力,可以非常显著地改善一个系统的架构,真正做到“拥抱变化”。