Linux进程控制详解.
🧸🧸🧸各位大佬大家好,我是猪皮兄弟🧸🧸🧸

文章目录
- 一、进程创建
- 1.创建子进程,OS做的事
- 2.写时拷贝
- 3.上下文数据
- 4.fork调用失败的原因
- 二、进程终止
- 1.main函数的返回值
- 2.strerror
- exit && _exit
- exit
- _exit
- 区别
- 三、进程等待
- 1.wait
- 2.waipid
- 3.wait/waitpid凭什么拿到子进程退出码
- 4. waitpid参数构成
- 5.阻塞等待&&非阻塞等待
- 四、进程程序替换
- 1.进程程序替换操作 exec系列函数
- execl
- 不创建子进程
- 创建子进程
- execv
- execlp
- execle
- 2.如何替换我自己写的程序
- 3.execve
一、进程创建
#include <unistd.h>
pid_t id = fork();
1.创建子进程,OS做的事
进程=内核数据结构+进程数据和代码
- 分配新的内存块和数据结构给子进程
- 将父进程部分数据和内容进行拷贝
- 添加子进程到系统进程列表
- fork()返回,开始调度器调度
理论上,子进程也要拥有自己的代码和数据,但是一般而言,子进程没有 加载的过程,所以,子进程没有自己的代码和数据,只有靠父进程
2.写时拷贝
代码是不可被写的,只能读取,所以父子可以共享
数据是可被修改的,所以必须分开(修改的时候才进行)
如果说创建进程的时候,就直接拷贝父进程的数据,那么可能子进程根本不会去用或者只是去读取,浪费空间。
1.因为即便是OS也无法提前知道哪些空间会被提前写入,所以无法提前拷贝会被写入的那些空间
2.提前拷贝了,会立马使用吗?
所以OS选择了写时拷贝技术来实现父子进程数据的分离
1.用的时候再分配是高效使用内存的表现
2.操作系统无法预知被访问的空间
因为有写时拷贝的存在,所以,父子进程得以彻底分开,保证了进程的独立性。写时拷贝是一种延迟申请的技术,可以提高整机内存的使用率。
3.上下文数据
创建子进程之后,父子进程是所有代码共享的(不仅仅是fork()之后的代码)
进程随时可能被中断,下次回来因为必须从之前的位置继续执行,就要求CPU随时记录当前进程执行的位置,所以,CPU内由对应的寄存器数据,用来记录当前进程的执行位置,这个寄存器叫EIP(也叫做PC,程序计数器),记录的是下一条执行的代码,还有其他寄存器来记录其他状态,这些寄存器中的数据,我们叫做进程的上下文数据,创建的时候,上下文数据也是要给子进程的,所以这是的执行状态,父子进程相同,才觉得子进程只有fork()之下的代码,其实是全部代码
4.fork调用失败的原因
1.系统中已经有太多的进程
2.实际用户的进程数超过了限制(一般的用户不会允许创建太多的进程)
二、进程终止
进程终止,OS释放进程申请的相关内核数据结构和对应的代码和数据
进程终止的常见方式
a.代码跑完,结果正确
b.代码跑完,结果不正确
c.代码没有跑完,程序崩溃
1.main函数的返回值
main函数的返回值我们总是写为return 0;但是其实他是有意义的,main函数的返回值并不总是0,可以是其他值,main函数的返回值叫做进程退出码,如果进程退出码为0(success),表示代码结果是正确的,不正确就是非0,main的返回值是用来返回给上一级进程的,用来评判该进程执行结果用的,我们可以忽略
echo $? 来查看最近一次进程执行完毕之后的退出码

由上所述,直接返回0其实是不对的,应该对于函数中的执行结果设计不同的返回值,通过进程退出码来判定main函数执行结果的正确性(非零值有无数个,不同的非零值就可以表示不同的原因,方便定位错误的原因细节)
2.strerror
将进程退出码的含义进行打印
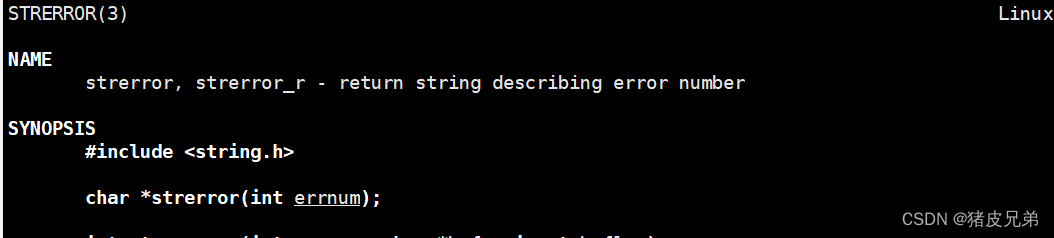
printf(strerror(num));
//用这个来查看每个进程退出码所代表的函数,写个for循环
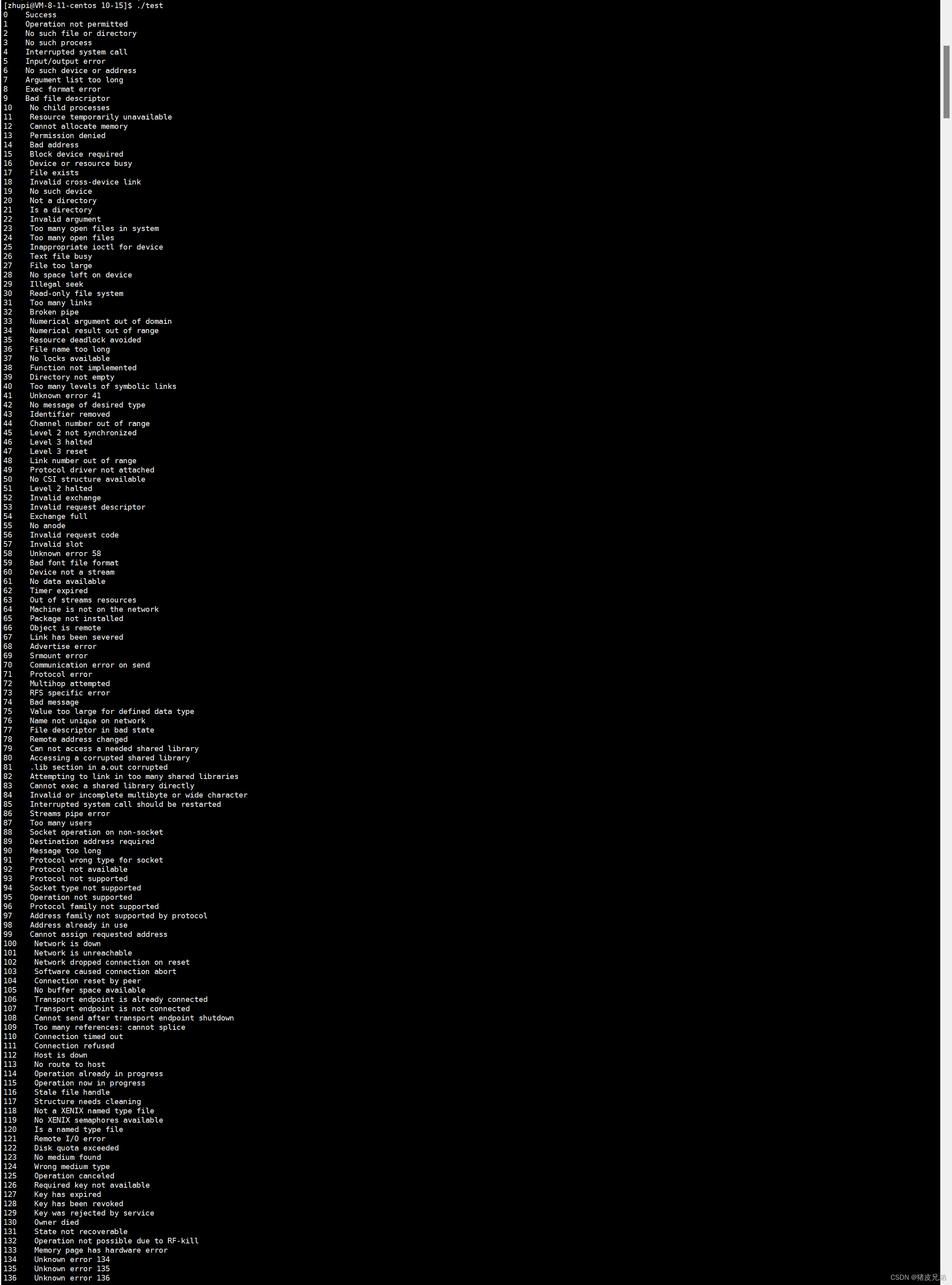
程序崩溃的时候,退出码无意义!因为退出码对应的return没有执行
exit && _exit
exit
a.return语句,就是终止进程的,但是只有在main函数才是终止进程,其他函数是 函数返回。
b.exit
#include <stdlib.h>
int exit(int status)
引起正常进程终止,能达到和return一样的效果,但是,exit在任何地方都可以调用,都表示终止进程,所以,如果想终止进程,推荐用exit
_exit
除了exit外,还有_exit,这是一个系统调用接口

区别
exit:是一个库函数
1.执行用户定义的清理函数
2.冲刷缓冲,关闭流等
3.进程退出
_exit:是一个系统调用
直接进程退出
这里也可以看出来,缓冲区不再操作系统内部,另外,缓冲区是C标准库维护的
三、进程等待
1.wait
等待进程状态变化,wait是阻塞式的等,一直等到子进程状态变化
#include <sys/types.h>
#include <sys/wait.h>
pid_t wait(int*status)
//status:输出型参数,不关心子进程退出结果则status为NULL
// 关心子进程退出结果则status为&status
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/wait.h>
int main()
{
pid_t id = fork();
if(id<0)
{
perror("fork");
exit(1);//退出码为1,不正确
}
else if(id==0)
{
int cnt=5;
while(cnt)
{
printf("cnt: %d,im child process: pid:%d, ppid:%d\n",
cnt,getpid(),getppid());
sleep(1);
cnt--;
}
exit(0);
}
else
{
//父
printf("im parent process:pid:%d, ppid:%d\n",
getpid(),getppid());
sleep(7);
pid_t ret =wait(NULL);
if(ret>0)
{
printf("等待子进程成功,ret:,%d\n",ret);
}
while(1)
{
printf("im parent process: pid:%d,ppid:%d\n",
getpid(),getppid());
sleep(1);
}
}
return 0;
}
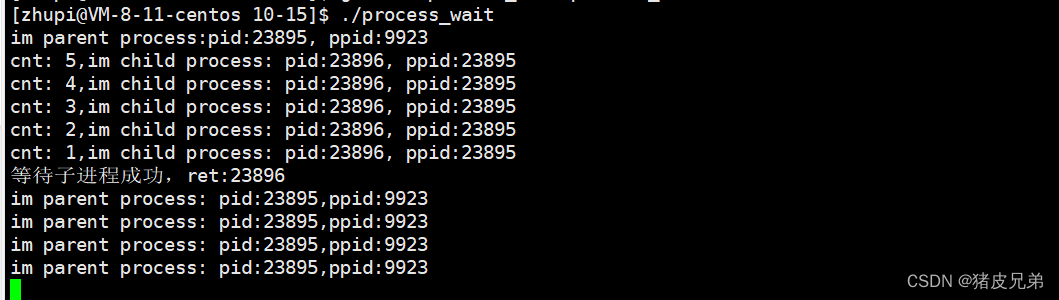
可以看出,父进程一直在等,直到子进程有了结果才继续运行
2.waipid
#include <sys/types.h>
#include <sys/wait.h>
pid_t waitpid(pid_t pid,int*status,int options);
//pid =-1,等任意一个子进程
//waitpid(pid,NULL,0) 等于 wait(NULL)
//pid>0,等待进程ID与pid相等的子进程
//options默认为0,表示阻塞等待
//status:输出型参数,不关心子进程退出结果则status为NULL
// 关心子进程退出结果则status为&status
status的构成
status并不是按照整数来整体使用的,而是按照bit位的方式,将32个比特位进行划分,只需要知道 低16位即可
我们kill -l知道 是没有0号信号的
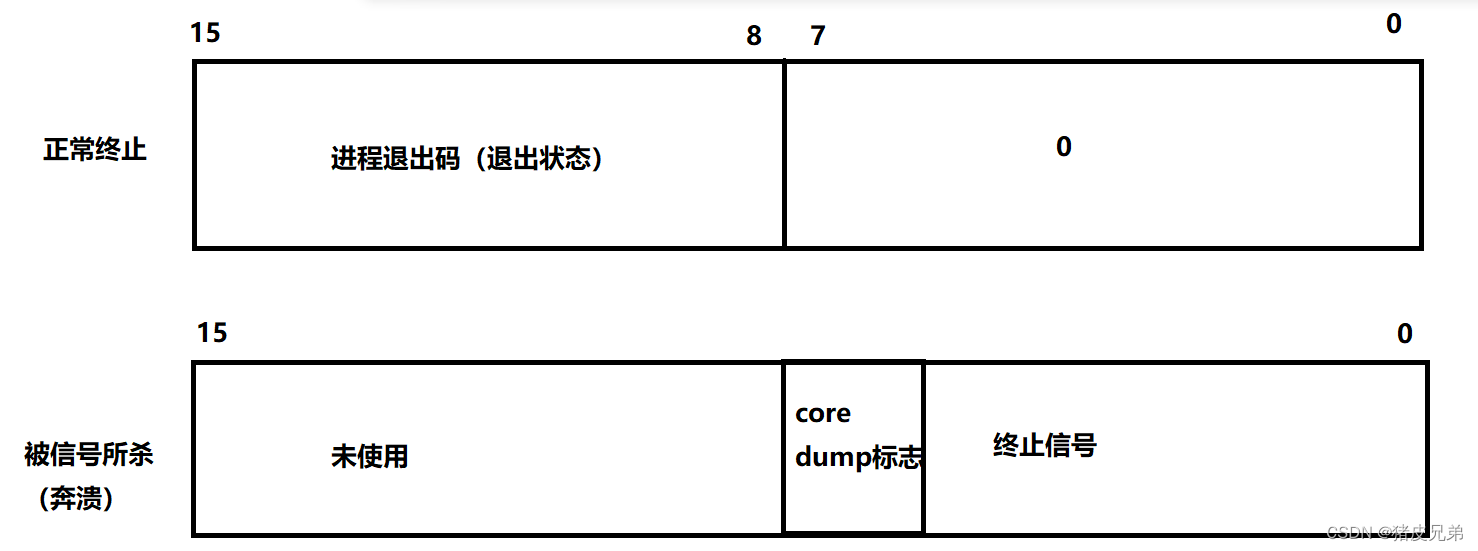
进程异常退出 就是操纵系统以发送信号的方式杀掉了该进程
status的低7位是表示进程收到的信号(无0信号,0说明 是正常跑完的,运行期间没有收到信号)
status的次低8位才是子进程退出码(异常退出进程退出码无意义)
(status>>8)&OxFF//第八位,F要用四个bit位来表示(1111),所以低八位&0xFF
int status;
pid_t ret = waitpid(id,&status,0);
printf("等待子进程成功,ret:%d,子进程退出码:%d \n",ret,(status>>8)&0xFF);
//ret是wait/waitpid的返回值,正常退出进程退出码才有意义,程序崩溃的话进程退出码
//是没有意义的。
3.wait/waitpid凭什么拿到子进程退出码
僵尸进程:是一个已死的进程,可以释放数据,至少要保留该进程的PCB信息,task_struct里面保留了任何进程退出时的退出信息,wait/waitpid就是读取子进程的task_struct结构。
//内核源代码task_struct中我们可以看到两个字段
int exit_code,exit_signal;//退出码和退出信号
task_strcut是内核数据结构,而wait/waitpid是系统调用,当然有权力读取到
4. waitpid参数构成
1.pid
id>0:等待指定进程退出
id==-1:等待任意进程退出
(wait其实是waitpid的子集)
pid_t ret = wait(NULL);
pid_t ret = wait(id/*子进程pid,创建子进程时的返回值*/,NULL,0/*阻塞等待*/);
2.status
对于status来说,还要自己去位运算,是不是太麻烦了,所以系统提供了宏
WIFEXITED(statis)查看进程是否正常退出
WEXITSTATUS(status)查看进程的退出码
3.options
默认是0,是阻塞等待
阻塞的时候,父进程是什么都不敢的,如果想让他做点事呢?所以 可以将options设置为WNOHUNG,父进程就是非阻塞等待
5.阻塞等待&&非阻塞等待
阻塞等待,父进程后面的代码不执行,当条件满足的时候,EIP寄存器(PC指针)指向的下一行代码开始唤醒。
非阻塞等待如果父进程检测子进程的退出状态,发现子进程没有退出,通过调用waitpid来等待,如果子进程没有退出,waitpid立马返回(阻塞等待在等待完成后才返回)
非阻塞等待,标志位是WNOHANG(宏),子进程没退出就直接return,直接后面的代码,通过 多次调用waitpid来完成(基于非阻塞调用的轮询检测方案),面对IO的东西太多,用阻塞等待的话,系统就太慢了
四、进程程序替换
子进程不想和父进程共享代码,想执行一段自己的代码–>进程程序替换
程序替换是通过特定的机构,加载磁盘上的一个全新的程序(数据和代码),加载到调用进程的地址空间中
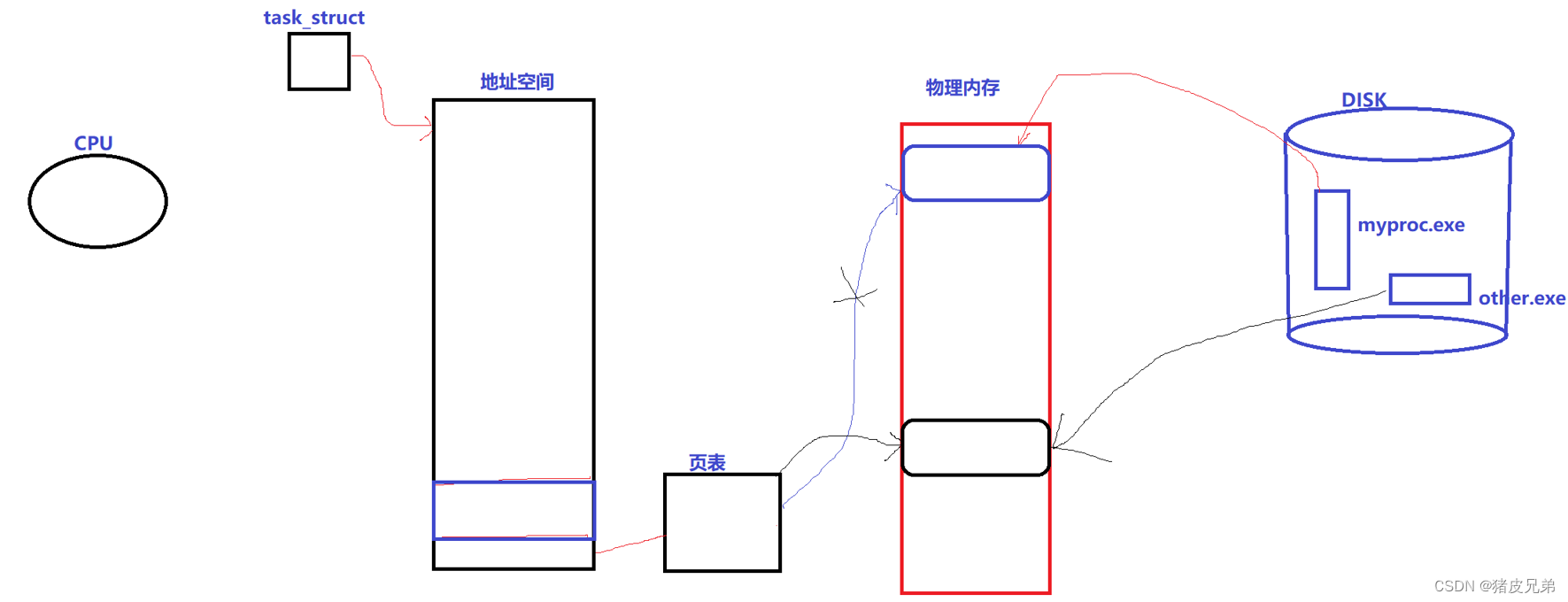
1.进程程序替换操作 exec系列函数
execl
int execl(const char*path,const char*arg,...);
//可以想象成list,传参的时候传一串
第一个参数是找到程序
后面是可变参数列表,命令行上怎么执行,这里就怎么填
并且最后一个参数必须以NULL结尾,表示参数传递完毕
不创建子进程

int main()
{
printf("当前进程的开始代码\n");
//execl("/usr/bin/ls","ls","-l","-a",NULL);
execl("/usr/bin/top","top",NULL);
printf("当前进程的结束代码\n");
}
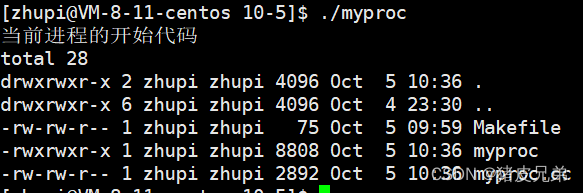
可以看到代码已经被替换,后面的代码不再执行

ls是带自由配色选项的,我们也可以加上这个选项 --color=auto
创建子进程
创建子进程 ,我们就可以替换子进程而不影响父进程(进程具有独立性)。我能需要让父进程聚焦在读取数据,解析数据,指派进程执行代码(子进程)的功能上
execv
int execv()const char*path,char*const argv[]);
//可以想象成vector
execl和execv本质上没有区别,只是在传参方式上有所不同
#define NUM 16
...
char*const _argv[NUM]={"ls","-a","-l",NULL};
...
execv("/usr/bin/ls",_argv);
execlp
int execlp(const char*file,const char*arg,...);
exec系列函数,命名中带p的就是在环境中PATH中进行查找
execlp("ls"/*在Path中找到ls*/,"ls","-a","-l",NULL);
execle
int execle(const char*path,const char*arg,...,char*const envp[]);
//e表示环境变量,最后这个参数不传也是允许的
#define NUM 16
char*_env[NUM]={(char*)"MY_VAL=888777666555","NULL"};
execle(path,参数,参数...,_env/*可不传*/);
2.如何替换我自己写的程序
const char*mypath = "XXX路径";
//可以从工作目录开始,也可以从当前目录开始
...
execl("mypath","mycmd"/*自己写的程序*/,"-a"NULL);
//-a参数,main是可以接收参数的
3.execve
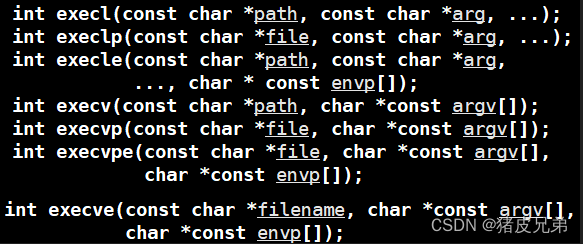
上面6个exec系列函数底层是调用的同一个接口,为了满足不同的调用场景而实现了不同的封装,execve才是真正的系统调用接口
