注意力机制以及实现
文章目录
- 通道注意力机制 ChannelAttention
- SE模块 代码1
- SE模块代码2
- 通道注意力模块代码
- 空间注意力机制 SpatialAttention
- 代码:
- CBAM
- 代码:
- Resnet_CBAM
- 代码
通道注意力机制 ChannelAttention
通道注意力最早由SENet提出。
显式地建模特征通道之间的相互依赖关系,让网络自动学习每个通道的重要程度,然后按照这个重要程度提升有用的特征,抑制无用的特征(特征重标定策略)。
主要结构如图所示:
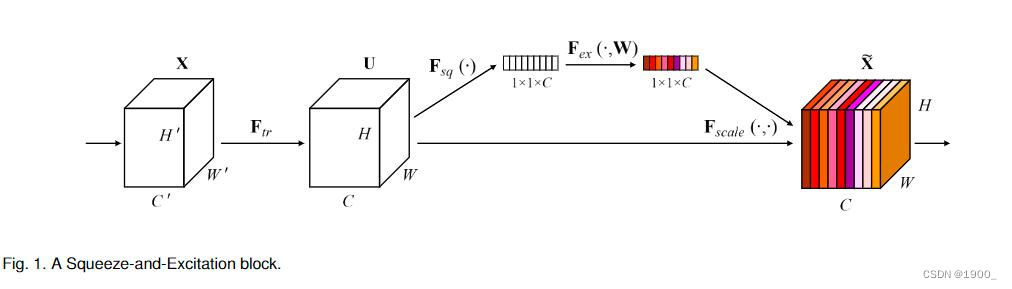 将特征图先进行按通道压缩,比如特征图是[C,H,W],我们用1x1卷积核做平均池化,将每个通道都压缩为一个数字,就得到了[C,1,1]大小的一个向量,然后用一个全连接层,将其压缩一下,压缩倍率是超参数,自己定,假设压缩四倍,就得到了[C/4,1,1]。压缩完了之后,再用一个全连接层将通道数再扩到到原来的大小[C,1,1],然后再经过一个sigmoid映射。最后,将得到的权重通过乘法逐通道加权到先前的特征上。就是每个通道的值去乘以二维特征图的对应通道。(比如第三通道是0.5,那么特征图的第三通道上的HxW个数全部乘以0.5)
将特征图先进行按通道压缩,比如特征图是[C,H,W],我们用1x1卷积核做平均池化,将每个通道都压缩为一个数字,就得到了[C,1,1]大小的一个向量,然后用一个全连接层,将其压缩一下,压缩倍率是超参数,自己定,假设压缩四倍,就得到了[C/4,1,1]。压缩完了之后,再用一个全连接层将通道数再扩到到原来的大小[C,1,1],然后再经过一个sigmoid映射。最后,将得到的权重通过乘法逐通道加权到先前的特征上。就是每个通道的值去乘以二维特征图的对应通道。(比如第三通道是0.5,那么特征图的第三通道上的HxW个数全部乘以0.5)
- 这个先压缩,再升维的过程中,使用全连接层,为每个二维的特征图生成一个权重,这个权重用来显示的声明当前通道的重要性。这就是通道注意力的核心。
- 我们可以用1x1的卷积代替全连接层来做。
SE模块的代码如下:
参考链接:https://blog.csdn.net/qq_44173974/article/details/126016859
SE模块 代码1
# 使用1*1的卷积代替全连接层 避免了tensor维度的额外处理
class SELayer2(nn.Layer):
def __init__(self,in_channels,reduction=16):
super(SELayer2, self).__init__()
self.squeeze =nn.AdaptiveAvgPool2D(1) # 池化(按通道压缩)
self.excitation=nn.Sequential(
nn.Conv2D(in_channels, in_channels // reduction, 1, 1, 0), # 压缩
nn.ReLU(),
nn.Conv2D(in_channels // reduction, in_channels, 1, 1, 0), # 恢复
nn.Sigmoid()
)
def forward(self,x):
# x:[n,c,h,w]
y=self.squeeze(x)
y=self.excitation(x)
out=x*y # 将权重逐通道加权到先前的特征上
return out
SE模块代码2
class SeModule(nn.Module):
def __init__(self, in_size, reduction=4):
super(SeModule, self).__init__()
self.se = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(in_size, in_size // reduction, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(in_size // reduction),
nn.PReLU(in_size//reduction),
nn.Conv2d(in_size // reduction, in_size, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(in_size),
nn.PReLU(in_size)
)
def forward(self, x):
return x * self.se(x)
当然SE模块里面就只做了平均池化,后面有提出新的改动
ECCV2018年的Convolutional Block Attention Module,简称CBAM模块
这个论文提出的模块是将通道注意力和空间注意力结合在一起了。
论文中使用的通道注意力结构如图所示:
跟SE模块改动不大,就是平均池化和最大池化一起做
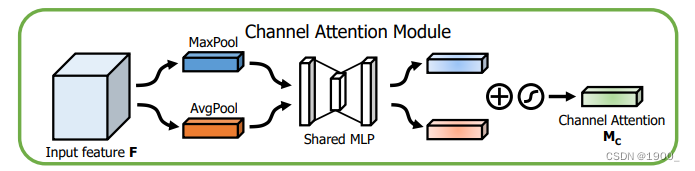
代码如下:
通道注意力模块代码
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
空间注意力机制 SpatialAttention
空间注意力机制是关注空间信息,为空间位置建立权重信息。如图所示:
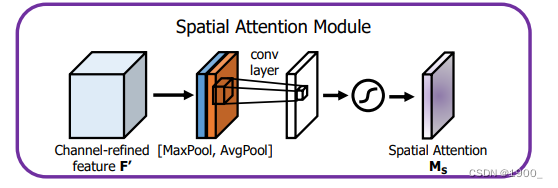
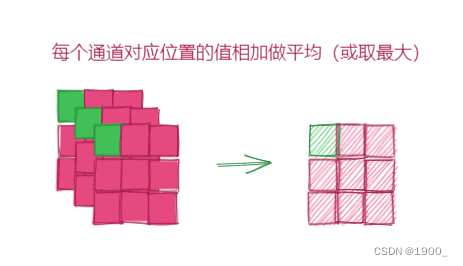
也很简单,比如你有特征图[C,H,W],首先按照通道压缩,每个通道对应位置的值相加,取平均,最后压缩得到一个[1,H,W]的特征图,这是平均池化的结果,再做一个最大池化,再得到一个[1,H,W]的特征图,将两个拼接起来,就是[2,H,W],然后送进一个卷积层里面去学习,最后进行一个sigmoid输出。得到的这个[1,H,W]把他对应乘到原来的特征上去。这就是空间注意力
代码:
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3,7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out,_ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
CBAM
Convolutional Block Attention Module
CBAM就是将通道注意力和空间注意力融合在一起
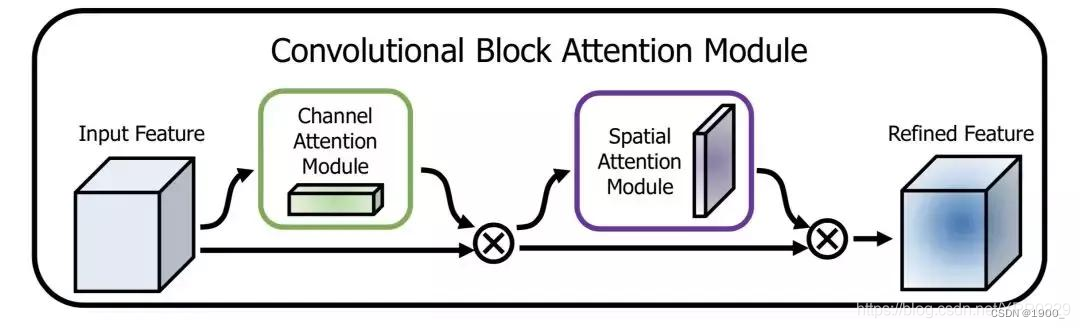
代码:
class CBAM(nn.Module):
def __init__(self, inplanes, ratio=16, kernel_size=7):
super(CBAM, self).__init__()
self.ca = ChannelAttention(inplanes, ratio)
self.sa = SpatialAttention(kernel_size)
def forward(self, x):
out = x*self.ca(x)
result = out*self.sa(out)
return result
参考文章:
https://blog.csdn.net/qq_41573860/article/details/116719469
Resnet_CBAM
参考文章:https://blog.csdn.net/lzzzzzzm/article/details/123558175
在ResNet里面加入CBAM模块
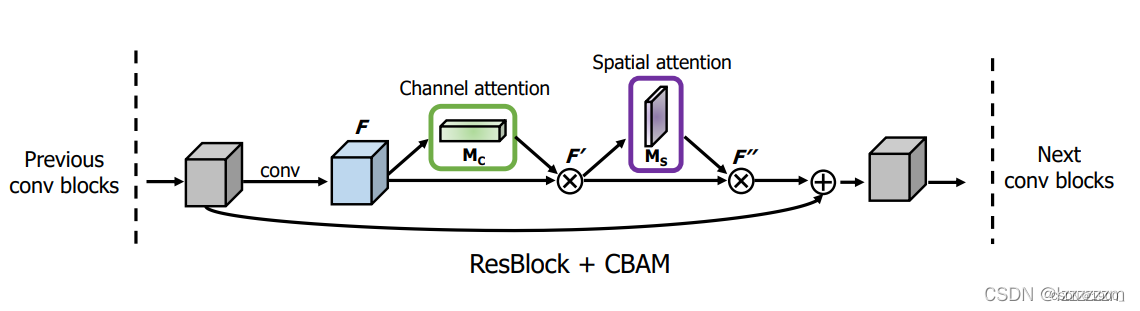
代码
class Bottleneck(nn.Module):
def __init__(
self,
inplanes: int,
planes: int,
stride: int = 1,
downsample: Optional[nn.Module] = None,
groups: int = 1,
base_width: int = 64,
dilation: int = 1,
norm_layer: Optional[Callable[..., nn.Module]] = None
):
super(Bottleneck, self).__init__()
expansion: int = 4
if norm_layer is None:
norm_layer = nn.BatchNorm2d
width = int(planes * (base_width / 64.)) * groups
# Both self.conv2 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv1x1(inplanes, width)
self.bn1 = norm_layer(width)
self.conv2 = conv3x3(width, width, stride, groups, dilation)
self.bn2 = norm_layer(width)
self.conv3 = conv1x1(width, planes * self.expansion)
self.bn3 = norm_layer(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
# attention
self.spatial_atten = SpatialAttention()
self.channel_atten = ChannelAttention(planes * self.expansion)
def forward(self, x: Tensor):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
# attention
atten = self.channel_atten(out) * out
atten = self.spatial_atten(atten) * atten
if self.downsample is not None:
identity = self.downsample(x)
atten += identity
out = self.relu(atten)
return out