Hive入门详解操作
Hive
第一章 Hive简介
1.1. Hive的简介
1.1.1 hive出现的原因
FaceBook网站每天产生海量的结构化日志数据,为了对这些数据进行管理,并且因为机器学习的需求,产生了hive这门技术,并继续发展成为一个成功的Apache项目。
1.1.2 什么是hive
hive是一个构建在Hadoop上的数据仓库工具(框架),可以将结构化的数据文件映射成一张数据表,并可以使用类sql的方式来对这样的数据文件进行读,写以及管理(包括元数据)。这套HIVE SQL 简称HQL。hive的执行引擎可以是MR、spark、tez。
如果执行引擎是MapReduce的话,hive会将Hql翻译成MR进行数据的计算。 用户可以使用命令行工具或JDBC驱动程序来连接到hive。
1.1.3 为什么使用hive
因为直接使用MapReduce,需要面临以下问题:
- 人员学习成本高
- 项目周期要求太短
- MapReduce实现复杂查询逻辑开发难度大
1.1.4 hive的优缺点
1) hive的优点
1.学习成本低
提供了类SQL查询语言HQL(简单,容易上手),避免了直接写MapReduce(适合java语言不好的,sql熟练的人),减少开发人员的学习成本。
2.可扩展性好
为超大数据集设计了计算/扩展能力(MR作为计算引擎,HDFS作为存储系统),Hive可以自由的扩展集群的规模,一般情况下不需要重启服务。
3.适合做离线分析处理(OLAP)
Hive的执行延迟比较高,因此Hive常用于数据分析,对实时性要求不高的场合。
4.延展性好
Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
5.良好的容错性
某个数据节点出现问题HQL仍可完成执行。
6.统计管理
提供了统一的元数据管理
2) hive的缺点
1. hive的HQL表达能力有限
- 迭代式算法无法表达,比如PageRank(网页排名)
- 数据挖掘方面,比如kmeans(k均值聚类算法)
2. hive的效率比较低
- hive自动生成的mapreduce作业,通常情况下不够智能化
- hive调优比较困难,粒度较粗
1.2. Hive架构和原理
1.2.1 hive的架构简介

从上图可以看出,Hive的体系结构分为以下几部分:
1. 用户连接接口
CLI:是指Shell命令行
JDBC/ODBC:是指Hive的java实现,与传统数据库JDBC类似。
WebUI:是指可通过浏览器访问Hive。
2. thriftserver:
hive的可选组件,此组件是一个软件框架服务,允许客户端使用包括Java、C++、Ruby和其他很多种语言,通过编程的方式远程访问Hive。
3. 元数据
Hive将元数据存储在数据库中,如mysql、derby。Hive中的元数据包括(表名、表所属的数据库名、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等)
4. 驱动器(Driver)
- 解析器(SQLParser):
将HQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完成,比如antlr;对AST进行语法
分析,比如表是否存在、字段是否存在、SQL语义是否有误。
- 编译器(Compiler):
对hql语句进行词法、语法、语义的编译(需要跟元数据关联),编译完成后会生成一个执行计划。hive上就
是编译成mapreduce的job。
- 优化器(Optimizer):
将执行计划进行优化,减少不必要的列、使用分区、使用索引等。优化job。
- 执行器(Executer):
将优化后的执行计划提交给hadoop的yarn上执行。提交job。
5. hadoop
Jobtracker是hadoop1.x中的组件,它的功能相当于:Resourcemanager+AppMaster
TaskTracker相当于:Nodemanager + yarnchild
Hive的数据存储在HDFS中,大部分的查询、计算由MapReduce完成
注意:
- 包含*的全表查询,比如select * from table 不会生成MapRedcue任务
- 包含*的limit查询,比如select * from table limit 3 不会生成MapRedcue任务
1.2.2 hive的工作原理
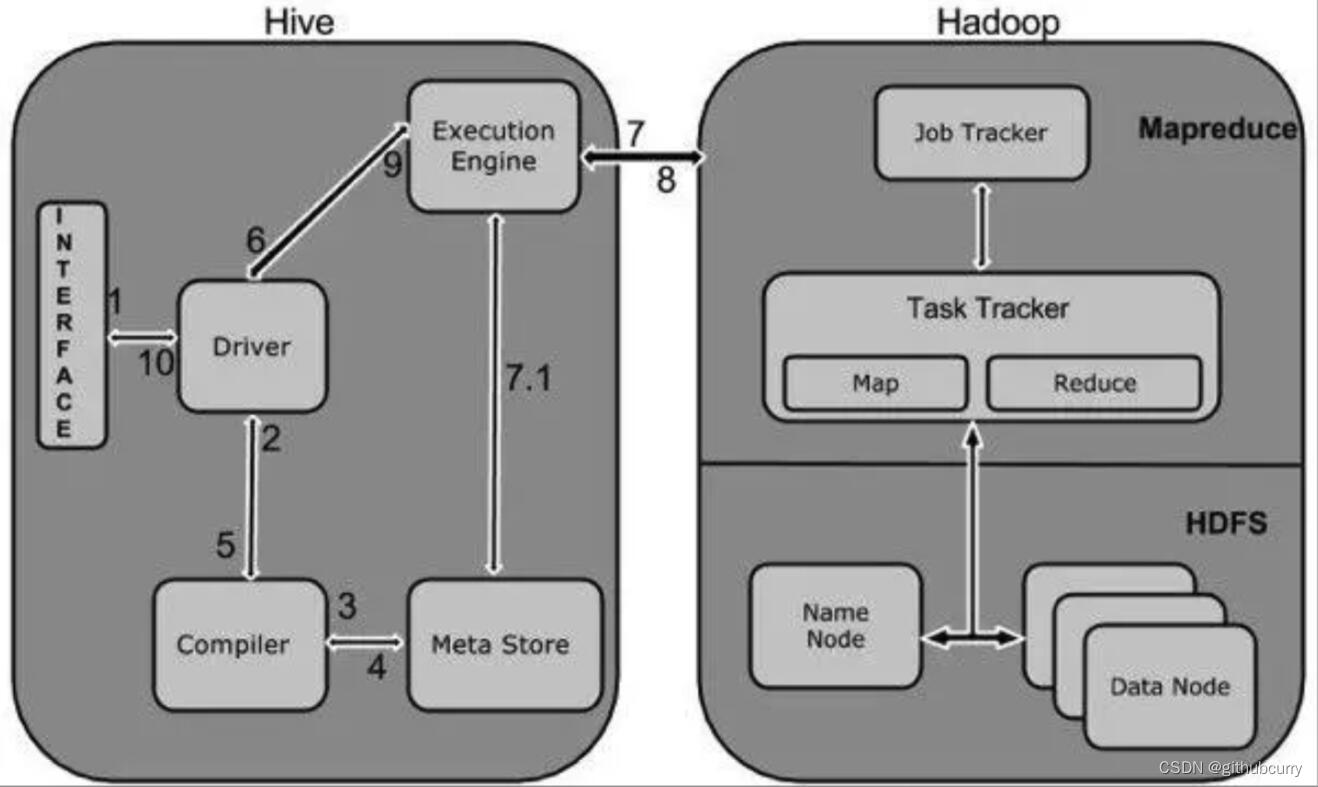
1. 用户提交查询等任务给Driver。
2. 驱动程序将Hql发送编译器,检查语法和生成查询计划。
3. 编译器Compiler根据用户任务去MetaStore中获取需要的Hive的元数据信息。
4. 编译器Compiler得到元数据信息,对任务进行编译,先将HiveQL转换为抽象语法树,然后将抽象语法树转换成查询块,将查询块转化为逻辑的查询计划,重写逻辑查询计划,将逻辑计划转化为物理的计划(MapReduce), 最后选择最佳的策略。
5. 将最终的计划提交给Driver。到此为止,查询解析和编译完成。
6. Driver将计划Plan转交给ExecutionEngine去执行。
7. 在内部,执行作业的过程是一个MapReduce工作。执行引擎发送作业给JobTracker,在名称节点并把它分配作业到TaskTracker,这是在数据节点。在这里,查询执行MapReduce工作。
7.1 与此同时,在执行时,执行引擎可以通过Metastore执行元数据操作。
8. 执行引擎接收来自数据节点的结果。
9. 执行引擎发送这些结果值给驱动程序。
10. 驱动程序将结果发送给Hive接口。
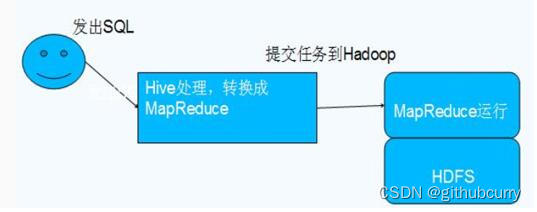
1.2.3 hive和hadoop的关系
- hive本身其实没有多少功能,hive就相当于在hadoop上面包了一个壳子,就是对hadoop进行了一次封装。
- hive的存储是基于hdfs/hbase的,hive的计算是基于mapreduce。
参考下图:
1.3 hive与传统型数据库的区别
1. Hive采用了类SQL的查询语言HQL,因此很容易将Hive理解为数据库。其实从结构上来看,Hive和数据库除了拥有类似的查询语言,再无类似之处。
2. 数据库可以用在OLTP的应用中,但是Hive是为数据仓库而设计的,清楚这一点,有助于从应用角度理解Hive的特性。
3. Hive不适合用于联机事务处理(OLTP),也不提供实时查询功能。它最适合应用在基于大量不可变数据的批处理作业。Hive 的特点是可伸缩(在Hadoop 的集群上动态的添加设备),可扩展、容错、输入格式的松散耦合。Hive 的入口是DRIVER ,执行的SQL语句首先提交到DRIVER驱动,然后调COMPILER解释驱动,最终解释成MapReduce 任务执行,最后将结果返回。
4. MapReduce 开发人员可以把自己写的 Mapper 和 Reducer 作为插件支持 Hive 做更复杂的数据分析。 它与关系型数据库的 SQL 略有不同,但支持了绝大多数的语句(如 DDL、DML)以及常见的聚合函数、连接查询、条件查询等操作。
Hive和数据库的比较如下表:
| 比较项 | 关系数据库 | Hive |
|---|---|---|
| ANSI SQL | 支持 | 不完全支持 |
| 更新 | UPDATE INSERT DELETE | INSERT OVERWRITE\ INTO TABLE |
| 事务 | 支持 | 支持(部分支持) |
| 模式 | 写模式 | 读模式 |
| 存储位置 | 块设备、本地文件系统 | HDFS |
| 延时 | 低 | 高 |
| 多表插入 | 不支持 | 支持 |
| 子查询 | 完全支持 | 只能用在From子句中 |
| 视图 | Updatable | Read-only |
| 可扩展性 | 低 | 高 |
| 数据规模 | 小 | 大 |
| 实时响应 | 毫秒级 | 秒级 |
详情解析
1、**查询语言**:由于SQL被广泛的应用在数据仓库中,因此,专门针对Hive的特性设计了类SQL的查询语言HQL。熟悉SQL开发的开发者可以很方便的使用Hive进行开发。
2、**数据存储位置**:Hive是建立在Hadoop之上的,所有Hive的数据都是存储在HDFS中的。而数据库则可以将数据保存在块设备或者本地文件系统中。
3、**数据格式**:Hive中没有定义专门的数据格式,数据格式可以由用户指定,用户定义数据格式需要指定三个属性:列分隔符(通常为空格、"\t"、"\x001")、行分隔符("\n")以及读取文件数据的方法(Hive中默认有三个文件格式TextFile、SequenceFile以及RCFile)。由于在加载数据的过程中,不需要从用户数据格式到Hive定义的数据格式的转换,因此,Hive在加载的过程中不会对数据本身进行任何修改,而只是将数据内容复制或者移动到相应的HDFS目录中。而在数据库中,不同的数据库有不同的存储引擎,定义了自己的数据格式。所有数据都会按照一定的组织存储,因此,数据库加载数据的过程会比较耗时。
4、**数据更新**:由于Hive是针对数据仓库应用设计的,而数据仓库的内容是读多写少的。因此,Hive中不支持对数据的改写和添加,所有的数据都是在加载的时候中确定好的。而数据库中的数据通常是需要经常进行修改的,因此可以使用INSERT INTO...VALUES添加数据,使用UPDATE...SET修改数据。
5、**索引**:,Hive在加载数据的过程中不会对数据进行任何处理,甚至不会对数据进行扫描,因此也没有对数据中的某些Key建立索引。Hive要访问数据中满足条件的特定值时,需要暴力扫描整个数据,因此访问延迟较高。由于MapReduce的引入,Hive可以并行访问数据,因此即使没有索引,对于大数据量的访问,Hive仍然可以体现出优势。数据库中,通常会针对一个或几个列建立索引,因此对于少量的特定条件的数据的访问,数据库可以有很高的效率,较低的延迟。由于数据的访问延迟较高,决定了Hive不适合在线数据查询。
6、**执行**:Hive中大多数查询的执行是通过Hadoop提供的MapReduce来实现的(类似select * from tbl的查询不需要MapReduce)。而数据库通常有自己的执行引擎。
7、**执行延迟**:之前提到,Hive在查询数据的时候,由于没有索引,需要扫描整个表,因此延迟较高。另外一个导致Hive执行延迟高的因素是MapReduce框架。由于MapReduce本身具有较高的延迟,因此在利用MapReduce执行Hive查询时,也会有较高的延迟。相对的,数据库的执行延迟较低。当然,这个低是有条件的,即数据规模较小,当数据规模大到超过数据库的处理能力的时候,Hive的并行计算显然能体现出优势。
8、**可扩展性**:由于Hive是建立在Hadoop之上的,因此Hive的可扩展性是和Hadoop的可扩展性是一致的。而数据库由于ACID语义的严格限制,扩展性非常有限。目前最先进的并行数据库Oracle在理论上的扩展能力也只有100台左右。
9、**数据规模**:由于Hive建立在集群上并可以利用MapReduce进行并行计算,因此可以支持很大规模的数据;对应的,数据库可以支持的数据规模较小。
Hive和Mysql的比较
- mysql用自己的存储存储引擎,hive使用的hdfs来存储。
- mysql使用自己的执行引擎,而hive使用的是mapreduce来执行。
- mysql使用环境几乎没有限制,hive是基于hadoop的。
- mysql的低延迟,hive是高延迟。
- mysql的handle的数据量较小,而hive的能handle数据量较大。
- mysql的可扩展性较低,而hive的扩展性较高。
- mysql的数据存储格式要求严格,而hive对数据格式不做严格要求。
- mysql可以允许局部数据插入、更新、删除等,而hive不支持局部数据的操作。
第二章 Hive的安装部署
Hive常用的安装分三种(注意:Hive会自动监测Hadoop的环境变量,如有就必须启动Hadoop)
先从本地上传Hive安装文件apache-hive-2.1.1-bin.tar.gz到/root/soft
2.1 内嵌模式:
使用hive自带默认元数据库derby来进行存储,通常用于测试
- 优点:使用简单,不用进行配置
- 缺点:只支持单session。
2.1.1 安装步骤:
1)解压hive并配置环境变量
[root@qianfeng01 local]# tar -zxvf apache-hive-2.1.1-bin.tar.gz -C /usr/local
#修改hive安装路径名,方便以后使用
[root@qianfeng01 local]# mv apache-hive-2.1.1-bin/ hive
[root@qianfeng01 local]# vi /etc/profile
# 添加如下内容:
export HIVE_HOME=/usr/local/hive
export PATH=$HIVE_HOME/bin:$PATH
#让profile生效
[root@qianfeng01 local]# source /etc/profile
2) 配置hive-env.sh
如果不存在,就用hive.env.sh.template复制一个
export HIVE_CONF_DIR=/usr/local/hive/conf
export JAVA_HOME=/usr/local/jdk
export HADOOP_HOME=/usr/local/hadoop
export HIVE_AUX_JARS_PATH=/usr/local/hive/lib
3) 配置hive-site.xml
hive2.1.1中默认是没有hive-site.xml,可以把conf/hive-default.xml.template拷贝过来使用
[root@qianfeng01 conf]# cp hive-default.xml.template hive-site.xml
[root@qianfeng01 conf]# vi hive-site.xml
把hive-site.xml 中所有包含 ${system:java.io.tmpdir}替换成/usr/local/hive/iotmp.
如果系统默认没有指定系统用户名,那么要把配置${system:user.name}替换成当前用户名root
扩展:hive-site.xml中有两个重要的配置说明
<!-- 该参数主要指定Hive的数据存储目录 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
<!-- 该参数主要指定Hive的临时文件存储目录 -->
<property>
<name>hive.exec.scratchdir</name>
<value>/tmp/hive</value>
<description>HDFS root scratch dir for Hive jobs which gets created with write all (733) permission. For each connecting user, an HDFS scratch dir: ${hive.exec.scratchdir}/<username> is created, with ${hive.scratch.dir.permission}.</description>
</property>
在linux中新建上面两个目录,并且进行权限赋值(可选操作,hive会自动创建)
[root@qianfeng01 hive] # hdfs dfs -mkdir -p /user/hive/warehouse
[root@qianfeng01 hive] # hdfs dfs -mkdir -p /tmp/hive/
[root@qianfeng01 hive] # hdfs dfs -chmod 750 /user/hive/warehouse
[root@qianfeng01 hive] # hdfs dfs -chmod 777 /tmp/hive
- 启动hadoop
[root@qianfeng01 hadoop]# start-dfs.sh
[root@qianfeng01 hadoop]# start-yarn.sh
- 初始化hive
[root@qianfeng01 hive]# schematool --initSchema -dbType derby
- 启动hive
(注:启动之前要启动hdfs sbin/start-dfs.sh 和yarn sbin/start-yarn.sh )
[root@qianfeng01 hive]# bin/hive
#进入后可以执行下面命令进行操作:
hive>show dataases; #查看数据库
hive>show tables; #查看表
简单sql演示执行
# 创建表
hive> create table dog(id int,name string);
hive> select * from dog;
hive> insert into dog values(1,"wangcai");
hive> desc dog; #查看表结构
hive> quit # 退出
2.2 本地模式
使用mysql替换derby进行元数据的存储,hive的相关进程都是在同一台机器上,即本地模式。mysql因为是独立的进程,所以mysql可以和hive在同一机器上,也可以在其他机器上。
说明:
通常使用关系型数据库来进行元数据存储(mysql、oracle等执行带jdbc驱动的数据库)
优点:支持多session
缺点:需要配置、还需要安装mysql等关系型数据库
2.2.1 配置安装mysql
安装MySql服务器
mysql安装的步骤介绍
# 环境准备
# CentOS7中,系统默认采用的数据库是mariadb,这个数据库与MySQL冲突!
# 因此,在安装MySQL之前,需要先将其卸载!
[root@qianfeng01 ~]# rpm -qa | grep mariadb # 查询是否已经安装了mariadb
mariadb-libs-5.5.64-1.el7.x86_64 # 查询结果。如果没有这个结果,说明没有安装。
# 强制卸载mariadb
# --nodeps: 强制卸载,RPM卸载程序的时候,如果这个程序被其他的程序依赖,是无法卸载的。
# 此时,就需要使用--nodeps,忽略依赖,强制卸载。
# 下面的卸载命令中,卸载的包是上方查询到的包
[root@qianfeng01 ~]# rpm -e mariadb-libs-5.5.64-1.el7.x86_64 --nodeps
# 安装MySQL
# 安装MySQL, 其实就需要安装 mysql-community-server, 但是它依赖其他的包
[root@qianfeng01 mysql]# rpm -ivh mysql-community-common-5.7.28-1.el7.x86_64.rpm
[root@qianfeng01 mysql]# rpm -ivh mysql-community-libs-5.7.28-1.el7.x86_64.rpm
[root@qianfeng01 mysql]# rpm -ivh mysql-community-client-5.7.28-1.el7.x86_64.rpm
[root@qianfeng01 mysql]# yum install -y net-tools
[root@qianfeng01 mysql]# rpm -ivh mysql-community-server-5.7.28-1.el7.x86_64.rpm
# 开启MySQL服务
# 查看MySQL服务的运行状态
[root@qianfeng01 ~]# systemctl status mysqld
# 如果MySQL服务没有开启,则开启
[root@qianfeng01 ~]# systemctl start mysqld
# 登录到MySQL
# 在第一次开启MySQL服务的时候,会自动生成一个随机的密码
[root@qianfeng01 ~]# grep password /var/log/mysqld.log # 到mysqld.log文件中查找password
2020-12-16T07:47:14.117739Z 1 [Note] A temporary password is generated for root@localhost: pVLJs6&o(QQe
# 使用这个随机密码登录到MySQL
[root@qianfeng01 ~]# mysql -u root -p
pVLJs6&o(QQe # 这里用自己的密码登录
# 修改MySQL安全等级
# 1. 修改MySQL的密码策略(安全等级)
# MySQL默认的密码安全等级有点高,在设置密码的时候,必须同时包含大小写字母、数字、特殊字符,以及对位数有要求
show variables like '%validate_password%'; # 查看密码策略
set global validate_password_policy=LOW; # 修改密码策略等级为LOW
set global validate_password_length=4; # 密码的最小长度
set global validate_password_mixed_case_count=0; # 设置密码中至少要包含0个大写字母和小写字母
set global validate_password_number_count=0; # 设置密码中至少要包含0个数字
set global validate_password_special_char_count=0; # 设置密码中至少要包含0个特殊字符
# 2. 修改密码
alter user root@localhost identified by '123456';
# 3. 远程授权
grant all privileges on *.* to 'root'@'%' identified by '123456' with grant option;
2.2.2 配置hive的环境
1、解压并配置环境变量
2、配置hive的配置文件
cp hive-env.sh.template hive-env.sh
vi hive-env.sh(可以配置jdk、hive的conf路径)
3、在Hive的conf配置hive的自定义配置文件
vi hive-site.xml:添加如下内容
**注意:**前三步和内嵌模式一样
4、找到下面四个属性进行修改对应的值。
<!--配置mysql的连接字符串-->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://qianfeng03:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<!--配置mysql的连接驱动-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<!--配置登录mysql的用户-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<!--配置登录mysql的密码-->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to use against metastore database</description>
</property>
注意:hive的元数据在mysql库里创建的数据库hive的编码最好设置成latin1.
show variables like 'character%';
5、将mysql的驱动包mysql-connector-java-5.1.28-bin.jar上传到$HIVE_HOME/lib下(注意:驱动是jar结尾,不是tar结尾)
6、执行执行先要初始化数据库
[root@qianfeng01 hive]# bin/schematool -initSchema -dbType mysql
7、启动hive
[root@qianfeng01 hive]# bin/hive
说明: hive命令会默认启动元数据服务项(metastore)
2.3 远程模式
2.3.1 简介
将hive中的相关进程比如hiveserver2或者metastore这样的进程单独开启,使用客户端工具或者命令行进行远程连接这样的服务,即远程模式。客户端可以在任何机器上,只要连接到这个server,就可以进行操作。客户端可以不需要密码。

2.3.2 服务端的配置
1) 修改 hive-site.xml
<!--hive仓库在hdfs的位置-->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
<!-- 该参数主要指定Hive的临时文件存储目录 -->
<property>
<name>hive.exec.scratchdir</name>
<value>/tmp/hive</value>
</property>
<!--连接mysql的url地址-->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://qianfeng03:3306/hive?createDatabaseIfNotExist=true&characterEncoding=latin1</value>
</property>
<!--mysql的驱动类-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!--mysql的用户名-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!--mysql的密码-->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<!--hive工作的本地临时存储空间-->
<property>
<name>hive.exec.local.scratchdir</name>
<value>/usr/local/hive/iotmp/root</value>
</property>
<!--如果启用了日志功能,则存储操作日志的顶级目录-->
<property>
<name>hive.server2.logging.operation.log.location</name>
<value>/usr/local/hive/iotmp/root/operation_logs</value>
</property>
<!--Hive运行时结构化日志文件的位置-->
<property>
<name>hive.querylog.location</name>
<value>/usr/local/hive/iotmp/root</value>
</property>
<!--用于在远程文件系统中添加资源的临时本地目录-->
<property>
<name>hive.downloaded.resources.dir</name>
<value>/usr/local/hive/iotmp/${hive.session.id}_resources</value>
</property>
说明:使用远程模式,需要在hadoop的core-site.xml文件中添加一下属性
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
2.3.3 hive的两种服务说明
第一种服务:hiveserver2
1. 该服务端口号默认是10000
2. 可以单独启动此服务进程,供远程客户端连接;此服务内置metastore服务。
3. 启动方式:
方法1:
直接调用hiveserver2。会进入监听状态不退出。
方法2:
hive --service hiveserver2 & 进入后台启动
方法3:
hive --service hiveserver2 >/dev/null 2>&1 &; #信息送入黑洞。
第二种服务:metastore
1. 此服务才是真正连接元数据库的服务进程
2. 也可以让远程客户端连接
3. 启动方式:
方法1:
- hive --service metastore &
方法2:
- hive --service metastore 2>&1 >/dev/null &; #信息送入黑洞。
2.3.4 客户端连接hiveserver2服务
说明:
-1. 连接此服务的hive客户端,只需要配好环境变量即可
-2. 只能使用hive中的beeline连接工具进行连接此服务,beeline是hive的一个轻量级的连接客户端工具。
连接方式:
方式1:
step1. beeline 回车
step2. !connect jdbc:hive2://ip:10000 回车
step3. 输入用户名 回车
step4. 输入密码 回车
方法2(直连):
1. beeline -u jdbc:hive2://ip:10000 -n 用户名
解析:
hive2,是hive的协议名称
ip: hiveserver2服务所在的主机IP。
10000,是hiveserver2的端口号d
2.3.5 客户端连接metastore服务
注意:想要连接metastore服务的客户端必须配置如下属性和属性值
<property>
<name>hive.metastore.uris</name>
<value>thrift://ip:9083</value>
</property>
解析:thrift:是协议名称
ip为metastore服务所在的主机ip地址
9083是默认端口号
第三章 Hive基本操作-库、表
3.1 规则语法
大小写规则:
1. hive的数据库名、表名都不区分大小写
2. 建议关键字大写
命名规则:
1. 名字不能使用数字开头
2. 不能使用关键字
3. 尽量不使用特殊符号
3.2 库操作语法
3.2.1 创建数据库
创建数据库的本质就是在hive的参数${hive.metastore.warehouse.dir}对应的目录下,创建一个新的目录,此目录的名称为: 库名.db。
注意:在创建库或者表时除了创建目录外,还会在mysql中(元数据库),添加元数据(描述信息)
hive> create database zoo;
hive> create database if not exists zoo;
hive> create database if not exists qfdb comment 'this is a database of qianfeng';
hive有一个默认的数据库default,如果不明确的说明要使用哪个库,则使用默认数据库。
3.2.2 查看所有数据库:实际就是从元数据库中获取对应的元数据
语法:show databases;
3.2.3 切换数据库
语法:use mydb;
3.2.4 查看数据库信息
语法1:desc database databaseName;
语法2:desc database extended databaseName;
语法3:describe database extended databaseName;
3.2.5 删除数据库
语法1:drop database databasename; # 这个只能删除空库
语法2:drop database databasename cascade; # 如果不是空库,则可以加cascade强制删除
3.3 表操作语法
3.3.1 数据类型
Hive的数据类型分为基本数据类型和复杂数据类型,下面是基本数据类型(复杂类型到后期再讲)
其中加粗体是重点要掌握的类型
| 分类 | 类型 | 描述 | 字面量示例 |
|---|---|---|---|
| 基本类型 | BOOLEAN | true/false | TRUE |
| TINYINT | 1字节的有符号整数 -128~127 | 1Y | |
| SMALLINT | 2个字节的有符号整数,-32768~32767 | 1S | |
| INT | 4个字节的带符号整数 | 1 | |
| BIGINT | 8字节带符号整数 | 1L | |
| FLOAT | 4字节单精度浮点数 | 1.0 | |
| DOUBLE | 8字节双精度浮点数 | 1.0 | |
| DEICIMAL | 任意精度的带符号小数 | 1.0 | |
| STRING | 字符串,可变长度 | “a”,’b’ | |
| VARCHAR | 变长字符串,要设置长度 | “a”,’b’ | |
| CHAR | 固定长度字符串 | “a”,’b’ | |
| BINARY | 字节数组 | 无法表示 | |
| TIMESTAMP | 时间戳,纳秒精度 | 122327493795 | |
| DATE | 日期 | ‘2016-03-29’ | |
| 复杂类型 | ARRAY | 有序的的同类型的集合 | array(1,2) |
| MAP | key-value,key必须为原始类型,value可以任意类型 | map(‘a’,1,’b’,2) | |
| STRUCT | 字段集合,类型可以不同 | struct(‘1’,1,1.0) | |
| UNION | 在有限取值范围内的一个值 | create_union(1,’a’,63) |
3.3.2 创建表
创建表的本质其实就是在对应的数据库目录下面创建一个子目录,目录名为表名。数据文件就存在这个目录下。
语法1:
create table t_user(id int,name string);
语法2:使用库.表的形式
create table mydb.t_user(id int,name string);
语法3:指定分隔规则形式
create table if not exists t1(
uname string comment 'this is name',
chinese int,
math int,
english int
)
comment 'this is my table'
row format delimited
fields terminated by '\t'
lines terminated by '\n'
stored as textfile;
create table if not exists emp(
eno int,
ename string,
job string,
mgr int,
hiredate int,
salary int,
comm int,
deptno int
)
row format delimited
fields terminated by ','
lines terminated by '\n'
stored as textfile;
3.3.3 查看当前表空间中的所有表名
语法:show tables;
# 查看另外一个数据库中的表
show tables in zoo;
3.3.4 查看表结构
desc tableName
desc extended tableName;
describe extended tableName;
3.3.5 修改表结构
- 修改表名
alter table oldTableName rename to newTableName;
- 修改列名:change column 和修改字段类型是同一个语法
alter table tableName change column oldName newName colType;
alter table tableName change column colName colName colType;
- 修改列的位置: 注意,2.x版本后,必须是相同类型进行移动位置。
alter table tableName change column colName colName colType after colName1;
alter table tableName change column colName colName colType first;
- 增加字段:add columns
alter table tableName add columns (sex int,...);
- 删除字段:replace columns #注意,2.x版本后,注意类型的问题,替换操作,其实涉及到位置的移动问题。
alter table tableName replace columns(
id int,
name int,
size int,
pic string
);
注意:实际上是保留小括号内的字段。
3.3.6 删除表
drop table tableName;
3.4 数据导入
[root@qianfeng01 hive]# mkdir /hivedata
[root@qianfeng01 hive]# cd /hivedata
[root@qianfeng01 hive]# vi user.txt
-- 加入下面的数据
1,廉德枫
2,刘浩
3,王鑫
4,司翔
create table t_user(
id int,
name string
)
row format delimited
fields terminated by ','
lines terminated by '\n'
stored as textfile;
加载数据到Hive,一般分为两种:
- 一种是从本地Linux上加载到Hive中
- 另外一种是从HDFS加载到Hive中
**方法1:**使用hdfs dfs -put将本地文件上传到表目录下
hdfs dfs -put ./u1.txt /user/hive/warehouse/mydb1.db/u1
**方法2:**在hive中使用load 命令
load data [local] inpath '文件路径' [overwrite] into table 表名
加载数据时:
1. 最好是写绝对路径,从根开始写。
2. 写相对路径也是可以的,但是一定要记住你登录hive时的位置,从当前位置写相对路径
3. ~在hive中,是相对路径的写法
4. 使用benline工具进行远程登录(客户端与服务端不在同一台机器)时,使用以下语句时:
load data local inpath '文件路径' [overwrite] into table 表名
会有一个大坑:local是指服务端的文件系统。
**方法3:**从另外一张表(也可称之为备份表)中动态加载数据
insert into table tableName2 select [.....] from tableName1;
扩展内容:向多张表中插入数据的语法
from tableName1
insert into tableName2 select * where 条件
insert into tableName3 select * where 条件
.....
create table u2(
id int,
name string
)
row format delimited
fields terminated by ',';
insert into table u2 select id,name from u1;
create table u3(
id int,
name string
)
row format delimited
fields terminated by ',';
create table u4(
id int,
name string
)
row format delimited
fields terminated by ',';
from u2
insert into u3 select *
insert into u4 select id,name;
create table u8(
id int,
name string
)
row format delimited
fields terminated by ',';
注意: tableName2表中的字段个数必须和tableName1表中查询出来的个数相同
**方法4:**克隆表数据
- create table if not exists tableName2 as select [....] from tableName1;
- create table if not exists tableName2 like tableName1 location 'tableName1的存储目录的路径' # 新表不会产生自己的表目录,因为用的是别的表的路径
扩展内容:只复制表结构
create table if not exists tableName2 like tableName1;
加载数据的本质:
- 如果数据在本地,加载数据的本质就是将数据copy到hdfs上的表目录下。
- 如果数据在hdfs上,加载数据的本质是将数据移动到hdfs的表目录下。
注意:hive使用的是严格的读时模式:加载数据时不检查数据的完整性,读时发现数据不对则使用NULL来代替。
而mysql使用的是写时模式:在写入数据时就进行检查
3.5 案例演示
CREATE TABLE flow(
id string COMMENT 'this is id column',
phonenumber string,
mac string,
ip string,
url string,
urltype string,
uppacket int,
downpacket int,
upflow int,
downflow int,
issuccess int
)
COMMENT 'this is log table'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LINES TERMINATED BY '\n'
stored as textfile;
加载数据:
load data local inpath './data/HTTP_20130313143750.dat' into table flow;
1、统计每个电话号码的总流量(M)
select l.phonenumber,
round(sum(l.upflow + l.downflow) / 1024.0,2) as total
from flow l
group by l.phonenumber
;
2、第二个需求,求访问次数排名前3的url:
select l.url url,
count(l.url) as urlcount
from flow l
group by l.url
order by urlcount desc
limit 3
;
3.6 数据导出
3.6.1 hive数据导出分类
1. 从hive表中导出本地文件系统中(目录、文件)
2. 从hive表中导出hdfs文件系统中
3. hive表中导出到其它hive表中
3.6.2 导出到目录下
--1. 导出数据到本地文件系统的目录下
insert overwrite local directory '/root/out/00'
select * from student;
--2. 导出数据到hdfs的目录下
insert overwrite directory '/root/out/01'
select * from student;
-- 导出的文件中字段默认不分隔。
--3. 修改导出后的列与列之间的格式:
insert overwrite local directory '/root/out/01'
row format delimited fields terminated by ','
select * from student;
3.6.3 直接导入到本地文件系统s的文件中:
[root@qianfeng01 ~]# hive -e 'select * from exercise.student' >> /root/out/02;
-- 导出的文件中字段分隔符默认是\t
第四章 表类型详解
4.1 表分类
在Hive中,表类型主要分为两种,
第一种:内部表
- 也叫管理表
- 表目录会创建在集群上的{hive.metastore.warehouse.dir}下的相应的库对应的目录中。
- 默认创建的表就是内部表
第二种:外部表
- 外部表需要使用关键字"external",
- 外部表会根据创建表时LOCATION指定的路径来创建目录,
- 如果没有指定LOCATION,则位置跟内部表相同,一般使用的是第三方提供的或者公用的数据。
- 建表语法:必须指定关键字external。
create external table tableName(id int,name string) [location 'path'];
create external table t_user7(
id int,
name string
)
row format delimited
fields terminated by ','
location '/publicData'
4.2 内部表和外部表转换:
内部表转外部表
alter table tableName set tblproperties('EXTERNAL'='TRUE');
注意:内部表转外部表,true一定要大写;
外部表转内部表
alter table tableName set tblproperties('EXTERNAL'='false');
说明:false不区分大小
4.3 两者之间区别
1) 内部表和外部表在创建时的差别
就差两个关键字,EXTERNAL 和 LOCATION
举例:
- 内部表 -- CRAATE TABLE T_INNER(ID INT);
- 外部表 -- CREATE EXTERNAL TABLE T_OUTER(ID INT) LOCATION 'HDFS:///AA/BB/XX';
2) Hive表创建时要做的两件事:
-
在hdfs下创建表目录
-
在元数据库mysql创建相应表的描述数据(元数据)
3) drop时有不同的特性:
1、drop时,元数据都会被清除
2、drop时,内部表的表目录会被删除,但是外部表的表目录不会被删除。
4) 使用场景
内部表: 平时用来测试或者少量数据,并且自己可以随时修改删除数据.
外部表:使用后数据不想被删除的情况使用外部表(推荐使用)所以,整个数据仓库的最底层的表使用外部表
第五章 Hive Shell技巧
5.1 只执行一次Hive命令
通过shell的参数 -e 可以执行一次就运行完的命令
[root@qianfeng01 hive]# hive -e "select * from cat"
小技巧2:可以通过外部命令快速查询某个变量值:
hive -S -e “set” |grep cli.print
-S 是静默模式,会省略到多余的输出
5.2 单独执行一个sql文件
通过参数-f +file文件名就可以,经常用在以后的sql文件单独执行,导入数据场景中
[root@qianfeng01 hive]# hive -f /path/cat.sql
小技巧:在shell内部 可以通过source命令来执行一个sql
5.3 执行Linux命令
在Hive的shell中 加上前缀! 最后以分号;结尾,可以执行linux的命令
hive> ! pwd ;
5.4 执行HDFS命令
用户可以在Hive的shell中执行HDFS的DFS命令,不用敲入前缀hdfs或者hadoop
hive> dfs -ls /tmp
5.5 使用历史命令和自动补全
在Hive的Shell操作中可以使用上下箭头查看历史记录
如果忘记了命令可以用tab键进行补全
5.6 显示当前库:
下面是通过配置文件hive-site.xml显示
<property>
<name>hive.cli.print.current.db</name>
<value>false</value>
<description>Whether to include the current database in the Hive prompt.</description>
</property>
5.7 当前session里设置该参数:
hive> set hive.cli.print.current.db=true;
5.8 查看当前参数设置的值:
小技巧1:可以在shell中输入set命令,可以看到hive已经设定好的参数
hive> set hive.cli.print.current.db;
5.9. local模式
hive.exec.mode.local.auto=false (建议打开)
hive.exec.mode.local.auto.inputbytes.max=134217728
hive.exec.mode.local.auto.input.files.max=4
第六章 Hive基本查询语法
6.1 基本使用规则
6.1.1 基本查询语句组成
select ..
from ..
join [tableName] on ..
where ..
group by ..
having ..
order by ..
sort by ..
limit ..
union | union all ...
6.1.2 执行顺序
第一步: FROM <left_table>
第二步: ON <join_condition>
第三步: <join_type> JOIN <right_table>
第四步: WHERE <where_condition>
第五步: GROUP BY <group_by_list>
第六步: HAVING <having_condition>
第七步: SELECT
第八步: DISTINCT <select_list>
第九步: ORDER BY <order_by_condition>
第十步: LIMIT <limit_number>
标准sql语句的一些规则:
-1. 列别名的使用,必须完全符合执行顺序,不能提前使用。(mysql除外)
-2. 在分组查询时,select子句中只能含有分组字段和聚合函数,不能有其他普通字段。(mysql除外)
6.1.3 查询原则
1. 尽量不使用子查询、尽量不使用in 或者not in (可以使用 [not] exists替代)
2. 尽量避免join连接查询,但是通常避免不了
3. 查询永远是小表驱动大表(小表作为驱动表)
--注意:内连接时,默认是左表是驱动表,因此左表一定要是小表。
-- 外连接看需求而定。
6.2 常用子句回顾
6.2.1 where语句特点
where后不能使用聚合函数,可以使用子查询,也可以是普通函数。
条件可以是:
1. 关系表达式: =, >,>=,<,<=,!=,<>
2. 连接符号: or,and, between .. and ..
3. 模糊查询: like
%:通配符
_:占位符
4. [not] in
>all(set) >any();
注意事项:在hive的where中如果使用了子查询作为条件,等号“=”不好使,需要使用[not] in.
换句话说,即使子查询返回的是唯一的一个值,也是集合形式。
6.2.2 group by语句特点
group by: 分组,通常和聚合函数搭配使用
查询的字段要么出现在group by 后面,要么出现在聚合函数里面
聚合函数:count(),sum(),max(),min(),avg()
count的执行
1. 执行效果上:
- count(*)包括了所有的列,相当于行数,在统计结果的时候不会忽略null值
- count(1)包括了所有列,用1代表行,在统计结果的时候也不会忽略null值
- count(列名)只包括列名那一列,在统计结果时,会忽略null值
2.执行效率上:
- 列名为主键,count(列名)会比count(1)快
- 列名不为主键,count(1)会比count(列名)快
- 如果表中有多个列并且没有主键,count(1)的效率高于count(*)
- 如果有主键count(主键)效率是最高的
- 如果表中只有一个字段count(*)效率最高
6.2.3 having子句特点
对分组以后的结果集进行过滤。可以使用聚合函数。
6.2.4 order by子句
对查询的数据进行排序。
desc 降序
asc 升序
语法:
order by colName [desc|asc][,colName [desc|asc]]
6.2.5 limit语句特点
limit : 从结果集中取数据的条数
将set hive.limit.optimize.enable=true 时,limit限制数据时就不会全盘扫描,而是根据限制的数量进行抽样。
同时还有两个配置项需要注意:
hive.limit.row.max.size 这个是控制最大的抽样数量
hive.limit.optimize.limit.file 这个是抽样的最大文件数量
注意:limit 在mysql中 可以有两个参数 limit [m,] n
在hive中,只能有一个参数 limit n; 查询前n条。
一般情况下,在使用limit时,都会先order by排序。
6.2.6 union | union all
union all:将两个或者多个查询的结果集合并到一起。不去重
union:将两个或者多个查询的结果集合并到一起,去重合并后的数据并排序
union语句字段的个数要求相同,字段的顺序要求相同。
6.3 join连接
6.3.1 join知识点回顾
有的业务所需要的数据,不是在一张表中,通常会存在多张表中,而这些表中通常应该会存在"有关系"的字段。多表查询时,使用关联字段"连接"(join)在一起,组合成一个新的数据集,就是连接查询。
连接查询操作分为两大类:内连接和外连接,而外连接有细分为三种类型。参考下图
1. 内连接: [inner] join
2. 外连接 (outer join):(引出一个驱动表的概念:驱动表里的数据全部显示)
- 左外连接:left [outer] join, 左表是驱动表
- 右外连接:right [outer] join, 右表是驱动表
- 全外连接:full [outer] join, hive支持,mysql不支持.两张表里的数据全部显示出来
3. 注意: join连接只支持等值连接
需要大家注意的是,两张表的关联字段的值往往是不一致的。比如,表 A 包含张三和李四,表 B 包含李四和王五,匹配的只有李四这一条记录。从上图很容易看出,一共有四种处理方式和结果。下图就是四种连接的图示,这张图比上面的维恩图更易懂,也更准确。
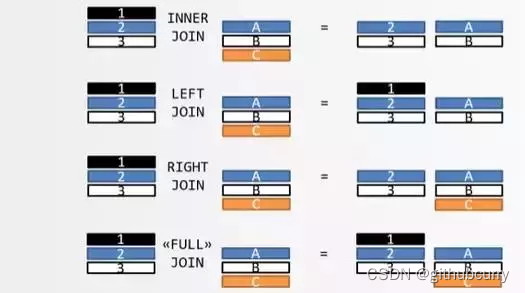
上图中,表 A 的记录是 123,表 B 的记录是 ABC,颜色表示匹配关系。返回结果中,如果另一张表没有匹配的记录,则用 null 填充。
笛卡尔积
指的是表 A 和表 B 不存在关联字段,这时表 A(共有 n 条记录)与表 B (共有 m 条记录)连接后,会产生一张包含 n x m 条记录(笛卡尔积)的新表(见下图)。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rBOm5RN1-1666066972674)(Hive.assets/cross-1587961616923.png)]
案例演示:
准备数据
u1文件中的数据如下:
1,a
2,b
3,c
4,d
7,y
8,u
u2文件中的数据如下:
2,bb
3,cc
7,yy
9,pp
create table if not exists u1(
id int,
name string
)
row format delimited
fields terminated by ','
;
create table if not exists u2(
id int,
name string
)
row format delimited fields terminated by ','
;
load data local inpath './data/u1.txt' into table u1;
load data local inpath './data/u2.txt' into table u2;
6.3.2 left semi join
在hive中,有一种专有的join操作,left semi join,我们称之为半开连接。它是left join的一种优化形式,只能查询左表的信息,主要用于解决hive中左表的数据是否存在的问题。相当于exists关键字的用法。
先回顾exists关键字的用法:exists关键字:满足条件返回true,不满足条件返回false
练习:
查询有领导的员工信息
select * from emp where mgr is not null
select * from emp A where exists (select 1 from emp B where B.empno = A.mgr )
select * from emp A left semi join emp B where A.mgr = B.empno;
查询有下属的员工信息
select * from emp A where exists (select 1 from emp B where B.mgr = A.empno )
查看有部门的所有员工的信息
select * from emp A where exists (select 1 from dept B where B.deptno = A.deptno )
left semi join的写法。
-- 左外连接,左表中的数据全部返回
select * from u1 left join u2 on u1.id =u2.id;
select * from u1 left outer join u2 on u1.id =u2.id;
-- 左半开连接,只显示左表中满足条件的数据。和exists的逻辑是相同的
select * from u1 left semi join u2 on u1.id =u2.id;
-- exists的写法
select * from u1 where exists (select 1 from u2 where u2.id =u1.id);
--验证left semi join 是否可以显示第二张表的信息:错误写法。
select A.*, B.* from u1 A left semi join u2 B on A.id =B.id;
注意: hive中不支持right semi join
6.4 hive日志
Hive中的日志分为两种,一种是系统日志,记录了hive的运行情况,错误状况。Job 日志,记录了Hive 中job的执行的历史过程。
在hive-log4j2.properties记录着日志文件的存储位置
property.hive.log.dir = ${sys:java.io.tmpdir}/${sys:user.name}
property.hive.log.file = hive.log
6.5 Hql的三种运行方式
6.5.1 在hive的client中运行
1. 本地模式下使用hive进行client
2. 远程模式下使用beeline工具进入client
3. 远程模式下使用hive进入client
6.5.2 在linux命令行中执行hql
[root@qianfeng01 ~]$ hive -e 'hql query'
案例:
[root@qianfeng01 ~]$ hive --database mydb -e 'select * from studentinfo';
[root@qianfeng01 ~]$ hive --database exercise --hivevar ls=2 --hiveconf tn=student -e 'select * from ${hiveconf:tn} limit ${hivevar:ls}';
参数选项说明:
-e 用于执行hql语句
-f 用于执行sql脚本文件
-S 静音模式,不显示mapreduce执行过程
-i 启动hive时初始化一个文件
6.5.3 在命令行中执行hql文件
[root@qianfeng01 ~]$ hive -f 'sql script'
案例:
[root@qianfeng01 ~]$ vi hfile.sql
use exercise;
select count(*) from student where s_id<5;
[root@qianfeng01 ~]$ hive -f ./hfile.sql或者使用静音模式
[root@qianfeng01 ~]$ hive -S -f ./hfile.sql
第七章 数据类型的讲解
在hive中,数据类型分为基础数据类型和复杂数据类型两大类型
7.1 数据类型
| 分类 | 类型 | 描述 | 字面量示例 |
|---|---|---|---|
| 基本类型 | BOOLEAN | true/false | TRUE |
| TINYINT | 1字节的有符号整数 -128~127 | 1Y | |
| SMALLINT | 2个字节的有符号整数,-32768~32767 | 1S | |
| INT | 4个字节的带符号整数 | 1 | |
| BIGINT | 8字节带符号整数 | 1L | |
| FLOAT | 4字节单精度浮点数 | 1.0 | |
| DOUBLE | 8字节双精度浮点数 | 1.0 | |
| DEICIMAL | 任意精度的带符号小数 | 1.0 | |
| STRING | 字符串,变长 | “a”,’b’ | |
| VARCHAR | 变长字符串,要设置长度 | “a”,’b’ | |
| CHAR | 固定长度字符串 | “a”,’b’ | |
| BINARY | 字节数组 | 无法表示 | |
| TIMESTAMP | 时间戳,纳秒精度 | 122327493795,另一种“yyyy-MM-dd HH:mm:ss” | |
| DATE | 日期 | ‘2016-03-29’ | |
| 复杂类型 | ARRAY | 有序的的同类型的集合 | array(1,2) |
| MAP | key-value,key必须为原始类型,value可以任意类型 | map(‘a’,1,’b’,2) | |
| STRUCT | 字段集合,类型可以不同 | struct(‘1’,1,1.0), named_stract(‘col1’,’1’,’col2’,1,’clo3’,1.0) | |
| UNION | 在有限取值范围内的一个值 | create_union(1,’a’,63) |
示例:
create table if not exists datatype1(
id1 tinyint,
id2 smallint,
id3 int,
id4 bigint,
slary float,
comm double,
isok boolean,
content binary,
dt timestamp
)
row format delimited
fields terminated by '\t'
;
233 12 342523 455345345 30000 60000 nihao helloworld 2017-06-02
126 13 342526 455345346 80000 100000 true helloworld1 2017-06-02 11:41:30
-timestamp 如果是年月日时分秒的格式,必须是写全,才能映射成功。
load data local inpath './data/datatype.txt' into table datatype1;
扩展) 数据类型转换
自动转换(隐式转换)
- 在做运算时,小范围类型都可以自动转为大范围类型做运算
7.2 复杂数据类型之array
7.2.1 定义格式如下:
create table tableName(
......
colName array<基本类型>
......
)
说明:下标从0开始,越界不报错,以null代替
7.2.2 案例准备:
zhangsan 78,89,92,96
lisi 67,75,83,94
王五 23,12
create table if not exists arr1(
name string,
scores array<String>
)
row format delimited
fields terminated by '\t'
;
drop table arr2;
create table if not exists arr2(
name string,
scores array<String>
)
row format delimited
fields terminated by '\t'
collection items terminated by ','
;
load data local inpath './data/arr1.txt' into table arr1;
load data local inpath './data/arr1.txt' into table arr2;
7.2.3 查询语句:
select * from arr1;
select name,scores[1] from arr2 where size(scores) > 3;
--统计arr2中的每个人的总成绩
select scores[0]+scores[1]+nvl(scores[2],0)+nvl(scores[3],0) from arr2;
7.2.4 想要一种效果:也就是将数组类型的数据元素展开,换句话说,就是列转行
zhangsan 78,89,92,96
lisi 67,75,83,94
王五 23,12
将上述效果转成下面的效果,更方便统计每个人的总成绩。
zhangsan 78
zhangsan 89
zhangsan 92
zhangsan 96
lisi 67
lisi 75
lisi 83
lisi 94
王五 23
王五 12
7.3 展开函数的使用
7.3.1 简介
- explode:
展开函数(UDTF函数中的一种),作用是:接受一个数据行,然后返回产生多个数据行
- lateral view:虚拟表。
会将UDTF函数生成的结果放到一个虚拟表中,然后这个虚拟表会和输入行进行join来达到数据聚合的目的
7.3.2 上案例:
- select explode(score) score from arr2;
- select name,cj from arr2 lateral view explode(scores) mytable as cj;
- 统计每个学生的总成绩:
select name,sum(cj) as totalscore from arr2 lateral view explode(scores) mytable as cj
group by name;
7.3.3 需求:向array字段中动态加载数据,不直接load加载,而是insert。
7.3.3.1 准备数据
create table arr_temp
as
select name,cj from arr2 lateral view explode(scores) score as cj;
7.3.3.2 借助collect_set函数,列转行函数,有去重效果。collect_list函数没有去重效果
drop table arr3;
create table if not exists arr3(
name string,
scores array<string>
)
row format delimited
fields terminated by ' '
collection items terminated by ','
;
将数据写成array格式:
insert into arr3
select name,collect_set(cj) from arr_temp group by name;
查询每个人的最后一科的成绩
select name,scores[size(scores)-1] lastsubject from arr3;
7.4. 复杂数据类型之map
7.4.1 定义格式如下:
create table tableName(
.......
colName map<T,T>
......
)
7.4.2 案例准备:
zhangsan chinese:90,math:87,english:63,nature:76
lisi chinese:60,math:30,english:78,nature:0
wangwu chinese:89,math:25
create table if not exists map1(
name string,
score map<string,int>
)
row format delimited
fields terminated by '\t'
collection items terminated by ','
map keys terminated by ':'
;
load data local inpath './data/map1.txt' into table map1;
7.4.3 查询语句:
#查询数学大于35分的学生的英语和自然成绩:
select
m.name,
m.score['english'] ,
m.score['nature']
from map1 m
where m.score['math'] > 35
;
#查看每个人的前两科的成绩总和
select
m.name,
m.score['chinese']+m.score['math']
from map1 m;
7.4.4 展开查询
- 展开效果
zhangsan chinese 90
zhangsan math 87
zhangsan english 63
zhangsan nature 76
- explode展开数据:
select explode(score) as (m_object,m_score) from map1;
- 使用lateral view explode 结合查询:
select name,m_object,m_score from map1 lateral view explode(score) score as
m_object,m_score;
- 统计每个人的总成绩
select name,sum(m_score)
from map1 lateral view explode(score) score as
m_object,m_score
group by name;
7.4.5 将数据动态写入map字段中
将下面的数据格式
zhangsan chinese 90
zhangsan math 87
zhangsan english 63
zhangsan nature 76
lisi chinese 60
lisi math 30
lisi english 78
lisi nature 0
wangwu chinese 89
wangwu math 25
wangwu english 81
wangwu nature 9
转成:
zhangsan chinese:90,math:87,english:63,nature:76
lisi chinese:60,math:30,english:78,nature:0
wangwu chinese:89,math:25,english:81,nature:9
7.4.5.1 准备数据
create table map_temp
as
select name,m_subject,m_score from map1 lateral view explode(score) t1 as m_subject,m_score;
7.4.5.2 开始写:
第一步:将科目和成绩组合在一起,concat
select name,concat(m_subject,':',m_score) as score from map_temp;
第二步: 将所有属于同一个人的数据组合在一起
select name,collect_set(concat(m_subject,":",m_score))
from map_temp
group by name
;
第三步:将数组变成一个字符串concat_ws
select name,concat_ws(",",collect_set(concat(m_subject,":",m_score)))
from map_temp
group by name
;
第四步:将字符串转成map 使用函数str_to_map(text, delimiter1, delimiter2)
text:是字符串
delimiter1:多个键值对之间的分隔符
delimiter2:key和value之间的分隔符
select
name,
str_to_map(concat_ws(",",collect_set(concat(m_subject,":",m_score))),',',':')
from map_temp
group by name
;
第五步:存储准备的表中
create table map2 as
select
name,
str_to_map(concat_ws(",",collect_set(concat(m_subject,":",m_score))),',',':') score
from map_temp
group by name
;
7.5. 复杂数据类型 struct
7.5.1 简介
struct类型,类似于java编程语言中对象实例的模板,即类的结构体。如地址类型的结构体:
public class Address{
String provinces;
String city;
String street;
.......
}
使用struct类型来定义一个字段的类型,语法格式为:
create table tableName(
........
colName struct<subName1:Type,subName2:Type,........>
........
)
调用语法:
colName.subName
7.5.2 案例演示:
1)数据准备
zhangsan 90,87,63,76
lisi 60,30,78,0
wangwu 89,25,81,9
create table if not exists struct1(
name string,
score struct<chinese:int,math:int,english:int,natrue:int>
)
row format delimited
fields terminated by '\t'
collection items terminated by ',';
导入数据:
load data local inpath './data/arr1.txt' into table struct1;
**2)需求:**查询数学大于35分的学生的英语和语文成绩:
select name,
score.english,
score.chinese
from str2
where score.math > 35
;
7.5 综合案例演示
1)数据准备
-- 主管信息表如下:
manager(uid uname belong tax addr)
-- 数据如下:
1 xdd ll,lw,lg,lc,lz wx:600,gongjijin:1200,shebao:450 北京,西城,中南海
2 lkq lw,lg,lc,lz,lq wx:1000,gongjijin:600,shebao:320 河北,石家庄,中山路
3 zs lw,lg,lc wx:2000,gongjijin:300,shebao:10 江西,南昌,八一大道
-- 建表语句:
create table manager_t(
uid int,
uname string,
belong array<string>,
tax map<string,int>,
addr struct<province:string,city:string,street:string>
)
row format delimited
fields terminated by '\t'
collection items terminated by ','
map keys terminated by ':'
;
-- 加载数据
load data local inpath './data/manager_t.txt' into table manager_t;
**2)查询需求:**下属个数大于4个,公积金小于1200,省份在河北的数据
select * from manager_t where size(belong)>4 and tax['gongjijin']<1200 and addr.province='河北';
**扩展说明)**嵌套数据类型
举例说明:map<string,array<map<string,struct>>>
嵌套类型:所有元素分隔符都要自己去定义
默认分隔符:^A 对应输入方式:ctrl+V ctrl+A
第八章 Hive函数
在Hive中,函数主要分两大类型,一种是内置函数,一种是用户自定义函数。
8.1 Hive内置函数
8.1.1 函数查看
show functions;
desc function functionName;
8.1.2 日期函数
1)当前系统时间函数:current_date()、current_timestamp()、unix_timestamp()
-- 函数1:current_date();
当前系统日期 格式:"yyyy-MM-dd"
-- 函数2:current_timestamp();
当前系统时间戳: 格式:"yyyy-MM-dd HH:mm:ss.ms"
-- 函数3:unix_timestamp();
当前系统时间戳 格式:距离1970年1月1日0点的秒数。
2)日期转时间戳函数:unix_timestamp()
格式:unix_timestamp([date[,pattern]])
案例:
select unix_timestamp('1970-01-01 0:0:0'); -- 传入的日期时间是东八区的时间, 返回值是相对于子午线的时间来说的
select unix_timestamp('1970-01-01 8:0:0');
select unix_timestamp('0:0:0 1970-01-01',"HH:mm:ss yyyy-MM-dd");
select unix_timestamp(current_date());
3)时间戳转日期函数:from_unixtime
语法:from_unixtime(unix_time[,pattern])
案例:
select from_unixtime(1574092800);
select from_unixtime(1574096401,'yyyyMMdd');
select from_unixtime(1574096401,'yyyy-MM-dd HH:mm:ss');
select from_unixtime(0,'yyyy-MM-dd HH:mm:ss');
select from_unixtime(-28800,'yyyy-MM-dd HH:mm:ss');
4)计算时间差函数:datediff()、months_between()
格式:datediff(date1, date2) - Returns the number of days between date1 and date2
select datediff('2019-11-20','2019-11-01');
格式:months_between(date1, date2) - returns number of months between dates date1 and date2
select months_between('2019-11-20','2019-11-01');
select months_between('2019-10-30','2019-11-30');
select months_between('2019-10-31','2019-11-30');
select months_between('2019-11-00','2019-11-30');
5)日期时间分量函数:year()、month()、day()、hour()、minute()、second()
案例:
select year(current_date);
select month(current_date);
select day(current_date);
select year(current_timestamp);
select month(current_timestamp);
select day(current_timestamp);
select hour(current_timestamp);
select minute(current_timestamp);
select second(current_timestamp);
select dayofmonth(current_date);
select weekofyear(current_date)
6)日期定位函数:last_day()、next_day()
--月末:
select last_day(current_date)
--下周
select next_day(current_date,'thursday');
7)日期加减函数:date_add()、date_sub()、add_months()
格式:
date_add(start_date, num_days)
date_sub(start_date, num_days)
案例:
select date_add(current_date,1);
select date_sub(current_date,90);
select add_months(current_date,1);
定位案例:
--当月第1天:
select date_sub(current_date,dayofmonth(current_date)-1)
--下个月第1天:
select add_months(date_sub(current_date,dayofmonth(current_date)-1),1)
- 字符串转日期:to_date()
(字符串必须为:yyyy-MM-dd格式)
select to_date('2017-01-01 12:12:12');
9)日期转字符串(格式化)函数:date_format
select date_format(current_timestamp(),'yyyy-MM-dd HH:mm:ss');
select date_format(current_date(),'yyyyMMdd');
select date_format('2017-01-01','yyyy-MM-dd HH:mm:ss');
8.1.3 字符串函数
lower--(转小写)
select lower('ABC');
upper--(转大写)
select upper('abc');
length--(字符串长度,字符数)
select length('abc');
concat--(字符串拼接)
select concat("A", 'B');
concat_ws --(指定分隔符)
select concat_ws('-','a' ,'b','c');
substr--(求子串)
select substr('abcde',3);
split(str,regex)--切分字符串,返回数组。
select split("a-b-c-d-e-f","-");
8.1.4 类型转换函数
cast(value as type) -- 类型转换
select cast('123' as int)+1;
8.1.5 数学函数
round --四舍五入((42.3 =>42))
select round(42.3);
ceil --向上取整(42.3 =>43)
select ceil(42.3);
floor --向下取整(42.3 =>42)
select floor(42.3);
8.1.6 其他常用函数
nvl(value,default value):如果value为null,则使用default value,否则使用本身value.
isnull()
isnotnull()
case when then ....when ...then.. else... end
if(p1,p2,p3)
coalesce(col1,col2,col3...)返回第一个不为空的
8.2 窗口函数(重点)
8.2.1 窗口函数over简介
先来看一下这个需求:求每个部门的员工信息以及部门的平均工资。在mysql中如何实现呢
SELECT emp.*, avg_sal
FROM emp
JOIN (
SELECT deptno
, round(AVG(ifnull(sal, 0))) AS avg_sal
FROM emp
GROUP BY deptno
) t
ON emp.deptno = t.deptno
ORDER BY deptno;
select emp.*,(select avg(ifnull(sal,0)) from emp B where B.deptno = A.deptno )
from emp A;
通过这个需求我们可以看到,如果要查询详细记录和聚合数据,必须要经过两次查询,比较麻烦。
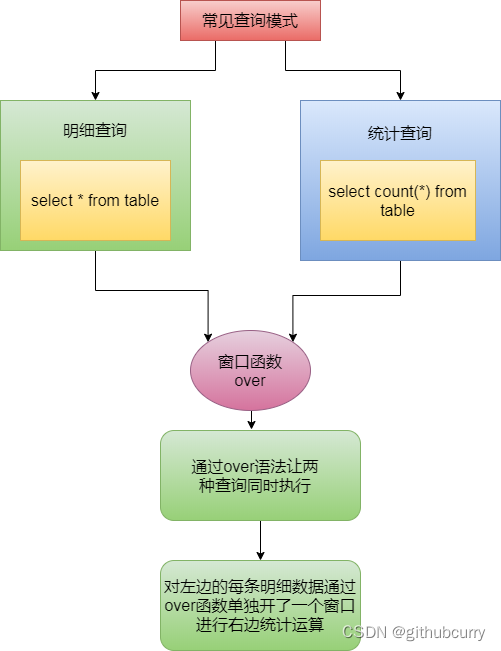
这个时候,我们使用窗口函数,会方便很多。那么窗口函数是什么呢?
-1) 窗口函数又名开窗函数,属于分析函数的一种。
-2) 是一种用于解决复杂报表统计需求的函数。
-3) 窗口函数常用于计算基于组的某种值,它和聚合函数的不同之处是:对于每个组返回多行,而聚合函数对于每个组只返回一行。
简单的说窗口函数对每条详细记录开一个窗口,进行聚合统计的查询
-4) 开窗函数指定了分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变化而变化。
-5) 窗口函数一般不单独使用
-6) 窗口函数内也可以分组和排序
参考下图:
**注意:**默认mysql老版本没有支持,在最新的8.0版本中支持, Oracle和Hive中都支持窗口函数
8.2.2 基本案例演示
数据准备(order.txt)
姓名,购买日期,购买数量
-1. 创建order表:
create table if not exists t_order
(
name string,
orderdate string,
cost int
) row format delimited fields terminated by ',';
-2. 加载数据:
load data local inpath "./data/order.txt" into table t_order;
需求:查询每个订单的信息,以及订单的总数
– 1.不使用窗口函数
-- 查询所有明细
select * from t_order;
# 查询总量
select count(*) from t_order;
– 2.使用窗口函数:通常格式为 可用函数+over()函数
select *, count(*) over() from t_order;
注意:
窗口函数是针对每一行数据的.
如果over中没有指定参数,默认窗口大小为全部结果集
需求:查询在2018年1月份购买过的顾客购买明细及总人数
select *,count(*) over()
from t_order
where substring(orderdate,1,7) = '2018-01';
8.2.3 distribute by子句
在over窗口中进行分组,对某一字段进行分组统计,窗口大小就是同一个组的所有记录
语法:
over(distribute by colname[,colname.....])
需求:查看顾客的购买明细及月购买总额
select name, orderdate, cost, sum(cost) over (distribute by month(orderdate))
from t_order;
saml 2018-01-01 10 205
saml 2018-01-08 55 205
tony 2018-01-07 50 205
saml 2018-01-05 46 205
tony 2018-01-04 29 205
tony 2018-01-02 15 205
saml 2018-02-03 23 23
mart 2018-04-13 94 341
saml 2018-04-06 42 341
mart 2018-04-11 75 341
mart 2018-04-09 68 341
mart 2018-04-08 62 341
neil 2018-05-10 12 12
neil 2018-06-12 80 80
需求:查看顾客的购买明细及每个顾客的月购买总额
select name, orderdate, cost, sum(cost) over (distribute by name, month(orderdate))
from t_order;
mart 2018-04-13 94 299
mart 2018-04-11 75 299
mart 2018-04-09 68 299
mart 2018-04-08 62 299
neil 2018-05-10 12 12
neil 2018-06-12 80 80
saml 2018-01-01 10 111
saml 2018-01-08 55 111
saml 2018-01-05 46 111
saml 2018-02-03 23 23
saml 2018-04-06 42 42
tony 2018-01-07 50 94
tony 2018-01-04 29 94
tony 2018-01-02 15 94
8.2.4 sort by子句
sort by子句会让输入的数据强制排序 (强调:当使用排序时,窗口会在组内逐行变大)
语法: over([distribute by colname] [sort by colname [desc|asc]])
需求:查看顾客的购买明细及每个顾客的月购买总额,并且按照日期降序排序
select name, orderdate, cost,
sum(cost) over (distribute by name, month(orderdate) sort by orderdate desc)
from t_order;
注意:可以使用partition by + order by 组合来代替distribute by+sort by组合
select name, orderdate, cost,
sum(cost) over (partition by name, month(orderdate) order by orderdate desc)
from t_order;
注意:也可以在窗口函数中,只写排序,窗口大小是全表记录。
select name, orderdate, cost,
sum(cost) over (order by orderdate desc)
from t_order;
neil 2018-06-12 80 80 -统计信息会逐行增加
neil 2018-05-10 12 92
mart 2018-04-13 94 186
mart 2018-04-11 75 261
mart 2018-04-09 68 329
mart 2018-04-08 62 391
saml 2018-04-06 42 433
saml 2018-02-03 23 456
saml 2018-01-08 55 511
tony 2018-01-07 50 561
saml 2018-01-05 46 607
tony 2018-01-04 29 636
tony 2018-01-02 15 651
saml 2018-01-01 10 661
8.2.5 Window子句
如果要对窗口的结果做更细粒度的划分,那么就使用window子句,常见的有下面几个
PRECEDING:往前
FOLLOWING:往后
CURRENT ROW:当前行
UNBOUNDED:起点,
UNBOUNDED PRECEDING:表示从前面的起点,
UNBOUNDED FOLLOWING:表示到后面的终点

一般window子句都是rows开头
案例:
select name,orderdate,cost,
sum(cost) over() as sample1,--所有行相加
sum(cost) over(partition by name) as sample2,-- 按name分组,组内数据相加
sum(cost) over(partition by name order by orderdate) as sample3,-- 按name分组,组内数据累加
sum(cost) over(partition by name order by orderdate rows between UNBOUNDED PRECEDING and current row ) as sample4 ,-- 与sample3一样,由起点到当前行的聚合
sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING and current row) as sample5, -- 当前行和前面一行做聚合
sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING AND 1 FOLLOWING ) as sample6,-- 当前行和前边一行及后面一行
sum(cost) over(partition by name order by orderdate rows between current row and UNBOUNDED FOLLOWING ) as sample7 -- 当前行及后面所有行
from t_order;
需求:查看顾客到目前为止的购买总额
select name,
t_order.orderdate,
cost,
sum(cost)
over (partition by name order by orderdate rows between UNBOUNDED PRECEDING and current row ) as allCount
from t_order;
mart 2018-04-08 62 62
mart 2018-04-09 68 130
mart 2018-04-11 75 205
mart 2018-04-13 94 299
neil 2018-05-10 12 12
neil 2018-06-12 80 92
saml 2018-01-01 10 10
saml 2018-01-05 46 56
saml 2018-01-08 55 111
saml 2018-02-03 23 134
saml 2018-04-06 42 176
tony 2018-01-02 15 15
tony 2018-01-04 29 44
tony 2018-01-07 50 94
需求:求每个顾客最近三次的消费总额
select name,orderdate,cost,
sum(cost) over(partition by name order by orderdate rows between 2 preceding and current row)
from t_order;
8.3 序列函数
8.3.1 NTILE
ntile 是Hive很强大的一个分析函数。可以看成是:它把有序的数据集合 平均分配 到 指定的数量(num)个桶中, 将桶号分配给每一行。如果不能平均分配,则优先分配较小编号的桶,并且各个桶中能放的行数最多相差1。
例子:
select name,orderdate,cost,
ntile(3) over(partition by name), # 按照name进行分组,在分组内将数据切成3份
from t_order;
mart 2018-04-13 94 1
mart 2018-04-11 75 1
mart 2018-04-09 68 2
mart 2018-04-08 62 3
neil 2018-06-12 80 1
neil 2018-05-10 12 2
saml 2018-01-01 10 1
saml 2018-01-08 55 1
saml 2018-04-06 42 2
saml 2018-01-05 46 2
saml 2018-02-03 23 3
tony 2018-01-07 50 1
tony 2018-01-02 15 2
tony 2018-01-04 29 3
8.3.2 LAG和LEAD函数
- lag返回当前数据行的前第n行的数据
- lead返回当前数据行的后第n行的数据
需求:查询顾客上次购买的时间
select name,orderdate,cost,
lag(orderdate,1) over(partition by name order by orderdate) as time1
from t_order;
lag(colName,n[,default value]): 取字段的前第n个值。如果为null,显示默认值
select name,orderdate,cost,
lag(orderdate,1,'1990-01-01') over(partition by name order by orderdate ) as time1
from t_order;
取得顾客下次购买的时间
select name,orderdate,cost,
lead(orderdate,1) over(partition by name order by orderdate ) as time1
from t_order;
案例:求5分钟内点击100次的用户
dt id url
2019-08-22 19:00:01,1,www.baidu.com
2019-08-22 19:01:01,1,www.baidu.com
2019-08-22 19:02:01,1,www.baidu.com
2019-08-22 19:03:01,1,www.baidu.com
select id,dt,lag(dt,100) over(partition by id order by dt)
from tablename where dt-lag(dt,100) over(partition by id order by dt)>=5分钟
8.3.3 first_value和last_value
- first_value 取分组内排序后,截止到当前行,第一个值
- last_value 分组内排序后,截止到当前行,最后一个值
案例:
select name,orderdate,cost,
first_value(orderdate) over(partition by name order by orderdate) as time1,
last_value(orderdate) over(partition by name order by orderdate) as time2
from t_order;
select name,orderdate,cost,
first_value(orderdate) over(partition by name order by orderdate) as time1,
first_value(orderdate) over(partition by name order by orderdate desc) as time2
from t_order;
8.4 排名函数
第一种函数:row_number从1开始,按照顺序,生成分组内记录的序列,row_number()的值不会存在重复,当排序的值相同时,按照表中记录的顺序进行排列
效果如下:
98 1
97 2
97 3
96 4
95 5
95 6
没有并列名次情况,顺序递增
第二种函数:RANK() 生成数据项在分组中的排名,排名相等会在名次中留下空位
效果如下:
98 1
97 2
97 2
96 4
95 5
95 5
94 7
有并列名次情况,顺序跳跃递增
第三种函数:DENSE_RANK() 生成数据项在分组中的排名,排名相等会在名次中不会留下空位
效果如下:
98 1
97 2
97 2
96 3
95 4
95 4
94 5
有并列名次情况,顺序递增
准备数据
userid classno score
1 gp1808 80
2 gp1808 92
3 gp1808 84
4 gp1808 86
5 gp1808 88
6 gp1808 70
7 gp1808 98
8 gp1808 84
9 gp1808 86
10 gp1807 90
11 gp1807 92
12 gp1807 84
13 gp1807 86
14 gp1807 88
15 gp1807 80
16 gp1807 92
17 gp1807 84
18 gp1807 86
19 gp1805 80
20 gp1805 92
21 gp1805 94
22 gp1805 86
23 gp1805 88
24 gp1805 80
25 gp1805 92
26 gp1805 94
27 gp1805 86
create table if not exists stu_score(
userid int,
classno string,
score int
)
row format delimited
fields terminated by ' ';
load data local inpath './data/stu_score.txt' overwrite into table stu_score;
需求1:对每次考试按照考试成绩倒序
select *,
row_number() over(partition by classno order by score desc) rn1
from stu_score;
select *,
rank() over(partition by classno order by score desc) rn2
from stu_score;
select *,
dense_rank() over(distribute by classno sort by score desc) rn3
from stu_score;
select *,
dense_rank() over(order by score desc) `全年级排名`
from stu_score;
需求2:获取每次考试的排名情况
select *,
-- 没有并列,相同名次依顺序排
row_number() over(distribute by classno sort by score desc) rn1,
-- rank():有并列,相同名次空位
rank() over(distribute by classno sort by score desc) rn2,
-- dense_rank():有并列,相同名次不空位
dense_rank() over(distribute by classno sort by score desc) rn3
from stu_score;
需求3:求每个班级的前三名
select *
from
(
select *,
row_number() over(partition by classno order by score desc) rn1
from stu_score
) A
where rn1 < 4;
8.5 自定义函数
8.5.1 自定义函数介绍
hive的内置函数满足不了所有的业务需求。hive提供很多的模块可以自定义功能,比如:自定义函数、serde、输入输出格式等。而自定义函数可以分为以下三类:
1)UDF:user defined function
用户自定义函数,一对一的输入输出 (最常用的)。
2)UDAF:user defined aggregation function
用户自定义聚合函数,多对一的输入输出,比如:count sum max。
- UDTF:user defined table-generate function
用户自定义表生产函数 一对多的输入输出,比如:lateral view explode
8.5.2 自定义UDF函数案例
1)准备工作和注意事项
在pom.xml,加入以下maven的依赖包
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>2.1.1</version>
</dependency>
定义UDF函数要注意下面几点:
1. 继承org.apache.hadoop.hive.ql.exec.UDF
2. 编写evaluate(),这个方法不是由接口定义的,因为它可接受的参数的个数,数据类型都是不确定的。Hive会检查UDF,看能否找到和函数调用相匹配的evaluate()方法
8.5.3 案例1-实现将小写字母转换成大写
8.5.4 函数加载方式
第一种:命令加载 (只针对当前session有效)
1. 将编写好的UDF打包并上传到服务器,将jar包添加到hive的classpath中
hive> add jar /data/first.jar;
2. 创建一个自定义的临时函数名
hive> create temporary function myUpper as 'com.qf.hive.udf.FirstUDF';
3. 查看我们创建的自定义函数,
hive> show functions;
4.在hive中使用函数进行功能测试
hive> select myupper('a');
5. 如何删除自定义函数?在删除一个自定义函数的时候一定要确定该函数没有调用
hive> drop temporary function if exists myupper;
第二种方式:启动参数加载 (只对当前session有效):
1. 将编写好的自定函数上传到服务器
2. 写一个配置文件,将添加函数的语句写入配置文件中,hive在启动的时候加载这个配置文件
[root@qianfeng01 ~]# vi $HIVE_HOME/conf/hive-init
文件中的内容如下
add jar /data/first.jar;
create temporary function myUpper as 'com.qf.hive.udf.FirstUDF';
3. 启动hive时
[root@qianfeng01 ~]# hive -i $HIVE_HOME/conf/hive-init
第三种方式:配置文件加载 (只要用hive命令行启动都会加载函数)
1、将编写好的自定函数上传到服务器
2、在hive的安装目录下的bin目录中创建一个文件,文件名为.hiverc
[root@qianfeng01 hive]# vi ./bin/.hiverc
3、将添加函数的语句写入这文件中
vi $HIVE_HOME/bin/.hiverc
add jar /data/first.jar;
create temporary function myUpper as 'com.qf.hive.udf.FirstUDF';
4、直接启动hive
8.5.5 案例2-把生日转换成年纪
- 思路分析:
1. age=当前年-生日的年份
2. 判断月份,当前月份小于生日月份,age-1
3. 月份相等,判断当前的日期,如果日期小于生日日期,age-1
- 代码实现:
public class Birthday2Age extends UDF {
public int evaluate(String birth) {
// 1、判断参数
if (StringUtils.isEmpty(birth)) {
return -1;
}
// 拆分生日,获取年月日
String[] birthdays = birth.split("-");
// 得到生日年月日
int birthYear = Integer.parseInt(birthdays[0]);
int birthMonth = Integer.parseInt(birthdays[1]);
int birthDay = Integer.parseInt(birthdays[2]);
// 获取当前时间
Calendar calendar = Calendar.getInstance();
int nowYear = calendar.get(Calendar.YEAR);
int nowMonth = calendar.get(Calendar.MONTH) + 1;
int nowDay = calendar.get(Calendar.DAY_OF_MONTH);
// 计算年龄
int age = nowYear - birthYear;
// 判断月份和日期
if (nowMonth < birthMonth) {
age -= 1;
} else if (nowMonth == birthMonth && nowDay < birthDay) {
age -= 1;
}
return age;
}
public static void main(String[] args) {
System.out.println(new Birthday2Age().evaluate("1980-03-31"));
}
}
- 测试:
1. 导入自定义函数
add jar ./data/birth.jar;
create temporary function birth2age as 'com.qf.bigdata.hiveudf.Birthday2Age';
2. 测试
8.5.6 案例3-根据key获取value
- 数据准备:
sex=1&hight=180&weight=100&sal=2000000
输入:sal
输出:2000000
- 实现思路:
1. 将这种输入字符串转换成json格式的字符串{sex:1,hight:180,weight:100,sal:2000000}
2. 构建一个json的解析器
3. 根据key获取value
- 代码如下:
public class Key2Value extends UDF {
public String evaluate(String str, String key) throws JSONException {
// 1、判断参数
if (StringUtils.isEmpty(str) || StringUtils.isEmpty(key)) {
return null;
}
// 将str转换成json格式
// sex=1&hight=180&weight=130&sal=28000
// {'sex':1,'hight':180,'weight':130,'sal':28000}
String s1 = str.replace("&", ",");
String s2 = s1.replace("=", ":");
String s3 = "{" + s2 + "}";
// 使用尽送对象解析json串
JSONObject jo = new JSONObject(s3);
return jo.get(key).toString();
}
public static void main(String[] args) throws JSONException {
System.out.println(new Key2Value().evaluate("sex=1&hight=180&weight=130&sal=28000&faceId=189", "faceId"));
}
}
8.5.7 案例4-正则表达式解析日志
- 数组准备:
220.181.108.151 - - [31/Jan/2012:00:02:32 +0800] "GET /home.php?mod=space&uid=158&do=album&view=me&from=space HTTP/1.1" 200 8784 "-" "Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)"
输出内容: 220.181.108.151 20120131 120232 GET /home.php?mod=space&uid=158&do=album&view=me&from=space HTTP 200 Mozilla
String reg ="^([0-9.]+\d+) - - \[(.+ \+\d+)\] .+(GET|POST) (.+) (HTTP)\S+ (\d+).+\\"(\w+).+$";
- 解决思路:
1. 定义一个正则表达式、获取匹配器
2. 匹配输入的字符串,将字符串分组
3. 如果能够匹配的上,将需要的字符串分组拼接起来,返回
- 代码实现:
public class LogParser extends UDF {
public String evaluate(String log) throws ParseException, Exception {
// 1
if (StringUtils.isEmpty(log)) {
return null;
}
// 220.181.108.151 - - [31/Jan/2012:00:02:32 +0800] \"GET
// /home.php?mod=space&uid=158&do=album&view=me&from=space HTTP/1.1\" 200 8784
// \"-\" \"Mozilla/5.0 (compatible; Baiduspider/2.0;
// +http://www.baidu.com/search/spider.html)\"
// 220.181.108.151 20120131 120232 GET
// /home.php?mod=space&uid=158&do=album&view=me&from=space HTTP 200 Mozilla
// 定义一个正则表达式
String reg = "^([0-9.]+\\d+) - - \\[(.* \\+\\d+)\\] .+(GET|POST) (.+) (HTTP)\\S+ (\\d+) .+\\\"(\\w+).+$";
// 获取一个模式匹配器
Pattern pattern = Pattern.compile(reg);
// 匹配结果
Matcher matcher = pattern.matcher(log);
//
StringBuffer sb = new StringBuffer();
// 判断数据是否匹配上
if (matcher.find()) {
// 先获取匹配的段数
int count = matcher.groupCount();
// 循环获取每段的内容,并且将内容拼接起来
for (int i = 1; i <= count; i++) {
// 判断字段是否是时间字段,如果是,则做时间格式转换
if (i == 2) {
// 定义一个时间格式来解析当前时间
Date d = new SimpleDateFormat("dd/MMM/yyyy:HH:mm:ss Z", Locale.ENGLISH).parse(matcher.group(i));
// 定义输出的时间格式
SimpleDateFormat sdf = new SimpleDateFormat("yyyyMMdd hhmmss");
// 将时间格式转换成输出格式,并输出
sb.append(sdf.format(d) + "\t");
} else {
sb.append(matcher.group(i) + "\t");
}
}
}
return sb.toString();
}
public static void main(String[] args) throws Exception {
System.out.println(new LogParser().evaluate(
"220.181.108.151 - - [31/Jan/2012:00:02:32 +0800] \\\"GET /home.php?mod=space&uid=158&do=album&view=me&from=space HTTP/1.1\\\" 200 8784 \\\"-\\\" \\\"Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)\\\""));
}
}
create table log100(
log string
);
load data local inpath './data/access.log' into table log100;
8.5.8 案例5-Json数据解析UDF开发
1) 数据准备:
有原始json数据如下:
{"movie":"1193","rate":"5","datetime":"978300760","uid":"1"}
{"movie":"661","rate":"3","datetime":"978302109","uid":"1"}
{"movie":"914","rate":"3","datetime":"978301968","uid":"1"}
{"movie":"3408","rate":"4","datetime":"978300275","uid":"1"}
{"movie":"2355","rate":"5","datetime":"978824291","uid":"1"}
{"movie":"1197","rate":"3","datetime":"978302268","uid":"1"}
{"movie":"1287","rate":"5","datetime":"978302039","uid":"1"}
参考数据文件:rating.json
最终形成hive表中这样的数据
movie rate datetime uid
1197 3 978302268 1
2) 将原始数据导入到hive库,先创建一个单字段的表
create table if not exists movie_json
(json string);
load data local inpath './data/rating.json' into table moive_json;
3)写一个自定义函数,利用自定义函数解析json,将json串解析一个以\t分割的字符串,并上传使用
public class JsonParser extends UDF{
private Logger logger = Logger.getLogger(JsonParser.class);
public String evaluate(String json) {
//判断传入参数
if(Strings.isNullOrEmpty(json)){
return null;
}
ObjectMapper objectMapper = new ObjectMapper();
try {
RateBean bean = objectMapper.readValue(json, RateBean.class);
return bean.toString();
} catch (IOException e) {
logger.error("解析json串失败!!",e);
}
return null;
}
public static void main(String[] args) {
System.out.println(new JsonParser().evaluate("{\"movie\":\"1193\",\"rate\":\"5\",\"datetime\":\"978300760\",\"uid\":\"1\"}"));
}
}
RateBean类型:
package com.qf.mr.rate;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* 定义一个类型,封装电影评分信息
* {"movie":"1193","rate":"5","datetime":"978300760","uid":"1"}
* 属性:movie、rate、datetime、uid
*/
public class RateBean implements WritableComparable<RateBean> {
private int uid;
private int movie;
private int rate;
private long datetime;
public RateBean(){
}
public RateBean(int uid, int movie, int rate, long datetime) {
this.uid = uid;
this.movie = movie;
this.rate = rate;
this.datetime = datetime;
}
public int getUid() {
return uid;
}
public void setUid(int uid) {
this.uid = uid;
}
public int getMovie() {
return movie;
}
public void setMovie(int movie) {
this.movie = movie;
}
public int getRate() {
return rate;
}
public void setRate(int rate) {
this.rate = rate;
}
public long getDatetime() {
return datetime;
}
public void setDatetime(long datetime) {
this.datetime = datetime;
}
/**
* 定义排序规则:
* 使用集合来封装每一个uid的所有电影信息
* 所以只需要使用rate进行降序排序即可。
* @param o
* @return
*/
public int compareTo(RateBean o) {
return o.rate-this.rate;
}
public void write(DataOutput out) throws IOException {
out.writeInt(uid);
out.writeInt(movie);
out.writeInt(rate);
out.writeLong(datetime);
}
public void readFields(DataInput in) throws IOException {
uid = in.readInt();
movie = in.readInt();
rate = in.readInt();
datetime = in.readLong();
}
public String toString(){
return movie +"\t"+rate+"\t"+datetime+"\t"+uid;
}
}
- 不使用中间表,直接克隆一张新表进行存储数据
drop table movie_rate;
create table if not exists movie_rate
as
select
split(jsonParser(json),'\t')[0] as movie,
split(jsonParser(json),'\t')[1] as rate,
split(jsonParser(json),'\t')[2] as times,
split(jsonParser(json),'\t')[3] as uid
from movie_json;
5) 借助中间表的写法
第一步:insert into select func()将数据插入临时表
create table if not exists t_json_tmp
as
select jsonParser(json) as jsonLine from movie_json;
第二步: 用split函数从临时表中解析出字符串中各个字段存入到最终结果表
create table if not exists t_movieRate
as
select
split(jsonLine,'\t')[0] as movie,
split(jsonLine,'\t')[1] as rate,
split(jsonLine,'\t')[2] as times,
split(jsonLine,'\t')[3] as uid
from t_json_tmp;
8.5.9 内置的json解析函数:
select get_json_object(json,"$.movie") movie,
get_json_object(json,"$.rate") rate,
get_json_object(json,"$.datetime") datetime,
get_json_object(json,"$.uid") uid
from movie_json;
第九章 分区表的相关内容
9.1 分区简介
9.1.1 为什么分区
Hive的Select查询时,一般会扫描整个表内容。随着系统运行的时间越来越长,表的数据量越来越大,而hive查询做全表扫描,会消耗很多时间,降低效率。而有时候,我们需求的数据只需要扫描表中的一部分数据即可。这样,hive在建表时引入了partition概念。即在建表时,将整个表存储在不同的子目录中,每一个子目录对应一个分区。在查询时,我们就可以指定分区查询,避免了hive做全表扫描,从而提高查询效率。
9.1.2 如何分区
根据业务需求而定,不过通常以年、月、日、小时、地区等进行分区。
9.1.3 分区的语法
create table tableName(
.......
.......
)
partitioned by (colName colType [comment '...'],...)
9.1.4 分区的注意事项
- hive的分区名不区分大小写,不支持中文
- hive的分区字段是一个伪字段,但是可以用来进行操作
- 一张表可以有一个或者多个分区,并且分区下面也可以有一个或者多个分区。
- 分区是以字段的形式在表结构中存在,通过describe table命令可以查看到字段存在,但是该字段不存放实际的数据内容,仅仅是分区的表示。
9.1.5 分区的意义
让用户在做数据统计的时候缩小数据扫描的范围,在进行select操作时可以指定要统计哪个分区
9.1.6 分区的本质
在表的目录或者是分区的目录下在创建目录,分区的目录名为指定字段=值
9.2 分区案例
9.2.1 一级分区的使用
1) 建表语句
create table if not exists part1(
id int,
name string,
age int
)
partitioned by (dt string)
row format delimited
fields terminated by '\t'
lines terminated by '\n';
2) 加载数据
load data local inpath './data/user1.txt' into table part1 partition(dt='2020-05-05');
load data local inpath './data/user2.txt' into table part1 partition(dt='2020-05-06');
9.2.2 二级分区的使用
1) 建表语句
create table if not exists part2(
id int,
name string,
age int
)
partitioned by (year string,month string)
row format delimited
fields terminated by '\t';
2) 加载数据
load data local inpath './data/user1.txt' into table part2 partition(year='2020',month='03');
load data local inpath './data/user2.txt' into table part2 partition(year='2020',month=04);
load data local inpath './data/user2.txt' into table part2 partition(year='2020',month="05");
9.2.3 三级分区的使用
1) 建表语句
create table if not exists part3(
id int,
name string,
age int
)
partitioned by (year string,month string,day string)
row format delimited
fields terminated by '\t';
2)加载数据
load data local inpath './data/user1.txt' into table part3 partition(year='2020',month='05',day='01');
load data local inpath './data/user2.txt' into table part3 partition(year='2019',month='12',day='31');
9.2.4 测试是否区分大小写
在hive中,分区字段名是不区分大小写的,不过字段值是区分大小写的。我们可以来测试一下
1) 建表语句
create table if not exists part4(
id int,
name string
)
partitioned by (year string,month string,DAY string)
row format delimited fields terminated by ','
;
--测试字段名的大小写,结果不区分。
2) 加载数据
load data local inpath './data/user1.txt' into table part4 partition(year='2018',month='03',DAy='21');
load data local inpath './data/user2.txt' into table part4 partition(year='2018',month='03',day='AA');
--测试字段值的大小写,结果是区分的。
9.2.5 查看分区:
语法:
show partitions tableName
eg:
show partitions part4;
9.2.6 修改分区:
修改分区 (注意:location后接的hdfs路径需要写成完全路径)
alter table part3 partition(year='2019',month='10',day='23') set location '/user/hive/warehouse/mydb1.db/part1/dt=2018-03-21'; --错误使用
#:修改分区,指的是修改分区字段值对应的映射位置。
alter table part3 partition(year='2020',month='05',day='01') set location 'hdfs://qianfeng01:8020/user/hive/warehouse/mydb.db/part1/dt=2020-05-05';
9.2.7 增加分区
1)新增分区(空)
alter table part3 add partition(year='2020',month='05',day='02');
alter table part3 add partition(year='2020',month='05',day='03') partition(year='2020',month='05',day='04');
2)新增分区 (带数据)
alter table part3 add partition(year='2020',month='05',day='05') location '/user/hive/warehouse/mydb.db/part1/dt=2020-05-06';
3) 新增多分区
alter table part3 add
partition(year='2020',month='05',day='06') location '/user/hive/warehouse/mydb.db/part1/dt=2020-05-05'
partition(year='2020',month='05',day='07') location '/user/hive/warehouse/mydb.db/part1/dt=2020-05-06';
9.2.8 删除分区
1)删除单个分区
alter table part3 drop partition(year='2020',month='05',day='07');
2)删除多个分区
alter table part3 drop partition(year='2020',month='05',day='06'),partition(year='2020',month='05',day='06');
- 测试分区表的分区都被删除的特点
create table if not exists part10(
id int,
name string,
age int
)
partitioned by (year string,month string,day string)
row format delimited
fields terminated by '\t';
load data local inpath './data/user1.txt' overwrite into table part10
partition(year='2020',month='05',day='06');
load data local inpath './data/user2.txt' overwrite into table part10
partition(year='2020',month='05',day='07');
删除分区:
alter table part10 drop
partition(year='2020',month='05',day='06'),
partition(year='2020',month='05',day='07');
注意: 默认创建分区表时,删除所有分区时,表目录不会被删除。
测试2: 使用location关键字去指定分区对应的位置
alter table part10 add partition(year='2020',month='05',day='08') location '/test/a/b';
alter table part10 add partition(year='2020',month='05',day='09') location '/test/a/c';
alter table part10 drop
partition(year='2020',month='05',day='08'),
partition(year='2020',month='05',day='09');
结论:在删除操作时,对应的目录(最里层)会被删除,上级目录如果没有文件存在,也会被删除,如果有文件存在,则不会被删除。
9.3 分区类型详解
9.3.1 分区的种类
1. 静态分区:直接加载数据文件到指定的分区,即静态分区表。
2. 动态分区:数据未知,根据分区的值来确定需要创建的分区(分区目录不是指定的,而是根据数据的值自动分配的)
3. 混合分区:静态和动态都有。
9.3.2 分区属性设置
hive.exec.dynamic.partition=true,是否支持动态分区操作
hive.exec.dynamic.partition.mode=strict/nonstrict: 严格模式/非严格模式
hive.exec.max.dynamic.partitions=1000: 总共允许创建的动态分区的最大数量
hive.exec.max.dynamic.partitions.pernode=100:in each mapper/reducer node
9.3.3 创建动态分区的案例
1)创建动态分区表
create table dy_part1(
sid int,
name string,
gender string,
age int,
academy string
)
partitioned by (dt string)
row format delimited fields terminated by ','
;
2)动态分区加载数据
下面方式不要用,因为不是动态加载数据
load data local inpath '/hivedata/user.txt' into table dy_part1 partition(dt='2020-05-06');
正确方式:要从别的表中加载数据
**第一步:**先创建临时表:
create table temp_part1(
sid int,
name string,
gender string,
age int,
academy string,
dt string
)
row format delimited
fields terminated by ','
;
注意:创建临时表时,必须要有动态分区表中的分区字段。
**第二步:**导入数据到临时表:
95001,李勇,男,20,CS,2017-8-31
95002,刘晨,女,19,IS,2017-8-31
95003,王敏,女,22,MA,2017-8-31
95004,张立,男,19,IS,2017-8-31
95005,刘刚,男,18,MA,2018-8-31
95006,孙庆,男,23,CS,2018-8-31
95007,易思玲,女,19,MA,2018-8-31
95008,李娜,女,18,CS,2018-8-31
95009,梦圆圆,女,18,MA,2018-8-31
95010,孔小涛,男,19,CS,2017-8-31
95011,包小柏,男,18,MA,2019-8-31
95012,孙花,女,20,CS,2017-8-31
95013,冯伟,男,21,CS,2019-8-31
95014,王小丽,女,19,CS,2017-8-31
95015,王君,男,18,MA,2019-8-31
95016,钱国,男,21,MA,2019-8-31
95017,王风娟,女,18,IS,2019-8-31
95018,王一,女,19,IS,2019-8-31
95019,邢小丽,女,19,IS,2018-8-31
95020,赵钱,男,21,IS,2019-8-31
95021,周二,男,17,MA,2018-8-31
95022,郑明,男,20,MA,2018-8-31
load data local inpath './data/student2.txt' into table temp_part1;
**第三步:**动态加载到表
insert into dy_part1 partition(dt) select sid,name,gender,age,academy,dt from temp_part1;
注意:严格模式下,给动态分区表导入数据时,分区字段至少要有一个分区字段是静态值
非严格模式下,导入数据时,可以不指定静态值。
9.3.4 混合分区示例
1) 创建一个分区表:
create table dy_part2(
id int,
name string
)
partitioned by (year string,month string,day string)
row format delimited fields terminated by ','
;
2) 创建临时表
create table temp_part2(
id int,
name string,
year string,
month string,
day string
)
row format delimited fields terminated by ','
;
数据如下:
1,廉德枫,2019,06,25
2,刘浩(小),2019,06,25
3,王鑫,2019,06,25
5,张三,2019,06,26
6,张小三,2019,06,26
7,王小四,2019,06,27
8,夏流,2019,06,27
load data local inpath './data/temp_part2.txt' into table temp_part2;
3) 导入数据到分区表
- 错误用法:
insert into dy_part2 partition (year='2019',month,day)
select * from temp_part2;
- 正确用法:
insert into dy_part2 partition (year='2020',month,day)
select id,name,month,day from temp_part2;
4) 分区表注意事项
1. hive的分区使用的是表外字段,分区字段是一个伪列,但是分区字段是可以做查询过滤。
2. 分区字段不建议使用中文
3. 一般不建议使用动态分区,因为动态分区会使用mapreduce来进行查询数据,如果分区数据过多,导致namenode和resourcemanager的性能瓶颈。所以建议在使用动态分区前尽可能预知分区数量。
4. 分区属性的修改都可以修改元数据和hdfs数据内容。
5) Hive分区和Mysql分区的区别
mysql分区字段用的是表内字段;而hive分区字段采用表外字段。
第十章 序列化和反序列化
10.1 文件读取/解析的方式
create table t1(
id int,
name string
)
row format delimited
fields terminated by ','
;
0,7369,SMITH,CLERK,7902,1980-12-17,800,null,20
从文件里进行查询时,会不会在内存里产生hive的相关对象啊
select * from student;
一行记录一行记录的显示。
select过程 磁盘上的数据--->row对象 <------反序列化 InputFormat
insert过程 row对象---->磁盘上的数据 <-----序列化 OutputFormat
在建表语句中,指定了记录的切分格式以及字段的切分符号。实际上,hive在解析文件的时候,涉及到了两个类型。
1. 一个类用于从文件中读取一条一条的记录(根据记录分隔符确定一条记录)
row format: 用于指定使用什么格式解析一行的数据
delimited : 表示使用 org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe 进行行的内容解析
2. 一个类用于从上面读到的记录中切分出一个一个的字段(根据指定字符作为分隔符)
fields terminated by: 表示用什么字符进行字段之间的分隔
lines terminated by: 表示用什么字符进行行之间的分隔
强调:hive在select时,这个过程是将字节序列转成hive中的java对象。
hive在insert时,这个过程是将hive中的java对象转成字节序列。
10.2 Serde简介
10.2.1 概念
- SerDe是“Serializer and Deserializer”的简称。
- Hive使用SerDe(和FileFormat)来读/写表的Row对象。
- HDFS文件-> InputFileFormat -> <key,value> -> Deserializer -> Row对象
- Row对象->Serializer -> <key,value> -> OutputFileFormat -> HDFS文件
注意,“key”部分在读取时会被忽略,而在写入时始终是常数。基本上Row对象存储在“值”中。
注意,org.apache.hadoop.hive.serde是一个过时的SerDe库。使用最新版本的org.apache.hadoop.hive.serde2。
可参考官网:https://cwiki.apache.org/confluence/display/Hive/DeveloperGuide#DeveloperGuide-HiveSerDe
10.2.2 常用的Serde
- csv: 逗号分隔值
- tsv: tab分隔值
- json: json格式的数据
- regexp: 数据需要复合正则表达式
10.3 LazySimpleSerDe
10.3.1 Hive分隔符
- 行分隔符:\n
- 列分隔符:^A
在Hive中,建表时一般用来来指定字段分隔符和列分隔符。一般导入的文本数据字段分隔符多为逗号分隔符或者制表符(但是实际开发中一般不用着这种容易在文本内容中出现的的符号作为分隔符),当然也有一些别的分隔符,也可以自定义分隔符。有时候也会使用hive默认的分隔符来存储数据。在建表时通过下面语法来指定:
ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' -- 指定列分隔符
LINES TERMINATED BY '\n' -- 指定行分隔符
默认情况下行分隔符是\n, 列分隔符一般是不容易在文本中出现的字符,开发中大部分用TAB,但有时候TAB也有可能重复,这时候可以使用Hive的默认分隔符的.
hive中默认使用^A(ctrl+A)作为列分割符,如果用户需要指定的话,等同于row format delimited fields terminated by '\001',因为^A八进制编码体现为'\001'.所以如果使用默认的分隔符,可以什么都不加,也可以按照上面的指定加‘\001’为列分隔符,效果一样。
hive默认使用的行分隔符是'\n'分隔符 ,默认是通过row format delimited fields terminated by '\t'这个语句来指定不同的分隔符,但是hive不能够通过LINES TERMINATED BY '$$'来指定行分隔符,目前为止,hive的默认行分隔符仅支持‘\n’字符。
10.3.2 数据样本
1001^Azs^A23
1002^Alis^A24
10.3.3 建表
create table if not exists csv1(
uid int,
uname string,
age int
); -- 格式都没有指定,默认使用的就是LazySimpleSerde,记录分隔符是\n,列分隔符是^A
10.3.4 导入数据
load data local inpath './data/csv1.txt' overwrite into table csv1;
10.4 CSV
10.4.1 分隔符:
列分隔符:逗号
CSV格式的文件也称为逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可
以不是逗号。),其文件以纯文本形式存储表格数据(数字和文本)。CSV文件由任意数目的记录组成,记录间以换行符分隔;每条记录由字段组成,字段间的分隔符是其它字符或字符串,最常见的是逗号或制表符。通常,所有记录都有完全相同的字段序列。
在CSV的Serde中有以下三个默认属性
1. 默认转义字符(DEFAULT_ESCAPE_CHARACTER): \ <--反斜线
2. 默认引用字符(DEFAULT_QUOTE_CHARACTER): " <--双引号
3. 默认分隔符(DEFAULT_SEPARATOR): , <-逗号
10.4.2 数据样本
1001,zs,23
1002,lis,24
10.4.3 建表
drop table csv2;
create table if not exists csv2(
uid int,
uname string,
age int
)
row format serde 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
;
10.4.4 导入数据:
load data local inpath './data/csv2.txt' into table csv2;
10.4.5 自定义字段分隔符、字段引用字符、转义字符
如果不想使用默认分隔符的话,可以使用自定义分隔符,原理其实就是向底层的API的方法的参数中传入指定分隔值
可以指定字段分隔符、字段引用字符、转义字符
create table csv3(
uid int,
uname string,
age int
)
row format serde 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
with serdeproperties(
"separatorChar"="7",
"qutoeChar"="'",
"escapeChar"="\\")
stored as textfile
;
load data local inpath './data/csv3.txt' into table csv3;
10.5 json serde :
10.5.1 说明
- json serde 可以是自己写的jar包也可以是第三方的jar包
- 要把这种jar包添加到hive的class path中
- add jar ./data/json-serde-1.3-jar-with-dependencies.jar;
10.5.2 准备数据
{"uid":"1","uname":"gaoyuanyuan","age":"18"}
{"uid":"2","uname":"gaojianzheng","age":"42"}
10.5.3 建表语句
drop table json1;
create table if not exists json1(
uid int,
uname string,
age int
)
row format serde 'org.openx.data.jsonserde.JsonSerDe'
stored as textfile
;
10.5.4 导入数据
load data local inpath './data/json1.txt' into table json1;
10.6 复杂类型的使用:
10.6.1 数据准备:
zs math:100,98,76 chinese:98,96,100 english:100,99,90
ls math:60,80,70 chinese:90,66,91 english:50,51,70
create table t1(
uname string,
score map<string,array<int>>,
)
row format delimited
fields terminated by ' '
map keys terminiated by ':'
collection items terminated by','
----上述的表语句需要执行map的元素分隔符,还要指定数组的元素分隔符,都用到了collection.因此一个collection无法指定多个分割符。这种情况,只能换思路,使用比较合适的serde去导入数据(jsonSerde最适合)
可以使用编程语言转成下面json字符串
{"uname":"zs","score":{"math":[100,98,76],"chinese":[98,96,100],"english":[100,99,90]}}
{"uname":"ls","score":{"math":[60,80,70],"chinese":[90,66,91],"english":[50,51,70]}}
10.6.2 建表:
create table if not exists complex(
uname string,
score map<String,array<int>>
)
row format serde 'org.openx.data.jsonserde.JsonSerDe'
stored as textfile
;
10.6.3 导入数据:
load data local inpath './data/json2.txt' into table complex;
10.7 Regex Serde
10.7.1 数据准备
01||zhangsan||23
02||lisi||24
10.7.2 说明
hive默认情况下只支持单字节分隔符,如果数据中的分隔符是多字节的,则hive默认是处理不了的。需要使用正则Serde
10.7.3 建表
create table if not exists t_regex(
id string,
uname string,
age int
)
row format serde 'org.apache.hadoop.hive.serde2.RegexSerDe'
with serdeproperties(
'input.regex'='(.*)\\|\\|(.*)\\|\\|(.*)',
'output.format.string'='%1$s %2$s %3$s'
)
stored as textfile
;
10.7.4 导入数据
load data local inpath './data/regex.txt' into table t_regex;
第十一章 Hive存储格式
11.1 hive的存储格式
hive的存储格式分为两大类:一类纯文本文件,一类是二进制文件存储。
第一类: 纯文本文件存储
textfile: 纯文本文件存储格式,不压缩,也是hive的默认存储格式,磁盘开销大,数据解析开销大
第二类:二进制文件存储
- sequencefile:
会压缩,不能使用load方式加载数据
- parquet:
会压缩,不能使用load方式加载数据
- rcfile:
会压缩,不能load。查询性能高,写操作慢,所需内存大,计算量大。此格式为行列混合存储,hive在该格式
下,会尽量将附近的行和列的块存储到一起。
- orcfile:rcfile的升级版
11.2 存储格式的配置项
<property>
<name>hive.default.fileformat</name>
<value>TextFile</value>
<description>
Expects one of [textfile, sequencefile, rcfile, orc].
Default file format for CREATE TABLE statement. Users can explicitly override it by CREATE TABLE ... STORED AS [FORMAT]
</description>
</property>
11.3 案例测试:
11.3.1 案例1:textfile
create external table if not exists stocks_1 (
exchange1 string,
symbol string,
ymd string,
price_open float,
price_high float,
price_low float,
price_close float,
volume int,
price_adj_close float
)
row format delimited
fields terminated by ','
stored as textfile;
load data local inpath './data/stocks.csv' into table stocks_1;
在linux的命令行上使用hdfs dfs -put方法去上传到指定目录下。
11.3.2 案例2: sequencefile
create external table if not exists stocks_seq_1 (
exchange1 string,
symbol string,
ymd string,
price_open float,
price_high float,
price_low float,
price_close float,
volume int,
price_adj_close float
)
row format delimited
fields terminated by ','
stored as sequencefile
;
使用insert into的方式加载数据
from stocks_1
insert into stocks_seq_1 select *
;
或者使用克隆的方式:
create table stocks_seq_2 stored as sequencefile as select * from stocks_1;
11.3.3 案例3:parquet
create external table if not exists stocks_parquet (
exchange1 string,
symbol string,
ymd string,
price_open float,
price_high float,
price_low float,
price_close float,
volume int,
price_adj_close float
)
row format delimited
fields terminated by ','
stored as parquet
;
使用insert into的方式加载数据
from stocks_1
insert into stocks_parquet select *
;
或者使用克隆的方式:
create table stocks_parquet_1 stored as parquet as select * from stocks_1;
11.3.4 案例4:rcfile
create external table if not exists stocks_rcfile (
exchange1 string,
symbol string,
ymd string,
price_open float,
price_high float,
price_low float,
price_close float,
volume int,
price_adj_close float
)
row format delimited
fields terminated by ','
stored as rcfile
;
使用insert into的方式加载数据
from stocks_1
insert into stocks_rcfile select *
;
或者使用克隆的方式:
create table stocks_rcfile_2 stored as rcfile as select * from stocks_1;
11.3.5 案例5:orcfile
create external table if not exists stocks_orcfile (
exchange1 string,
symbol string,
ymd string,
price_open float,
price_high float,
price_low float,
price_close float,
volume int,
price_adj_close float
)
row format delimited
fields terminated by ','
stored as orcfile
;
使用insert into的方式加载数据
from stocks_1
insert into stocks_orcfile select *
;
或者使用克隆的方式:
create table stocks_orcfile_2 stored as orcfile as select * from stocks_1;
11.4 测试性能:
select count(*) from stocks_1;
select count(*) from stocks_seq_1;
select count(*) from stocks_parquet;
select count(*) from stocks_rcfile;
select count(*) from stocks_orcfile;
比较一下上述五个查询所需要的时间
第十二章 Hive索引与视图
12.1 索引
12.1.1 概要
- 0.7版本之后hive支持索引
- 优点:提高查询效率,避免全表扫描
- 缺点:冗余存储,加载数据较慢
- 索引文件的特点:索引数据有序,并且数据量较小
- 索引的关键字:index
12.1.2 索引的创建
- 创建表并加载数据
drop table rate;
create table if not exists rate(
movie string,
rate string,
datetime string,
uid string
)
row format serde 'org.openx.data.jsonserde.JsonSerDe'
stored as textfile
;
hive> add jar ./data/json-serde-1.3-jar-with-dependencies.jar
hive> load data local inpath './data/rating.json' into table rate;
-- 克隆一个表rate1
create table if not exists rate1
as
select * from rate
;
-- 克隆一个表rate2
create table if not exists rate2
as
select * from rate
;
- 创建索引:
create index index_rate2
on table rate2(uid)
as 'compact' -- 索引文件的存储格式
with deferred rebuild -- 索引能够重建
;
- 修改索引(重建索引):目的产生索引文件
alter index index_rate2
on rate2 rebuild;
- 查看索引
show index on rate2;
5)验证性能
select count(*) from rate1;
select count(*) from rate2;
select * from rate1 where uid=6040;
select * from rate2 where uid=6040;
- 创建联合索引
create index index_rate2_uid_movie
on table rate2(uid,movie)
as 'bitmap'
with deferred rebuild
;
alter index index_rate2_uid_movie on rate2 rebuild;
select * from rate1 where uid=6040 and movie = 2020;
select * from rate2 where uid=6040 and movie = 2020;
- 删除索引
drop index index_rate2 on rate2;
12.2 hive的视图
12.2.1 简介
- hive的视图简单理解为逻辑上的表
- hive只支持逻辑视图,不支持物化视图
- 视图存在的意义
1. 对数据进行局部暴露(涉及隐私的数据不暴露)
2. 简化复杂查询
12.2.2 创建视图:
create view if not exists v_1 as select uid,movie from rate2 where uid <3 ;
12.2.3 查看视图
show tables;
show create table v_1;
desc v_1;
对视图进行查询时:只能使用视图中的字段。不可以使用视图中没有的字段。
12.2.4 视图是否可以克隆
- 没有必要对视图进行克隆,因为视图没有数据存储
- 修改视图:直接修改元数据(修改元数据中查询语句)
- 先删除再创建就可以
12.2.5 删除视图
drop view if exists v_1;
注意:
1. 切忌先删除视图所依赖的表再去查询视图
2. 视图不能用insert into 或者load 加载数据
3. 视图是只读的不能修改其结构、相关属性
第十三章 Hive的压缩
HQL语句最终会被编译成Hadoop的Mapreduce job,因此hive的压缩设置,实际上就是对底层MR在处理数据时的压缩设置。
13.1 hive在map阶段的压缩
map阶段的设置, 就是在MapReduce的shuffle阶段对mapper产生的中间结果数据压缩 。 在这个阶段,优先选择一个低CPU开销的算法。
<!-- 指定要不要开启中间压缩 -->
<property>
<name>hive.exec.compress.intermediate</name>
<value>false</value>
</property>
<!-- 指定中间压缩想要使用的压缩编码器(类文件) -->
<property>
<name>hive.intermediate.compression.codec</name>
<value/>
</property>
<!-- 指定压缩编码器中的那种压缩类型 -->
<property>
<name>hive.intermediate.compression.type</name>
<value/>
</property>
13.2 hive在reduce阶段的压缩
即对reduce阶段的输出数据进行压缩设置。
<!-- 指定要不要开启最终压缩。 -->
<property>
<name>hive.exec.compress.output</name>
<value>false</value>
</property>
注意:如果开启,默认使用中间压缩配置的压缩编码器和压缩类型。
13.3 常用压缩格式
| 压缩格式 | 压缩比 | 压缩速度 | 需要安装 | 支持切分 |
|---|---|---|---|---|
| bzip2 | 最高 | 慢 | 否 | 是 |
| gzip | 很高 | 比较快 | 否 | 否 |
| snappy | 比较高 | 很快 | 是 | 否 |
| lzo | 比较高 | 很快 | 是 | 是(需要建立索引) |
13.4 压缩编码器:
| 压缩格式 | 压缩编码器 |
|---|---|
| deflate | org.apache.hadoop.io.compress.DefaultCodec |
| gzip | org.apache.hadoop.io.compress.GzipCodec |
| bzip2 | org.apache.hadoop.io.compress.BZip2Codec |
| lzo | com.hadoop.compression.lzo.LzopCodec(中间输出使用) |
| snappy | org.apache.hadoop.io.compress.SnappyCodec(中间输出使用) |
案例测试:
-- 开启中间压缩机制
hive (mydb)> set hive.exec.compress.intermediate=true;
-- 设置中间压缩编码器
hive (mydb)> set hive.intermediate.compression.codec=org.apache.hadoop.io.compress.DefaultCodec;
-- 设置压缩类型
hive (mydb)> set hive.intermediate.compression.type=RECORD;
-- 开启reduce端的压缩机制
hive (mydb)> set hive.exec.compress.output=true;
create external table if not exists stocks_seq_2 (
exchange1 string,
symbol string,
ymd string,
price_open float,
price_high float,
price_low float,
price_close float,
volume int,
price_adj_close float
)
row format delimited
fields terminated by ','
stored as sequencefile;
--动态加载数据:
insert into stocks_seq_2 select * from stocks_1;
验证数据是否变小了..........
13.5 知识扩展:
什么是可分割
在考虑如何压缩那些将由MapReduce处理的数据时,考虑压缩格式是否支持分割是很重要的。考虑存储在HDFS中的未压缩的文件,其大小为1GB,HDFS的块大小为128MB,所以该文件将被存储为8块,将此文件用作输入的MapReduce作业会创建1个输人分片(split,也称为“分块”。对于block,我们统一称为“块”。)每个分片都被作为一个独立map任务的输入单独进行处理。
现在假设,该文件是一个gzip格式的压缩文件,压缩后的大小为1GB。和前面一样,HDFS将此文件存储为8块。然而,针对每一块创建一个分块是没有用的,因为不可能从gzip数据流中的任意点开始读取,map任务也不可能独立于其他分块只读取一个分块中的数据。gzip格式使用DEFLATE来存储压缩过的数据,DEFLATE将数据作为一系列压缩过的块进行存储。问题是,每块的开始没有指定用户在数据流中任意点定位到下一个块的起始位置,而是其自身与数据流同步。因此,gzip不支持分割(块)机制。
在这种情况下,MapReduce不分割gzip格式的文件,因为它知道输入是gzip压缩格式的(通过文件扩展名得知),而gzip压缩机制不支持分割机制。因此一个map任务将处理16个HDFS块,且大都不是map的本地数据。与此同时,因为map任务少,所以作业分割的粒度不够细,从而导致运行时间变长。
第十四章 Hive企业级调优
14.1 环境方面
可以修改相关服务器的配置、容器的配置、环境搭建
14.2 具体软件配置参数
14.3 代码级别的优化
15.3.1 explain 和 explain extended
explain select * from text1;
explain extended select * from text1;
explain extended
select
d.deptno as deptno,
d.dname as dname
from dept d
union all
select
d.dname as dname,
d.deptno as deptno
from dept d
;
explain : 只有对hql语句的解释。
explain extended:对hql语句的解释,以及抽象表达式树的生成。
stage 相当于一个job,一个stage可以是limit、也可以是一个子查询、也可以是group by等。
hive默认一次只执行一个stage,但是如果stage之间没有相互依赖,将可以并行执行。
任务越复杂,hql代码越复杂,stage越多,运行的时间一般越长。
15.3.2 join
hive的查询永远是小表(结果集)驱动大表(结果集)
hive中的on的条件只能是等值连接
注意hive是否配置普通join转换成map端join、以及mapjoin小表文件大小的阀值
15.3.3 limit的优化:
hive.limit.row.max.size=100000
hive.limit.optimize.limit.file=10
hive.limit.optimize.enable=false (如果limit较多时建议开启) hive.limit.optimize.fetch.max=50000
15.3.4 本地模式:
hive.exec.mode.local.auto=false (建议打开)
hive.exec.mode.local.auto.inputbytes.max=134217728
hive.exec.mode.local.auto.input.files.max=4
15.3.5 并行执行:
hive.exec.parallel=false (建议开启)
hive.exec.parallel.thread.number=8
15.3.6 严格模式:
hive.mapred.mode=nonstrict
Cartesian Product.
No partition being picked up for a query.
Orderby without limit.
Comparing bigints and strings.
Comparing bigints and doubles.
15.3.7 mapper和reducer的个数:
不是mapper和redcuer个数越多越好,也不是越少越好。
将小文件合并处理(将输入类设置为:CombineTextInputFormat) 通过配置将小文件合并:
mapred.max.split.size=256000000
mapred.min.split.size.per.node=1
mapred.min.split.size.per.rack=1
hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat
set mapreduce.job.reduces=10
hive.exec.reducers.max=1009
15.3.8 配置jvm重用:
set mapreduce.job.jvm.numtasks=1
set mapred.job.reuse.jvm.num.tasks=1
15.3.9数据倾斜:
数据倾斜:由于key分布不均匀造成的数据向一个方向偏离的现象。
本身数据就倾斜
join语句容易造成
count(distinct col) 很容易造成倾斜
group by 也可能会造成
找到造成数据倾斜的key,然后再通过hql语句避免。
hive.map.aggr=true
hive.groupby.skewindata=false (建议开启)
hive.optimize.skewjoin=false
Whether to enable skew join optimization.
The algorithm is as follows: At runtime, detect the keys with a large skew. Instead of
processing those keys, store them temporarily in an HDFS directory. In a follow-up map-reduce
job, process those skewed keys. The same key need not be skewed for all the tables, and so,
the follow-up map-reduce job (for the skewed keys) would be much faster, since it would be a
map-join.
15.3.10 索引是一种hive的优化:
想要索引在查询时生效,还得设置使用索引:默认是不使用的。
SET hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
SET hive.optimize.index.filter=true;
SET hive.optimize.index.filter.compact.minsize=0;
15.3.11 分区本身就是hive的一种优化
15.3.12 job的数量:
一般是一个查询产生一个job,然后通常情况一个job、可以是一个子查询、一个join、一个group by 、一个limit等一些操作。