一致性哈希
一、简介
这个算法是一种特殊的哈希算法,目的是解决分布式缓存的问题。
普通哈希算法在分布式存储具有较大的局限性,简单的讲就是难以扩展。
一致性哈希相对而言具有较好的容错性和可扩展性,更加适合现在的分布式存储。
二、经典哈希版本
众所周知,哈希表是通过计算哈希值,并将其取模的方式来对数据进行定位,最后通过拉链法来进行数据存储。
经典哈希在分布式上的应用也是一样的。
- 比如说,你现在有3台服务器,分别命名为0,1,2;
那么你放一串数据进来后
先算哈希值;
再用哈希值模3,得到该存在哪台服务器上;
之后就传数据存储。
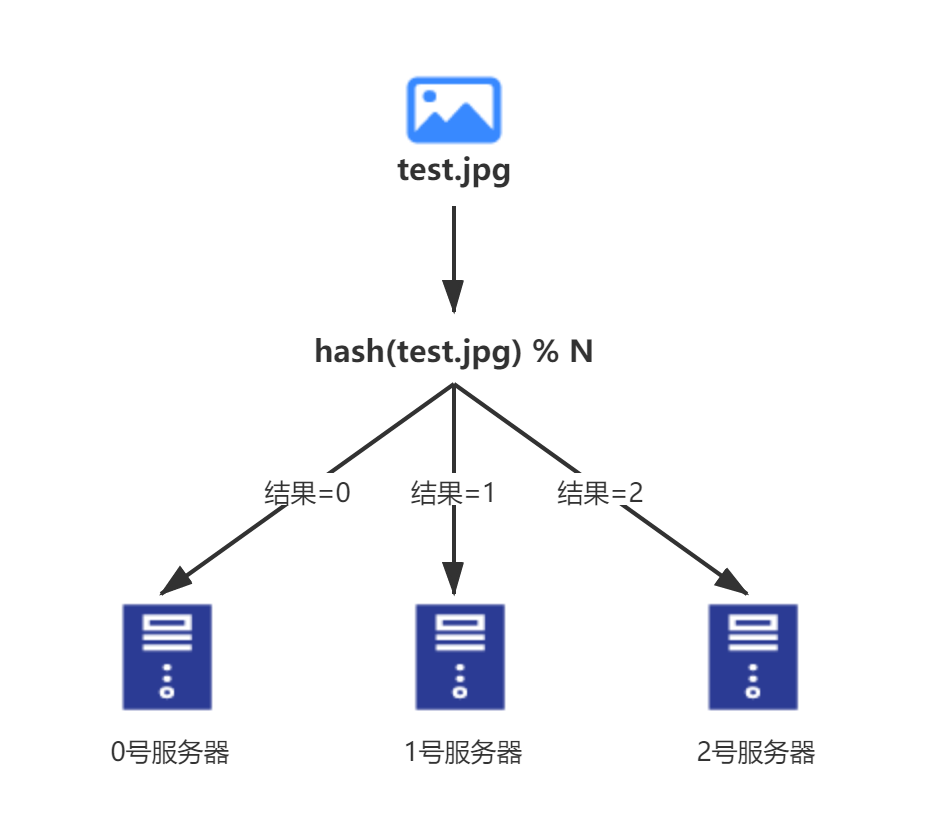
这样是行得通的,但是同时这种模式有非常严重隐患,每当服务器数量发生改变,数据的迁移量都是海量的,例如:
- 当你一台服务器出问题,需要紧急下线,那么3台服务器中的所有内容都需要根据哈希值重新分配服务器
- 当数据量增长到服务器的存储阈值,需要新增服务器时,同样所有已存在的数据都需要重新进行分配
三、一致性哈希
为了解决经典哈希的短板,一致性哈希大大缩小了数据的迁移成本,怎么做到的呢?
1、哈希环
- 将哈希值想象成一个周长2**64的圆
- 将每一个服务器用一个哈希值表示,并且假设这个哈希值均分哈希环
于是:
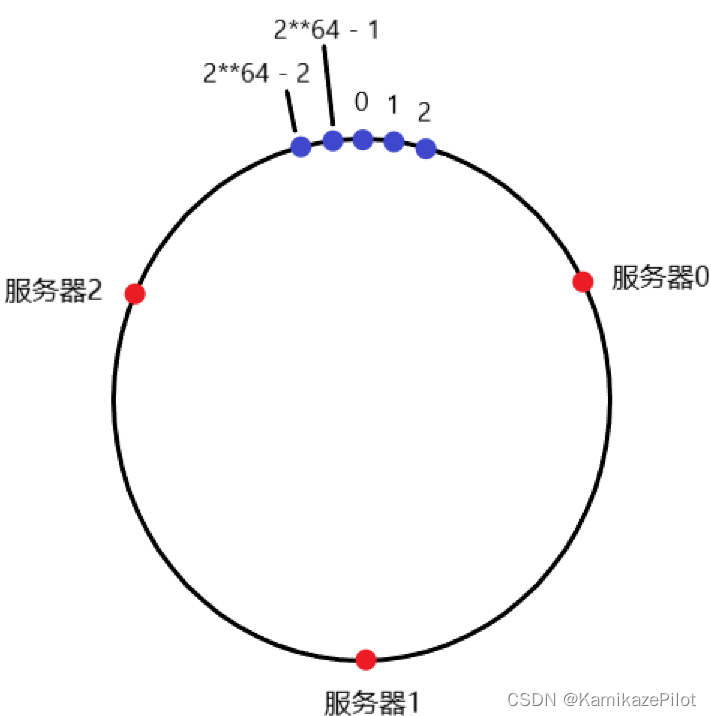
那么怎么判断数据该存进哪个服务器呢? - 每一个服务器都只存储该哈希值在服务器到顺时针下一个服务器节点区间的所有值
比如0位置,这里的数据将会被存储在服务器2上
实际上所有哈希值在服务器2到服务器0位置上的,都会被存储在服务器2上。
2、这种情况下数据迁移
现在新添加一台服务器在环上,不考虑均匀分布的问题,如何做数据迁移?
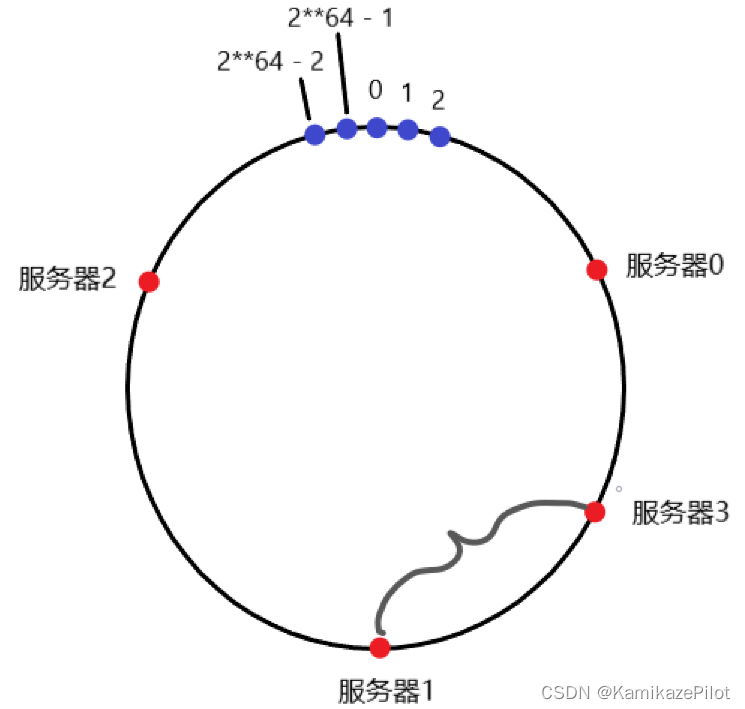
如上图所示,添加一台服务器3进去,那么我们只需要迁移所有哈希值在服务器3 到 服务器1 上的数据,这种方式下,数据迁移的代价无疑是大大降低的。
3、虚拟节点
刚才上面提到了一个问题,服务器的均匀分布
当服务器在环上的分布不均匀时,有可能出现极端情况,比如一台服务器负载过大,一台负载较小。这种情况也被称为哈希环的倾斜,容易造成服务器的奔溃
为了解决这个问题,就有了虚拟节点这个东西。
- 首先忘记服务器节点刚才的定义,将服务器节点分为两部分
- 一个部分为物理节点,就是实际上的服务器;
- 一个部分为虚拟节点,专门用来在哈希环上占位置;
- 其中一个物理节点下对应多个虚拟节点,即一台服务器存储 所有对应的虚拟节点 管理范围内的数据。
1>例:
设:
- 有3个物理节点
- 每个物理节点上存储了500个虚拟节点
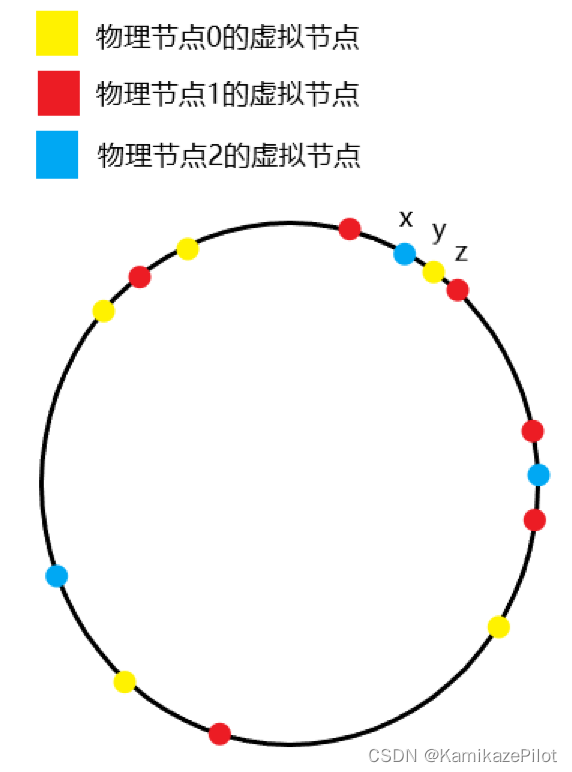
则以下图中的x,y,z为例
- 首先x,y,z之间不存在其他虚拟节点
- 哈希值在x到y之间的会被存储在物理节点2上
- 哈希值在y到z之间的会被存储在物理节点0上
- 之后加入新的物理节点数据迁移的话,也同样遵循之前的逻辑,同样因为时随机分布,数据量较大时它绝对可以实现数据的均匀分布;
- 另外还可以通过设置虚拟节点的数量,来实现不同负载服务器的充分利用,比如一台性能比较强的,可以给2000个虚拟节点,性能弱一点给700个。
这个技术很厉害,这种思想也很值得学习。
参考文献:
https://blog.csdn.net/a745233700/article/details/120814088