Python使用pandas导入csv文件内容
使用pandas导入csv文件内容
- 使用pandas导入csv文件内容
- 1. 默认导入
- 2. 指定分隔符
- 3. 指定读取行数
- 4. 指定编码格式
- 5. 列标题与数据对齐
使用pandas导入csv文件内容
1. 默认导入
在Python中导入.csv文件用的方法是read_csv()。
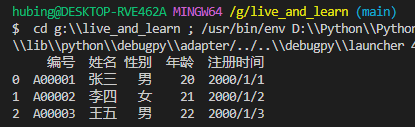
使用read_csv()进行导入时,指定文件名即可
import pandas as pd
df = pd.read_csv(r'G:\test.csv')
print(df)
2. 指定分隔符
read_csv()默认文件中的数据都是以逗号分开的,但是有的文件不是用逗号分开的,这个时候就需要人为指定分隔符号,否则就会报错。
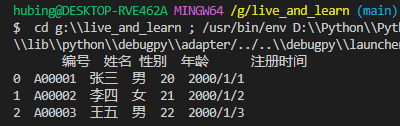
分隔符通过sep参数指定。常见的分隔符除了逗号,还有空格以及制表符(\t)等
import pandas as pd
df = pd.read_csv(r'G:\test.csv', sep=',')
print(df)
3. 指定读取行数
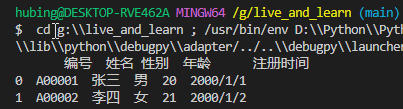
假设现在有一个几百兆的文件,你想了解一下这个文件里有哪些数据,那么这个时候你就没必要把全部数据都导入,你只要看到前面几行即可,因此只要设置 nrows参数即可。
import pandas as pd
df = pd.read_csv(r'G:\test.csv', sep=',', nrows=2)
print(df)
4. 指定编码格式
每个文件都是有编码格式的,常用的编码格式有utf-8和gbk等。有的时候两个文件看起来一样,它们的文件名一样,格式也一样,但如果它们的编码格式不一样,也是不一样的文件,比如当你把一个Excel文件另存为保存时会出现两个选项,虽然都是.csv文件,但是这两种格式代表两种不同的文件

Python用得比较多的两种编码格式是UTF-8和gbk,默认编码格式是UTF-8。我们要根据导入文件本身的编码格式进行设置,通过设置参数encoding来设置导入的编码格式。
如果我们不指定encoding参数, 默认是使用utf-8编码格式。
import pandas as pd
df = pd.read_csv(r'G:\test.csv', sep=',', nrows=3, encoding='utf-8')
print(df)
如果是CSV(逗号分隔) (*.csv)格式的文件,那么在导入的时候就需要把编码格式更改为gbk,如果使用UTF-8就会报错。
5. 列标题与数据对齐
因为我们的表格中有中文,中文占用的字符和英文、数字占用的字符不一样,因此需要调用pd.set_option()使表格对齐显示。如果你是使用 Jupyter 来运行代码的,Jupyter 会自动渲染出一个表格,则无需这个设置。
import pandas as pd
#处理数据的列标题与数据无法对齐的情况
pd.set_option('display.unicode.ambiguous_as_wide', True)
#无法对齐主要是因为列标题是中文
pd.set_option('display.unicode.east_asian_width', True)
df = pd.read_csv(r'G:\test.csv', sep=',', nrows=3, encoding='utf-8')
print(df)
对齐后的效果: