解决原 Unique Key 模型存在的问题
为了解决原 Unique Key 模型存在的问题,以更好的满足业务场景的需求,我们决定对 Unique Key 模型进行优化,针对读写效率问题的优化方案展开了详细的调研。
关于以上问题的解决方案,业内已经有了较多的探索。代表性的有三类:
-
Delete + Insert。即在数据写入时通过一个主键索引查找到被覆盖的 key,将其标记为删除。比较有代表性的系统是微软的 SQL Server。
-
Delta Store。将数据分为 base data 和 delta data,base data 中的每一个主键都保证唯一,所有更新都记录在 Delta Store 中,查询时将 base data 和 delta data 进行 merge 同,时有后台的 merge 线程定期将 delta data 和 base data 进行合并。比较有代表性的系统是 Apache Kudu。
-
Copy-on-Write。在更新数据时直接将原来的数据整行拷贝、更新后写入新文件。数据湖采用这类方式的比较多,比较有代表性的系统是 Apache Hudi 与 Delta Lake。
具体三类方案的实现机制及对比如下:
Delete + Insert (即 Merge-on-Write)
比较有代表性的是 SQL Server 在 2015 年 VLDB 上发表的论文《Real-Time Analytical Processing with SQL Server》中提出的方案。简单来说,这篇论文提出了数据写入时将旧的数据标记删除(使用一个 Delete Bitmap 的数据结构),并将新数据记录在 Delta Store 中,查询时将 Base 数据、Delete Bitmap、Delta Store 中的数据 Merge 起来以得到最新的数据。整体方案如下图所示,由于篇幅限制就不展开进行介绍了。
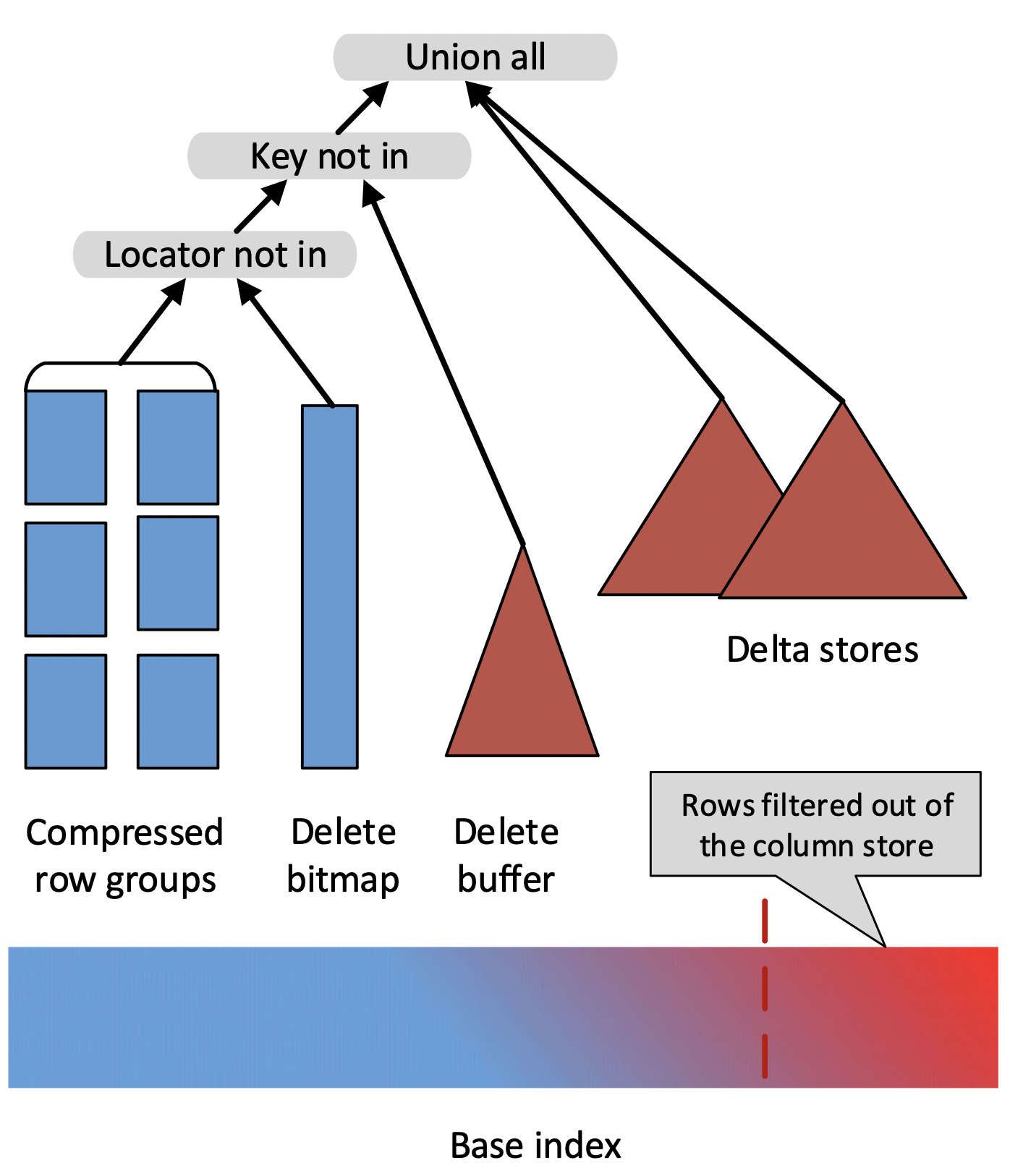
这个方案的优势在于,任何一个有效的主键只存在于一个地方(要么在 Base Data 中,要么在 Delta Store 中),这样就避免了查询过程中的大量归并排序的消耗,同时 Base 数据中的各种丰富的列存索引也仍然有效。
Delta Store
Delta Store 的方式比较有代表性的系统就是 Apache Kudu。在 Kudu 中,数据分为 Base Data 和 Delta Data,Base Data 中的主键都是唯一的,任何对于 Base 数据的修改会先写入 Delta Store 中(通过行号标记与 Base Data 中的对应关系,这样可以避免 Merge 时的排序)。与前面 SQL Server 的 Base + Delta 不同的是,Kudu 没有标记删除,所以同一个主键的数据会存在于两个地方,所以查询时必须将 Base 和 Delta 的数据合并才能得到最新的结果。Kudu 的方案如下图所示:
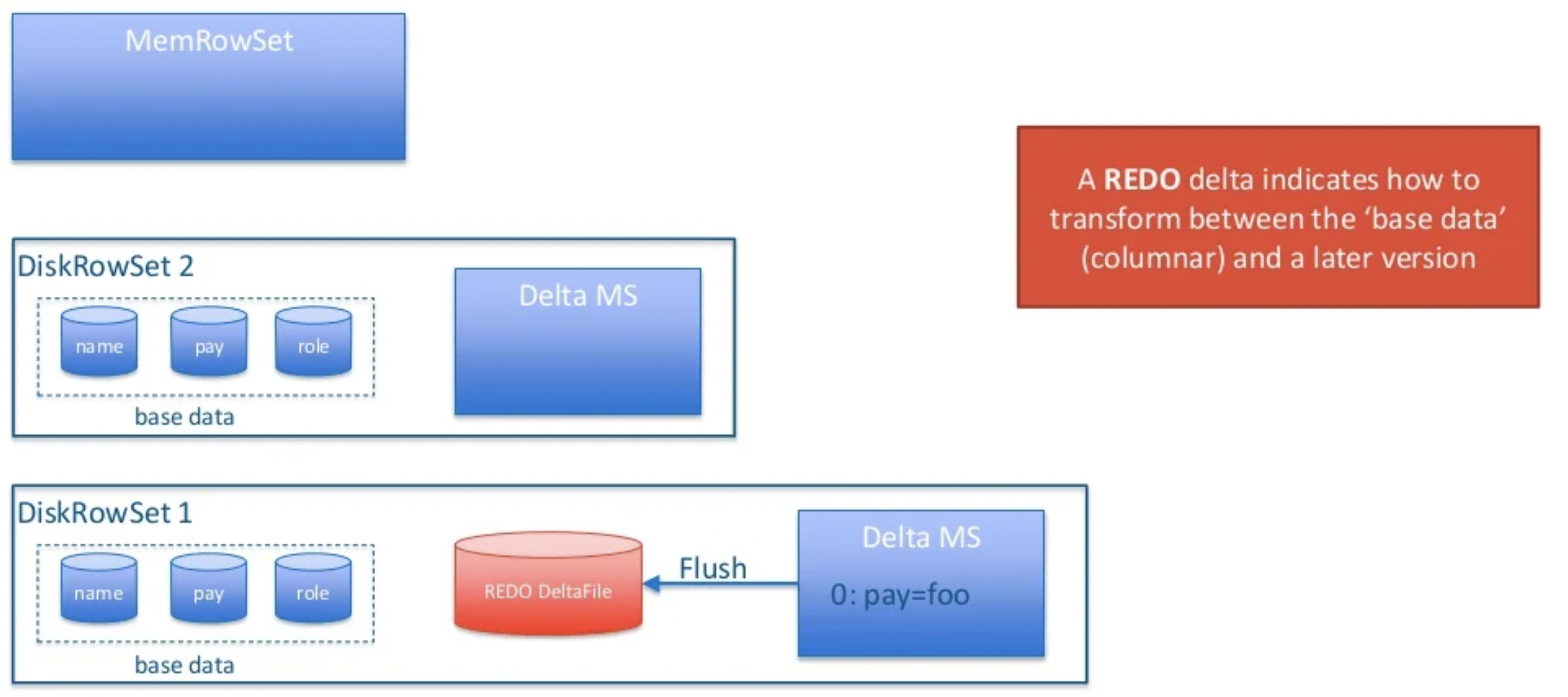
https://www.slideshare.net/cloudera/apache-kudu-technical-deep-dive
Kudu 这套方案也能避免读取数据时的归并排序所带来的高昂代价,但是由于一个主键的数据会存在于多个地方,它就难以保证索引的准确性,也无法做一些高效的谓词下推。而索引和谓词下推都是分析型数据库进行性能优化的一个重要手段,这个缺点对于性能影响还是挺大的。
Copy-On-Write
由于 Apace Doris 定位是一个实时分析型数据库,Copy On Write 方案对于实时更新来说成本太高,并不适合 Doris。