P5 PyTorch 合并与分割
前言:
目录
- cat
- stack
- split
- chunk
一 cat(合并)
df = torch.cat([df1,df2,df3],dim=0)
要合并的维度可以不相等,其它维度大小必须一样
应用场景:
比如有两个统计数据[class,students,scores]
A = [4,32,8], 4个班级,每班32人,每个人8个科目的考试成绩
B= [5,32,8] 5个班级,每班32人,每个人8个科目的考试成绩
现在合并成一个张量
C= [9,32,8] 9个班级,每班32人,每个人8个科目的考试成绩

1.2 例2
【students,score】
df1 = [4,4]: 4个学生,4科成绩
df2 = [4,4] 4个学生,4科成绩
df3 = [4,4] 4个学生,4科成绩
通过cat([df1,df2,df3], dim=0)后得到
df =[12,4] 12个学生,4科成绩


1.3 例3
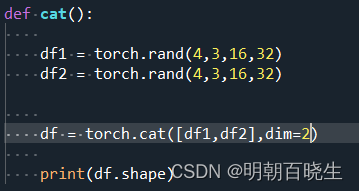
torch.Size([4, 3, 32, 32])
二 stack(合并)
原理:
在指定的维度前面创建一个新的维度,需要stack的张量必须shape一样
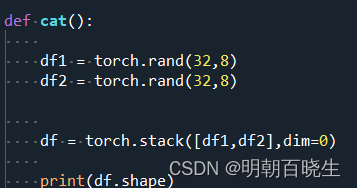
如上两个班级
df1=[32,8] 32个人,8科成绩
df2=[32,8] 32个人,8 科成绩
最后df的shape 如下:
torch.Size([2, 32, 8])
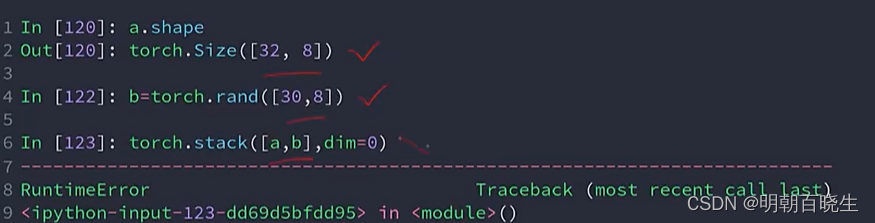
大小不一样出错例子
三 split (拆分)
按指定的长度,在指定的维度上面进行拆分。
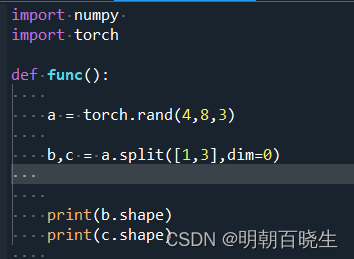
比如 4个班,每班8人,3科成绩
torch.Size([1, 8, 3]) 1个重点班
torch.Size([3, 8, 3]) 3个普通班
四 chunk 拆分
按指定的数量,在指定的维度上面拆分
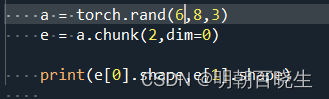
6个班,每班8个学生,3科成绩.
拆分成两组,每组3个班,
输出:
torch.Size([3, 8, 3]) torch.Size([3, 8, 3])