数据库面试题
数据库基础知识
什么是MySQL?
-
MySQL是一个数据库管理系统。
数据库是数据的结构化集合。
-
MySQL数据库是关系型的。
关系数据库将数据存储在单独的表中,而不是将所有数据放在一个大仓库中。数据库结构被组织成针对速度进行了优化的物理文件。具有对象(例如数据库,表,视图,行和列)的逻辑模型提供了灵活的编程环境。您设置规则来管理不同数据字段之间的关系,例如一对一,一对多,唯一,必需或可选,以及 不同表之间的“指针”。数据库执行这些规则,因此,使用设计良好的数据库,您的应用程序将永远不会看到不一致,重复,孤立,孤立,过时或丢失的数据。
**“ MySQL ” 的SQL部分代表 “结构化查询语言”。SQL是用于访问数据库的最常见的标准化语言。**根据您的编程环境,您可以直接输入SQL(例如,生成报告),将SQL语句嵌入用另一种语言编写的代码中,或使用隐藏SQL语法的特定于语言的API。
SQL由ANSI / ISO SQL标准定义。自1986年以来,SQL标准一直在发展,并且存在多个版本。在本手册中,“ SQL-92 ”是指1992年发布的标准,“ SQL:1999 ”是指1999年发布的标准,“ SQL:2003 ”是指标准的当前版本。我们随时使用 “ SQL标准”一词来表示SQL标准的当前版本。
-
MySQL软件是开源的。
开源意味着任何人都可以使用和修改该软件。任何人都可以从互联网上下载MySQL软件并使用它而无需支付任何费用。如果愿意,您可以学习源代码并进行更改以适合您的需求。
-
MySQL数据库服务器非常快速,可靠,可扩展且易于使用。
-
MySQL Server在客户端/服务器或嵌入式系统中运行。
MySQL数据库软件是一个客户端/服务器系统,由支持不同后端的多线程SQL Server,几个不同的客户端程序和库,管理工具以及各种应用程序编程接口(API)组成。
-
可以使用大量的MySQL软件。
MySQL的主要功能
内部和便携性
- 使用具有独立模块的多层服务器设计。
- 设计为使用内核线程完全多线程,以轻松使用多个CPU(如果有)。
- 提供事务性和非事务性存储引擎。
- 使用
MyISAM索引压缩非常快速的B树磁盘表()。 - 旨在使其相对容易地添加其他存储引擎。如果要为内部数据库提供SQL接口,这将很有用。
- 使用非常快速的基于线程的内存分配系统。
- 使用优化的嵌套循环联接执行非常快速的联接。
- 实现内存中的哈希表,用作临时表。
- 使用高度优化的类库来实现SQL函数,该类库应尽可能快。通常,查询初始化后根本没有内存分配。
- 提供服务器作为在客户端/服务器网络环境中使用的单独程序,以及作为可嵌入(链接)到独立应用程序中的库。此类应用程序可以隔离使用,也可以在没有网络可用的环境中使用。
资料类型
- 许多数据类型:有符号/无符号整数1,2,3,4,和8个字节长,
FLOAT,DOUBLE,CHAR,VARCHAR,BINARY,VARBINARY,TEXT,BLOB,DATE,TIME,DATETIME,TIMESTAMP,YEAR,SET,ENUM,和开放GIS空间类型。 - 固定长度和可变长度的字符串类型。
陈述和功能
-
查询
SELECT列表和WHERE子句中的 完全运算符和函数支持 。例如:mysql> SELECT CONCAT(first_name, ' ', last_name) -> FROM citizen -> WHERE income/dependents > 10000 AND age > 30; -
完全支持SQL
GROUP BY和ORDER BY子句。支持基函数(COUNT(),AVG(),STD(),SUM(),MAX(),MIN(),和GROUP_CONCAT())。 -
支持标准SQL和ODBC语法,
LEFT OUTER JOIN并RIGHT OUTER JOIN同时支持它们。 -
支持标准SQL要求的表和列别名。
-
支持
DELETE,INSERT,REPLACE,和UPDATE以返回更改(受影响)的行数,或返回通过连接到服务器时设置标志,而不是匹配的行的数量。 -
支持特定于MySQL的
SHOW语句,该语句检索有关数据库,存储引擎,表和索引的信息。支持INFORMATION_SCHEMA数据库,根据标准SQL实现。 -
一条
EXPLAIN语句,显示优化器如何解析查询。 -
函数名称与表或列名称的独立性。例如,
ABS是一个有效的列名。唯一的限制是对于函数调用,函数名称和其后的“(”之间不允许有空格 。请参见 第9.3节“关键字和保留字”。 -
您可以在同一条语句中引用来自不同数据库的表。
安全
- 特权和密码系统,非常灵活和安全,并且可以进行基于主机的验证。
- 连接服务器时,通过对所有密码通信进行加密来实现密码安全。
可扩展性和限制
- 支持大型数据库。我们将MySQL Server与包含5000万条记录的数据库一起使用。我们也知道使用MySQL Server的用户有200,000个表和大约5,000,000,000行。
- 每个表最多支持64个索引。每个索引可以包含1到16列或部分列。
InnoDB表的最大索引宽度为767字节或3072字节。
连接性
本土化
客户和工具
MySQL 8.0的新增功能
https://dev.mysql.com/doc/refman/8.0/en/mysql-nutshell.html
- 数据字典。 MySQL现在合并了一个事务性数据字典,用于存储有关数据库对象的信息
- 原子数据定义语句(Atomic DDL)。 原子DDL语句将数据字典更新,存储引擎操作以及与DDL操作关联的二进制日志写入操作组合到单个原子事务中。
- 升级程序。 以前,在安装新版本的MySQL之后,MySQL服务器会在下次启动时自动升级数据字典表,从MySQL 8.0.16开始,服务器执行以前由mysql_upgrade处理的任务。
- 安全性和帐户管理。 添加了这些增强功能,以提高安全性并在帐户管理中实现更大的DBA灵活性:
mysql现在 ,系统数据库中的授权表是InnoDB(事务性)表。以前,这些是MyISAM(非事务性)表。- 以前,帐户管理对帐单(例如
CREATE USER或DROP USER),命名多个用户可以对某些用户成功,而对其他用户则失败。现在,每个语句都是事务性的,并且对于所有命名的用户都成功,或者回滚,并且在发生任何错误时都不起作用。如果成功,则将语句写入二进制日志;如果失败,则不写入语句。在这种情况下,将发生回滚并且不进行任何更改。 - 一个新的
caching_sha2_password身份验证插件可用。caching_sha2_password实现SHA-256密码哈希,但是使用缓存来解决连接时的延迟问题。 - MySQL现在支持角色,这些角色被称为特权集合。
- MySQL现在合并了用户帐户类别的概念
- 资源管理。 MySQL现在支持创建和管理资源组,并允许将服务器中运行的线程分配给特定的组,以便线程根据该组可用的资源执行。
- 表加密管理。 现在可以通过定义和强制执行加密默认值来全局管理表加密。
- InnoDB增强功能。
- 每次值更改时,当前最大自动增量计数器值都会写入重做日志,并保存到每个检查点的引擎专用系统表中。这些更改使当前的最大自动增量计数器值在服务器重新启动期间保持不变。
- 在
ROLLBACK操作之后立即重新启动服务器 不再导致重用分配给回滚事务的自动增量值。 - 遇到索引树损坏时,
InnoDB将损坏标志写入重做日志,这会使损坏标志崩溃。InnoDB还将内存损坏标志数据写入每个检查点上的引擎专用系统表。在恢复期间,InnoDB在将内存表和索引对象标记为已损坏之前,从两个位置读取损坏标志并合并结果。 InnoDBmemcached的插件支持多个get操作(读取在一个单一的多键-值对分布式缓存 查询)和范围查询。
ENUM类型
https://dev.mysql.com/doc/refman/8.0/en/enum.html
该ENUM类型具有以下优点:
- 在列的一组可能值有限的情况下,压缩数据存储。您指定为输入值的字符串会自动编码为数字。见 第11.7节,“列类型存储需求”为存储需求
ENUM类型。 - 可读的查询和输出。这些数字将转换回查询结果中的相应字符串。
枚举文字的索引值
每个枚举值都有一个索引:
-
列规范中列出的元素分配有索引号,从1开始。
-
空字符串错误值的索引值为0。这意味着您可以使用以下
SELECT语句查找ENUM分配了无效值的行:mysql> SELECT * FROM tbl_name WHERE enum_col=0; -
NULL值 的索引是NULL。 -
术语“索引”在这里是指枚举值列表中的位置。它与表索引无关。
为什么要使用数据库
数据保存在内存
优点: 存取速度快
缺点: 数据不能永久保存
数据保存在文件
优点: 数据永久保存
缺点:1)速度比内存操作慢,频繁的IO操作。2)查询数据不方便
数据保存在数据库
1)数据永久保存
2)使用SQL语句,查询方便效率高。
3)管理数据方便
什么是SQL?
结构化查询语言(Structured Query Language)简称SQL,是一种数据库查询语言。
作用:用于存取数据、查询、更新和管理关系数据库系统。
什么是MySQL?
MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,属于 Oracle 旗下产品。MySQL 是最流行的关系型数据库管理系统之一,在 WEB 应用方面,MySQL是最好的 RDBMS (Relational Database Management System,关系数据库管理系统) 应用软件之一。在Java企业级开发中非常常用,因为 MySQL 是开源免费的,并且方便扩展。
数据库三大范式是什么
https://developer.aliyun.com/article/248114
第一范式:每个列都不可以再拆分。
第二范式:在第一范式的基础上,非主键列完全依赖于主键,而不能是依赖于主键的一部分。
第三范式:在第二范式的基础上,非主键列只依赖于主键,不依赖于其他非主键。
在设计数据库结构的时候,要尽量遵守三范式,如果不遵守,必须有足够的理由。比如性能。事实上我们经常会为了性能而妥协数据库的设计。
mysql有关权限的表都有哪几个
MySQL服务器通过权限表来控制用户对数据库的访问,权限表存放在mysql数据库里,由mysql_install_db脚本初始化。这些权限表分别user,db,table_priv,columns_priv和host。下面分别介绍一下这些表的结构和内容:
- user权限表:记录允许连接到服务器的用户帐号信息,里面的权限是全局级的。
- db权限表:记录各个帐号在各个数据库上的操作权限。
- table_priv权限表:记录数据表级的操作权限。
- columns_priv权限表:记录数据列级的操作权限。
- host权限表:配合db权限表对给定主机上数据库级操作权限作更细致的控制。这个权限表不受GRANT和REVOKE语句的影响。
MySQL的binlog有有几种录入格式?分别有什么区别?
有三种格式,statement,row和mixed。
- statement模式下,**每一条会修改数据的sql都会记录在binlog中。**不需要记录每一行的变化,减少了binlog日志量,**节约了IO,提高性能。**由于sql的执行是有上下文的,因此在保存的时候需要保存相关的信息,同时还有一些使用了函数之类的语句无法被记录复制。
- row级别下,不记录sql语句上下文相关信息,仅保存哪条记录被修改。记录单元为每一行的改动,基本是可以全部记下来但是由于很多操作,会导致大量行的改动(比如alter table),因此这种模式的文件保存的信息太多,日志量太大。
- mixed,一种折中的方案,普通操作使用statement记录,当无法使用statement的时候使用row。
此外,新版的MySQL中对row级别也做了一些优化,当表结构发生变化的时候,会记录语句而不是逐行记录。
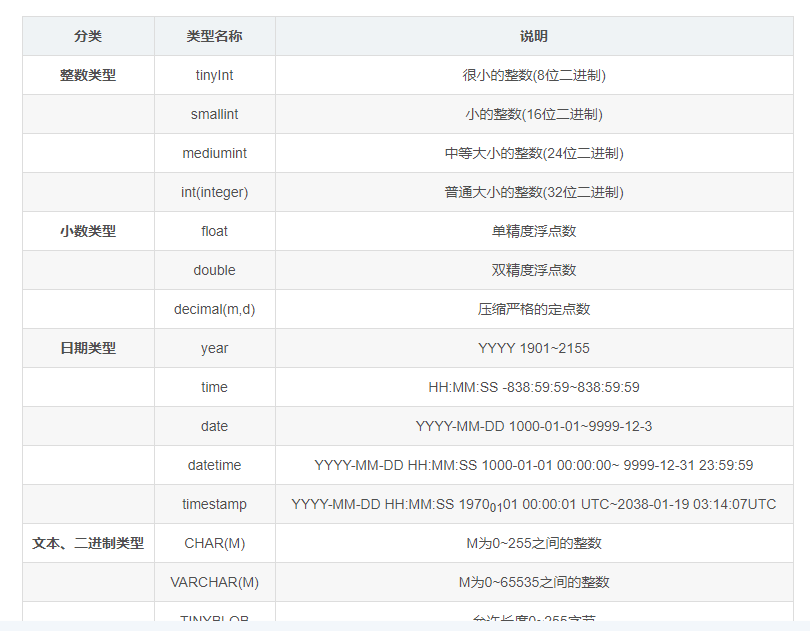
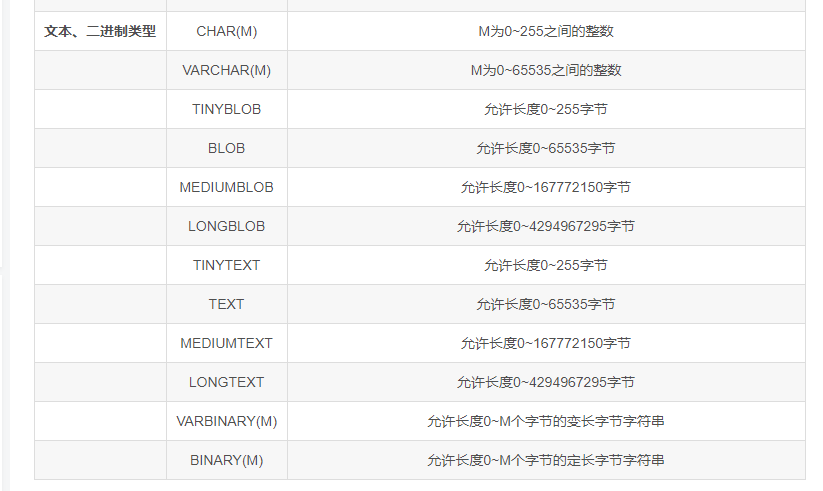
数据类型
mysql有哪些数据类型
-
1、整数类型,包括TINYINT、SMALLINT、MEDIUMINT、INT、BIGINT,分别表示1字节、2字节、3字节、4字节、8字节整数。任何整数类型都可以加上UNSIGNED属性,表示数据是无符号的,即非负整数。
长度:整数类型可以被指定长度,例如:INT(11)表示长度为11的INT类型。长度在大多数场景是没有意义的,它不会限制值的合法范围,只会影响显示字符的个数,而且需要和UNSIGNED ZEROFILL属性配合使用才有意义。
例子,假定类型设定为INT(5),属性为UNSIGNED ZEROFILL,如果用户插入的数据为12的话,那么数据库实际存储数据为00012。 -
2、实数类型,包括FLOAT、DOUBLE、DECIMAL。
DECIMAL可以用于存储比BIGINT还大的整型,能存储精确的小数。
而FLOAT和DOUBLE是有取值范围的,并支持使用标准的浮点进行近似计算。
计算时FLOAT和DOUBLE相比DECIMAL效率更高一些,DECIMAL你可以理解成是用字符串进行处理。 -
3、字符串类型,包括VARCHAR、CHAR、TEXT、BLOB
VARCHAR用于存储可变长字符串,它比定长类型更节省空间。
VARCHAR使用额外1或2个字节存储字符串长度。列长度小于255字节时,使用1字节表示,否则使用2字节表示。
VARCHAR存储的内容超出设置的长度时,内容会被截断。
CHAR是定长的,根据定义的字符串长度分配足够的空间。
CHAR会根据需要使用空格进行填充方便比较。
CHAR适合存储很短的字符串,或者所有值都接近同一个长度。
CHAR存储的内容超出设置的长度时,内容同样会被截断。使用策略:
对于经常变更的数据来说,CHAR比VARCHAR更好,因为CHAR不容易产生碎片。
对于非常短的列,CHAR比VARCHAR在存储空间上更有效率。
使用时要注意只分配需要的空间,更长的列排序时会消耗更多内存。
尽量避免使用TEXT/BLOB类型,查询时会使用临时表,导致严重的性能开销。 -
4、枚举类型(ENUM),把不重复的数据存储为一个预定义的集合。
有时可以使用ENUM代替常用的字符串类型。
ENUM存储非常紧凑,会把列表值压缩到一个或两个字节。
ENUM在内部存储时,其实存的是整数。
尽量避免使用数字作为ENUM枚举的常量,因为容易混乱。
排序是按照内部存储的整数 -
5、日期和时间类型,尽量使用timestamp,空间效率高于datetime,
用整数保存时间戳通常不方便处理。
如果需要存储微妙,可以使用bigint存储。
看到这里,这道真题是不是就比较容易回答了。
引擎
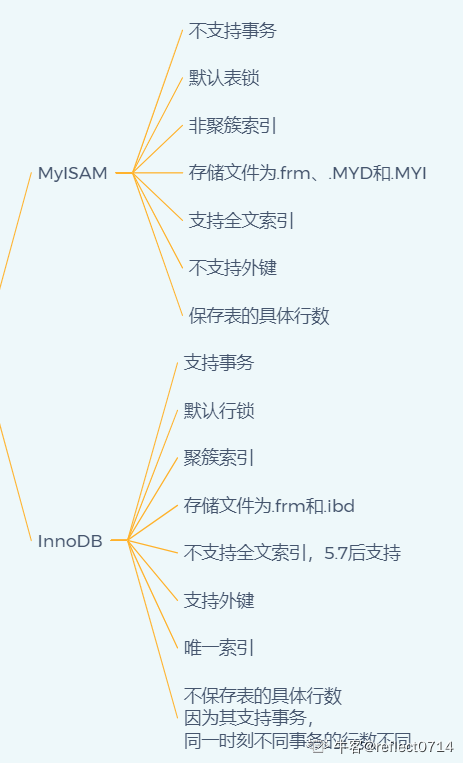
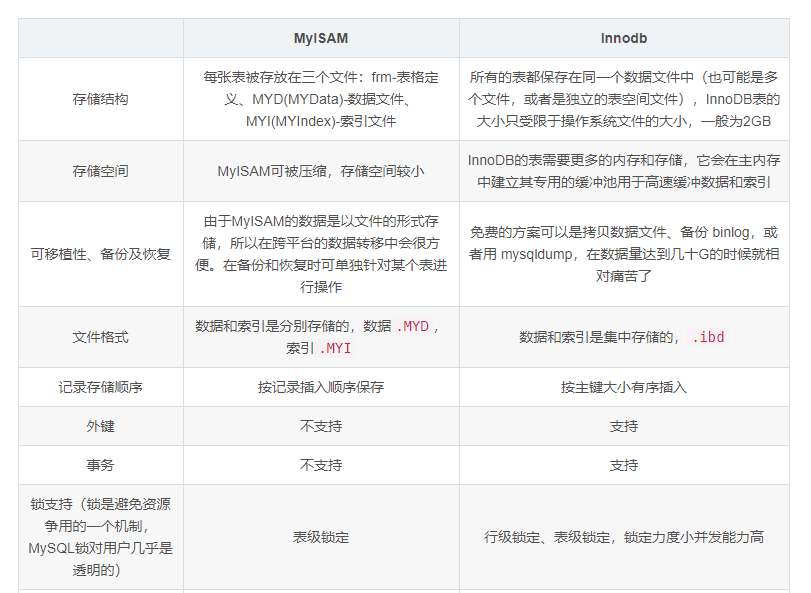
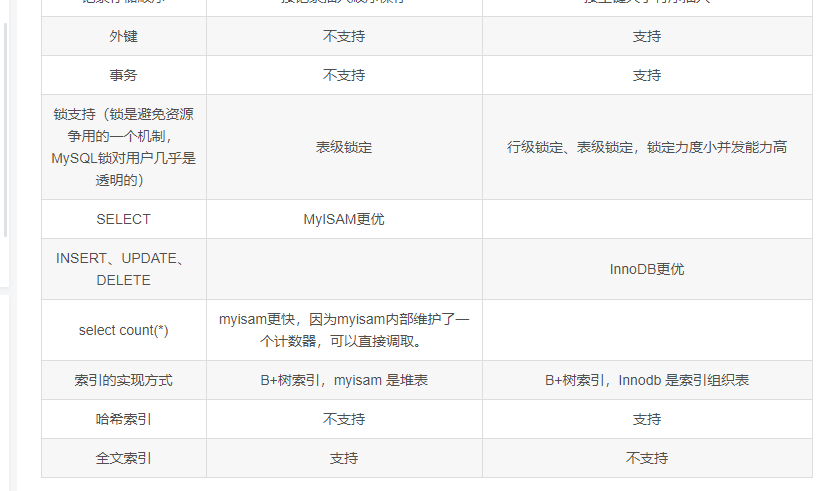
MySQL存储引擎MyISAM与InnoDB区别
存储引擎Storage engine:MySQL中的数据、索引以及其他对象是如何存储的,是一套文件系统的实现。
常用的存储引擎有以下:
- Innodb引擎:Innodb引擎提供了对数据库ACID事务的支持。并且还提供了行级锁和外键的约束。它的设计的目标就是处理大数据容量的数据库系统。
- MyIASM引擎(原本Mysql的默认引擎):不提供事务的支持,也不支持行级锁和外键。
- MEMORY引擎:所有的数据都在内存中,数据的处理速度快,但是安全性不高。
MyISAM与InnoDB区别
Mysql 5.7 之后支持全文索引
MyISAM索引与InnoDB索引的区别?
- InnoDB索引是聚簇索引,MyISAM索引是非聚簇索引。
- InnoDB的主键索引的叶子节点存储着行数据,因此主键索引非常高效。
- MyISAM索引的叶子节点存储的是行数据地址,需要再寻址一次才能得到数据。
- InnoDB非主键索引的叶子节点存储的是主键和其他带索引的列数据,因此查询时做到覆盖索引会非常高效。
MYISAM 不支持主外键,不支持事务,而且是表锁,不适合高并发的操作,在缓存方面,只缓存索引,不缓存真实的数据,而InnoDB,支持事务,支持主外键,是行锁,适合高并发的操作,并且在缓存的时候不仅缓存索引还缓存真实数据,对内存要求较高
InnoDB引擎的4大特性
- 插入缓冲(insert buffer)
- 二次写(double write)
- 自适应哈希索引(ahi)
- 预读(read ahead)
存储引擎选择
如果没有特别的需求,使用默认的Innodb即可。
MyISAM:以读写插入为主的应用程序,比如博客系统、新闻门户网站。
Innodb:更新(删除)操作频率也高,或者要保证数据的完整性;并发量高,支持事务和外键。比如OA自动化办公系统。
索引
什么是索引?
索引是一种特殊的文件(InnoDB数据表上的索引是表空间的一个组成部分),它们包含着对数据表里所有记录的引用指针。
索引是一种数据结构。数据库索引,是数据库管理系统中一个排序的数据结构,以协助快速查询、更新数据库表中数据。索引的实现通常使用B树及其变种B+树。
更通俗的说,索引就相当于目录。为了方便查找书中的内容,通过对内容建立索引形成目录。索引是一个文件,它是要占据物理空间的。
索引下推
- 索引下推(index condition pushdown )简称ICP,在Mysql5.6的版本上推出,用于优化查询。
- 在不使用ICP的情况下,在使用**非主键索引(又叫普通索引或者二级索引)**进行查询时,存储引擎通过索引检索到数据,然后返回给MySQL服务器,服务器然后判断数据是否符合条件 。
- 在使用ICP的情况下,如果存在某些被索引的列的判断条件时,MySQL服务器将这一部分判断条件传递给存储引擎,然后由存储引擎通过判断索引是否符合MySQL服务器传递的条件,只有当索引符合条件时才会将数据检索出来返回给MySQL服务器 。
- 索引条件下推优化可以减少存储引擎查询基础表的次数,也可以减少MySQL服务器从存储引擎接收数据的次数。
索引下推在非主键索引上的优化,可以有效减少回表的次数,大大提升了查询的效率。
索引有哪些优缺点?
索引的优点
- 可以大大加快数据的检索速度,这也是创建索引的最主要的原因。
- 通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
索引的缺点
- 时间方面:创建索引和维护索引要耗费时间,具体地,当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,会降低增/改/删的执行效率;
- 空间方面:索引需要占物理空间。
索引使用场景(重点)
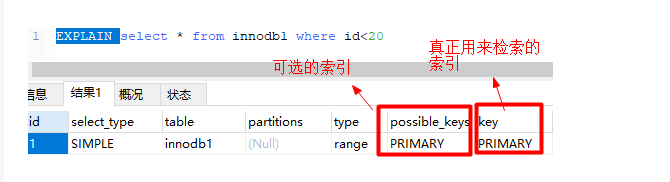
上图中,根据id查询记录,因为id字段仅建立了主键索引,因此此SQL执行可选的索引只有主键索引,如果有多个,最终会选一个较优的作为检索的依据。
-- 增加一个没有建立索引的字段
alter table innodb1 add sex char(1);
-- 按sex检索时可选的索引为null
EXPLAIN SELECT * from innodb1 where sex='男';
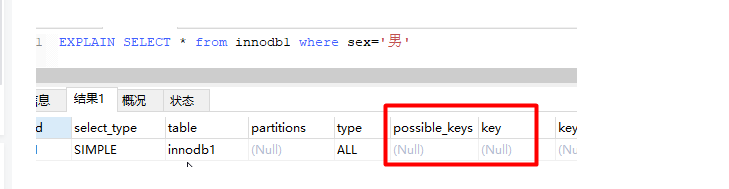
可以尝试在一个字段未建立索引时,根据该字段查询的效率,然后对该字段建立索引(
alter table 表名 add index(字段名)),同样的SQL执行的效率,你会发现查询效率会有明显的提升(数据量越大越明显)。
order by
当我们使用order by将查询结果按照某个字段排序时,如果该字段没有建立索引,那么执行计划会将查询出的所有数据使用外部排序(将数据从硬盘分批读取到内存使用内部排序,最后合并排序结果),这个操作是很影响性能的,因为需要将查询涉及到的所有数据从磁盘中读到内存(如果单条数据过大或者数据量过多都会降低效率),更无论读到内存之后的排序了。
但是如果我们对该字段建立索引alter table 表名 add index(字段名),那么由于索引本身是有序的,因此直接按照索引的顺序和映射关系逐条取出数据即可。而且如果分页的,那么只用取出索引表某个范围内的索引对应的数据,而不用像上述那取出所有数据进行排序再返回某个范围内的数据。(从磁盘取数据是最影响性能的)
join
对
join语句匹配关系(on)涉及的字段建立索引能够提高效率
索引覆盖
如果要查询的字段都建立过索引,那么引擎会直接在索引表中查询而不会访问原始数据(否则只要有一个字段没有建立索引就会做全表扫描),这叫索引覆盖。因此我们需要尽可能的在select后只写必要的查询字段,以增加索引覆盖的几率。
只需要在一棵索引树上就能获取SQL所需的所有列数据,无需回表,速度更快。
这里值得注意的是不要想着为每个字段建立索引,因为优先使用索引的优势就在于其体积小。
索引有哪几种类型?
主键索引: 数据列不允许重复,不允许为NULL,一个表只能有一个主键。
唯一索引: 数据列不允许重复,允许为NULL值,一个表允许多个列创建唯一索引。
- 可以通过
ALTER TABLE table_name ADD UNIQUE (column);创建唯一索引 - 可以通过
ALTER TABLE table_name ADD UNIQUE (column1,column2);创建唯一组合索引
普通索引: 基本的索引类型,没有唯一性的限制,允许为NULL值。
- 可以通过
ALTER TABLE table_name ADD INDEX index_name (column);创建普通索引 - 可以通过
ALTER TABLE table_name ADD INDEX index_name(column1, column2, column3);创建组合索引
全文索引: 是目前搜索引擎使用的一种关键技术。
- 可以通过
ALTER TABLE table_name ADD FULLTEXT (column);创建全文索引
索引的数据结构(b树,hash)
索引的数据结构和具体存储引擎的实现有关,在MySQL中使用较多的索引有Hash索引,B+树索引等,而我们经常使用的InnoDB存储引擎的默认索引实现为:B+树索引。对于哈希索引来说,底层的数据结构就是哈希表,因此在绝大多数需求为单条记录查询的时候,可以选择哈希索引,查询性能最快;其余大部分场景,建议选择BTree索引。
1)B树索引
mysql通过存储引擎取数据,基本上90%的人用的就是InnoDB了,按照实现方式分,InnoDB的索引类型目前只有两种:BTREE(B树)索引和HASH索引。B树索引是Mysql数据库中使用最频繁的索引类型,基本所有存储引擎都支持BTree索引。通常我们说的索引不出意外指的就是(B树)索引(实际是用B+树实现的,因为在查看表索引时,mysql一律打印BTREE,所以简称为B树索引)
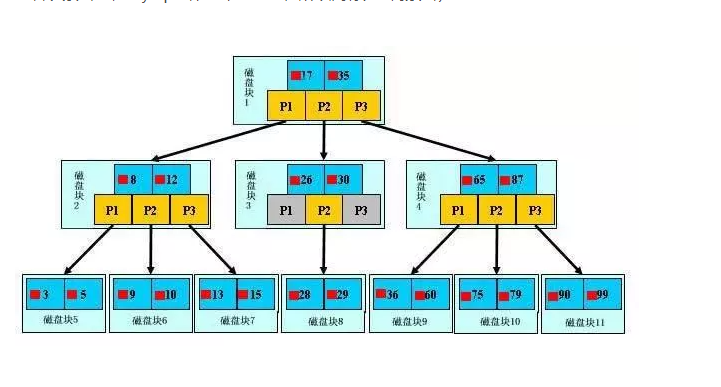
查询方式:
主键索引区:PI(关联保存的时数据的地址)按主键查询,
普通索引区:si(关联的id的地址,然后再到达上面的地址)。所以按主键查询,速度最快
B+tree性质:
1.)n棵子tree的节点包含n个关键字,不用来保存数据而是保存数据的索引。
2.)所有的叶子结点中包含了全部关键字的信息,及指向含这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接。
3.)所有的非终端结点可以看成是索引部分,结点中仅含其子树中的最大(或最小)关键字。
4.)B+ 树中,数据对象的插入和删除仅在叶节点上进行。
5.)B+树有2个头指针,一个是树的根节点,一个是最小关键码的叶节点。
2)哈希索引
简要说下,类似于数据结构中简单实现的HASH表(散列表)一样,当我们在mysql中用哈希索引时,主要就是通过Hash算法(常见的Hash算法有直接定址法、平方取中法、折叠法、除数取余法、随机数法),将数据库字段数据转换成定长的Hash值,与这条数据的行指针一并存入Hash表的对应位置;如果发生Hash碰撞(两个不同关键字的Hash值相同),则在对应Hash键下以链表形式存储。当然这只是简略模拟图。
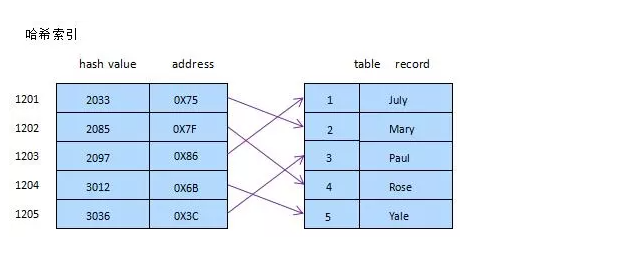
索引的基本原理
索引用来快速地寻找那些具有特定值的记录。如果没有索引,一般来说执行查询时遍历整张表。
索引的原理很简单,就是把无序的数据变成有序的查询
- 把创建了索引的列的内容进行排序
- 对排序结果生成倒排表
- 在倒排表内容上拼上数据地址链
- 在查询的时候,先拿到倒排表内容,再取出数据地址链,从而拿到具体数据
索引算法有哪些?
索引算法有 BTree算法和Hash算法
BTree算法
BTree是最常用的mysql数据库索引算法,也是mysql默认的算法。因为它不仅可以被用在=,>,>=,<,<=和between这些比较操作符上,而且还可以用于like操作符,只要它的查询条件是一个不以通配符开头的常量, 例如:
-- 只要它的查询条件是一个不以通配符开头的常量
select * from user where name like 'jack%';
-- 如果一通配符开头,或者没有使用常量,则不会使用索引,例如:
select * from user where name like '%jack';
Hash算法
Hash Hash索引只能用于对等比较,例如=,<=>(相当于=)操作符。由于是一次定位数据,不像BTree索引需要从根节点到枝节点,最后才能访问到页节点这样多次IO访问,所以检索效率远高于BTree索引。
索引设计的原则?
- 适合索引的列是出现在where子句中的列,或者连接子句中指定的列
- 基数较小的类,索引效果较差,没有必要在此列建立索引
- 使用短索引,如果对长字符串列进行索引,应该指定一个前缀长度,这样能够节省大量索引空间
- 不要过度索引。索引需要额外的磁盘空间,并降低写操作的性能。在修改表内容的时候,索引会进行更新甚至重构,索引列越多,这个时间就会越长。所以只保持需要的索引有利于查询即可。
创建索引的原则(重中之重)
索引虽好,但也不是无限制的使用,最好符合一下几个原则
1) 最左前缀匹配原则,组合索引非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。 带头大哥不能死,身后小弟不能断
2)较频繁作为查询条件的字段才去创建索引
3)更新频繁字段不适合创建索引
4)若是不能有效区分数据的列不适合做索引列(如性别,男女未知,最多也就三种,区分度实在太低)
5)尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可。
6)定义有外键的数据列一定要建立索引。
7)对于那些查询中很少涉及的列,重复值比较多的列不要建立索引。
8)对于定义为text、image和bit的数据类型的列不要建立索引。
创建索引的三种方式,删除索引
第一种方式:在执行CREATE TABLE时创建索引
CREATE TABLE user_index2 (
id INT auto_increment PRIMARY KEY,
first_name VARCHAR (16),
last_name VARCHAR (16),
id_card VARCHAR (18),
information text,
KEY name (first_name, last_name),
FULLTEXT KEY (information),
UNIQUE KEY (id_card)
);
第二种方式:使用ALTER TABLE命令去增加索引
ALTER TABLE table_name ADD INDEX index_name (column_list);
ALTER TABLE用来创建普通索引、UNIQUE索引或PRIMARY KEY索引。
其中table_name是要增加索引的表名,column_list指出对哪些列进行索引,多列时各列之间用逗号分隔。
索引名index_name可自己命名,缺省时,MySQL将根据第一个索引列赋一个名称。另外,ALTER TABLE允许在单个语句中更改多个表,因此可以在同时创建多个索引。
第三种方式:使用CREATE INDEX命令创建
CREATE INDEX index_name ON table_name (column_list);
CREATE INDEX可对表增加普通索引或UNIQUE索引。(但是,不能创建PRIMARY KEY索引)
删除索引
根据索引名删除普通索引、唯一索引、全文索引:alter table 表名 drop KEY 索引名
alter table user_index drop KEY name;
alter table user_index drop KEY id_card;
alter table user_index drop KEY information;
删除主键索引:alter table 表名 drop primary key(因为主键只有一个)。这里值得注意的是,如果主键自增长,那么不能直接执行此操作(自增长依赖于主键索引):

需要取消自增长再行删除:
alter table user_index
-- 重新定义字段
MODIFY id int,
drop PRIMARY KEY
但通常不会删除主键,因为设计主键一定与业务逻辑无关。
创建索引时需要注意什么?
- 非空字段:应该指定列为NOT NULL,除非你想存储NULL。在mysql中,含有空值的列很难进行查询优化,因为它们使得索引、索引的统计信息以及比较运算更加复杂。你应该用0、一个特殊的值或者一个空串代替空值;
- 取值离散大的字段:(变量各个取值之间的差异程度)的列放到联合索引的前面,可以通过count()函数查看字段的差异值,返回值越大说明字段的唯一值越多字段的离散程度高;
- 索引字段越小越好:数据库的数据存储以页为单位一页存储的数据越多一次IO操作获取的数据越大效率越高。
使用索引查询一定能提高查询的性能吗?为什么
通常,通过索引查询数据比全表扫描要快。但是我们也必须注意到它的代价。
- 索引需要空间来存储,也需要定期维护, 每当有记录在表中增减或索引列被修改时,索引本身也会被修改。 这意味着每条记录的INSERT,DELETE,UPDATE将为此多付出4,5 次的磁盘I/O。 因为索引需要额外的存储空间和处理,那些不必要的索引反而会使查询反应时间变慢。使用索引查询不一定能提高查询性能,索引范围查询(INDEX RANGE SCAN)适用于两种情况:
- 基于一个范围的检索,一般查询返回结果集小于表中记录数的30%
- 基于非唯一性索引的检索
百万级别或以上的数据如何删除
关于索引:由于索引需要额外的维护成本,因为索引文件是单独存在的文件,所以当我们对数据的增加,修改,删除,都会产生额外的对索引文件的操作,这些操作需要消耗额外的IO,会降低增/改/删的执行效率。所以,在我们删除数据库百万级别数据的时候,查询MySQL官方手册得知删除数据的速度和创建的索引数量是成正比的。
- 所以我们想要删除百万数据的时候可以先删除索引(此时大概耗时三分多钟)
- 然后删除其中无用数据(此过程需要不到两分钟)
- 删除完成后重新创建索引(此时数据较少了)创建索引也非常快,约十分钟左右。
- 与之前的直接删除绝对是要快速很多,更别说万一删除中断,一切删除会回滚。那更是坑了。
前缀索引
语法:index(field(10)),使用字段值的前10个字符建立索引,默认是使用字段的全部内容建立索引。
前提:前缀的标识度高。比如密码就适合建立前缀索引,因为密码几乎各不相同。
实操的难度:在于前缀截取的长度。
我们可以利用select count(*)/count(distinct left(password,prefixLen));,通过从调整prefixLen的值(从1自增)查看不同前缀长度的一个平均匹配度,接近1时就可以了(表示一个密码的前prefixLen个字符几乎能确定唯一一条记录)
什么是最左前缀原则?什么是最左匹配原则
- 顾名思义,就是最左优先,在创建多列索引时,要根据业务需求,where子句中使用最频繁的一列放在最左边。
- 最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
- =和in可以乱序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式
B树和B+树的区别
- 在B树中,你可以将键和值存放在内部节点和叶子节点;但在B+树中,内部节点都是键,没有值,叶子节点同时存放键和值。
- B+树的叶子节点有一条链相连,而B树的叶子节点各自独立。
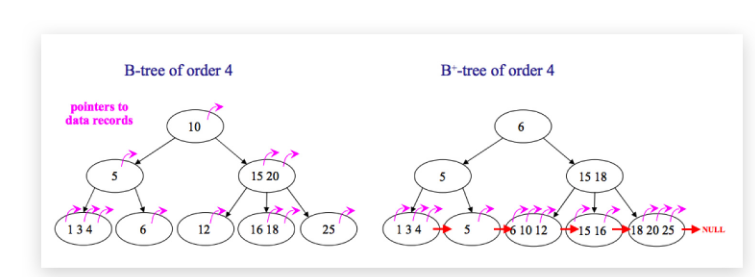
使用B树的好处
B树可以在内部节点同时存储键和值,因此,把频繁访问的数据放在靠近根节点的地方将会大大提高热点数据的查询效率。这种特性使得B树在特定数据重复多次查询的场景中更加高效。
使用B+树的好处
由于B+树的内部节点只存放键,不存放值,因此,一次读取,可以在内存页中获取更多的键,有利于更快地缩小查找范围。 B+树的叶节点由一条链相连,因此,当需要进行一次全数据遍历的时候,B+树只需要使用O(logN)时间找到最小的一个节点,然后通过链进行O(N)的顺序遍历即可。而B树则需要对树的每一层进行遍历,这会需要更多的内存置换次数,因此也就需要花费更多的时间
B树与B+树的详解
https://www.cnblogs.com/lianzhilei/p/11250589.html
B+树是B树的一个变种,其也是一种多路平衡搜索树,其与B树的主要区别是:
- 非叶子节点的指针数量与关键字数量相等;
- 非叶子节点的子树指针P[i],指向关键字值属于[K[i],K[i+1])的子树(B树是开区间,B+树是左闭右开,也就是说B树不允许关键字重复,而B+树允许);
- 所有关键字都在叶子节点出现,所有的叶子节点增加了一个链指针(稠密索引,且链表中的关键字切好是有序的);
- 非叶子节点相当于是叶子节点的索引(稀疏索引),叶子节点相当于是存储数据的数据层。
https://blog.csdn.net/xdzhouxin/article/details/80015424
Hash索引和B+树所有有什么区别或者说优劣呢?
首先要知道Hash索引和B+树索引的底层实现原理:
hash索引底层就是hash表,进行查找时,调用一次hash函数就可以获取到相应的键值,之后进行回表查询获得实际数据。
B+树底层实现是多路平衡查找树。对于每一次的查询都是从根节点出发,查找到叶子节点方可以获得所查键值,然后根据查询判断是否需要回表查询数据。
那么可以看出他们有以下的不同:
- hash索引进行等值查询更快(一般情况下),但是却无法进行范围查询。
因为在hash索引中经过hash函数建立索引之后,索引的顺序与原顺序无法保持一致,不能支持范围查询。而B+树的的所有节点皆遵循(左节点小于父节点,右节点大于父节点,多叉树也类似),天然支持范围。
- hash索引不支持使用索引进行排序,原理同上。
- **hash索引不支持模糊查询以及多列索引的最左前缀匹配。**原理也是因为hash函数的不可预测。AAAA和AAAAB的索引没有相关性。
- hash索引任何时候都避免不了回表查询数据,而B+树在符合某些条件(聚簇索引,覆盖索引等)的时候可以只通过索引完成查询。
- hash索引虽然在等值查询上较快,但是不稳定。性能不可预测,当某个键值存在大量重复的时候,发生hash碰撞,此时效率可能极差。而B+树的查询效率比较稳定,对于所有的查询都是从根节点到叶子节点,且树的高度较低。
因此,在大多数情况下,直接选择B+树索引可以获得稳定且较好的查询速度。而不需要使用hash索引。
数据库为什么使用B+树而不是B树
- B树只适合随机检索,而B+树同时支持随机检索和顺序检索;
- B+树空间利用率更高,可减少I/O次数,磁盘读写代价更低。一般来说,索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上。这样的话,索引查找过程中就要产生磁盘I/O消耗。B+树的内部结点并没有指向关键字具体信息的指针,只是作为索引使用,其内部结点比B树小,盘块能容纳的结点中关键字数量更多,一次性读入内存中可以查找的关键字也就越多,相对的,IO读写次数也就降低了。而IO读写次数是影响索引检索效率的最大因素;
- B+树的查询效率更加稳定。B树搜索有可能会在非叶子结点结束,越靠近根节点的记录查找时间越短,只要找到关键字即可确定记录的存在,其性能等价于在关键字全集内做一次二分查找。而在B+树中,顺序检索比较明显,随机检索时,任何关键字的查找都必须走一条从根节点到叶节点的路,所有关键字的查找路径长度相同,导致每一个关键字的查询效率相当。
- B-树在提高了磁盘IO性能的同时并没有解决元素遍历的效率低下的问题。**B+树的叶子节点使用指针顺序连接在一起,只要遍历叶子节点就可以实现整棵树的遍历。**而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作。
- **增删文件(节点)时,效率更高。**因为B+树的叶子节点包含所有关键字,并以有序的链表结构存储,这样可很好提高增删效率。
B+树在满足聚簇索引和覆盖索引的时候不需要回表查询数据,
在B+树的索引中,叶子节点可能存储了当前的key值,也可能存储了当前的key值以及整行的数据,这就是聚簇索引和非聚簇索引。 在InnoDB中,只有主键索引是聚簇索引,如果**没有主键,则挑选一个唯一键建立聚簇索引。**如果没有唯一键,则隐式的生成一个键来建立聚簇索引。
当查询使用聚簇索引时,在对应的叶子节点,可以获取到整行数据,因此不用再次进行回表查询。
什么是聚簇索引?何时使用聚簇索引与非聚簇索引
- 聚簇索引:将数据存储与索引放到了一块,找到索引也就找到了数据
- 非聚簇索引:**将数据存储于索引分开结构,**索引结构的叶子节点指向了数据的对应行,myisam通过key_buffer把索引先缓存到内存中,当需要访问数据时(通过索引访问数据),在内存中直接搜索索引,然后通过索引找到磁盘相应数据,这也就是为什么索引不在key buffer命中时,速度慢的原因
澄清一个概念:innodb中,在聚簇索引之上创建的索引称之为辅助索引,辅助索引访问数据总是需要二次查找,非聚簇索引都是辅助索引,像复合索引、前缀索引、唯一索引,辅助索引叶子节点存储的不再是行的物理位置,而是主键值
何时使用聚簇索引与非聚簇索引
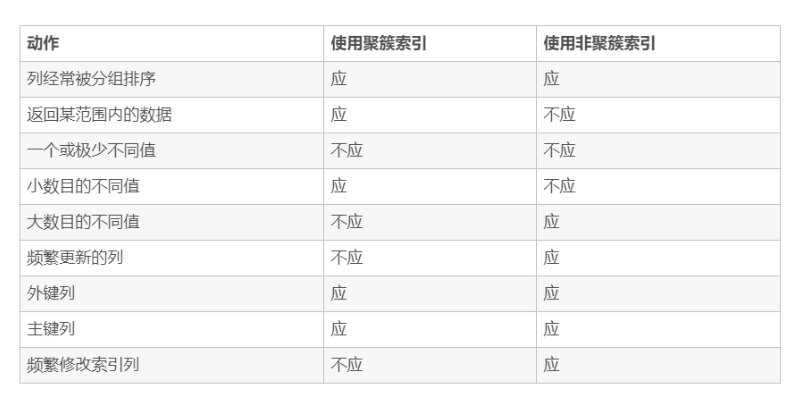
非聚簇索引一定会回表查询吗?
不一定,这涉及到查询语句所要求的字段是否全部命中了索引,如果全部命中了索引,那么就不必再进行回表查询。
举个简单的例子,假设我们在员工表的年龄上建立了索引,那么当进行select age from employee where age < 20的查询时,在索引的叶子节点上,已经包含了age信息,不会再次进行回表查询。
mysql中的回表查询与索引覆盖
回表查询
要说回表查询,先要从InnoDB的索引实现说起。InnoDB有两大类索引,一类是聚集索引(Clustered Index),一类是普通索引(Secondary Index)。
InnoDB的聚集索引
InnoDB聚集索引的叶子节点存储行记录,因此InnoDB必须要有且只有一个聚集索引。
1.如果表定义了PK(Primary Key,主键),那么PK就是聚集索引。
2.如果表没有定义PK,则第一个NOT NULL UNIQUE的列就是聚集索引。
3.否则InnoDB会另外创建一个隐藏的ROWID作为聚集索引。
这种机制使得基于PK的查询速度非常快,因为直接定位的行记录。
InnoDB的普通索引
InnoDB普通索引的叶子节点存储主键值(MyISAM则是存储的行记录头指针)。
什么是回表查询
假设有个t表(id PK, name KEY, sex, flag),这里的id是聚集索引,name则是普通索引。

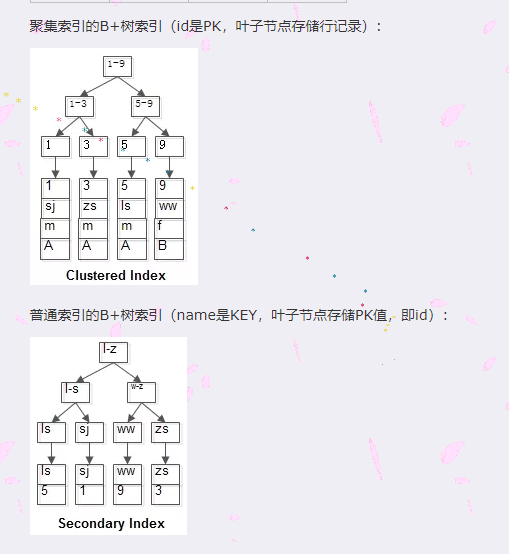
普通索引因为无法直接定位行记录,其查询过程在通常情况下是需要扫描两遍索引树的。
select * from t where name = 'lisi';
这里的执行过程是这样的:
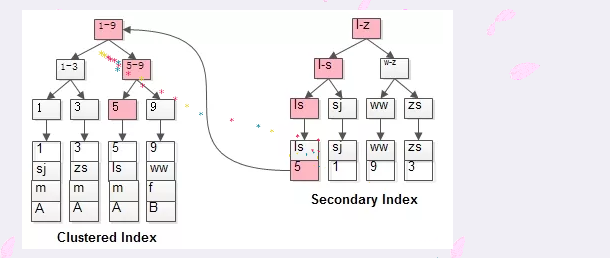
粉红色的路径需要扫描两遍索引树,第一遍先通过普通索引定位到主键值id=5,然后第二遍再通过聚集索引定位到具体行记录。这就是所谓的回表查询,即先定位主键值,再根据主键值定位行记录,性能相对于只扫描一遍聚集索引树的性能要低一些。
联合索引是什么?为什么需要注意联合索引中的顺序?
MySQL可以使用多个字段同时建立一个索引,叫做联合索引。在联合索引中,如果想要命中索引,需要按照建立索引时的字段顺序挨个使用,否则无法命中索引。
具体原因为:
MySQL使用索引时需要索引有序,假设现在建立了"name,age,school"的联合索引,那么索引的排序为: 先按照name排序,如果name相同,则按照age排序,如果age的值也相等,则按照school进行排序。
当进行查询时,此时索引仅仅按照name严格有序,因此必须首先使用name字段进行等值查询,之后对于匹配到的列而言,其按照age字段严格有序,此时可以使用age字段用做索引查找,以此类推。因此在建立联合索引的时候应该注意索引列的顺序,一般情况下,将查询需求频繁或者字段选择性高的列放在前面。此外可以根据特例的查询或者表结构进行单独的调整。
事务
事务隔离级别:未提交读时,写数据只会锁住相应的行。
事务隔离级别为:可重复读时,写数据会锁住整张表。
事务隔离级别为:串行化时,读写数据都会锁住整张表。
什么是数据库事务?
事务是一个不可分割的数据库操作序列,也是数据库并发控制的基本单位,其执行的结果必须使数据库从一种一致性状态变到另一种一致性状态。事务是逻辑上的一组操作,要么都执行,要么都不执行。
事务最经典也经常被拿出来说例子就是转账了。
假如小明要给小红转账1000元,这个转账会涉及到两个关键操作就是:将小明的余额减少1000元,将小红的余额增加1000元。万一在这两个操作之间突然出现错误比如银行系统崩溃,导致小明余额减少而小红的余额没有增加,这样就不对了。事务就是保证这两个关键操作要么都成功,要么都要失败。
事物的四大特性(ACID)介绍一下?
关系性数据库需要遵循ACID规则,具体内容如下:
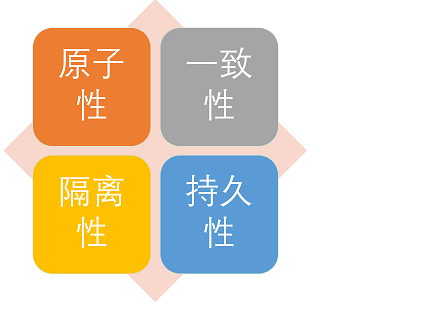
- 原子性: 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
- 一致性: 执行事务前后,数据保持一致,多个事务对同一个数据读取的结果是相同的;
- 隔离性: 并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
- 持久性: 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
什么是脏读?幻读?不可重复读?
- 脏读(Drity Read):某个事务已更新一份数据,另一个事务在此时读取了同一份数据,由于某些原因,前一个RollBack了操作,则后一个事务所读取的数据就会是不正确的。
- 不可重复读(Non-repeatable read):在一个事务的两次查询之中数据不一致,这可能是两次查询过程中间插入了一个事务更新的原有的数据。
- 幻读(Phantom Read):在一个事务的两次查询中数据行数不一致,例如有一个事务查询了几列(Row)数据,而另一个事务却在此时插入了新的几列数据,先前的事务在接下来的查询中,就会发现有几列数据是它先前所没有的。
什么是事务的隔离级别?MySQL的默认隔离级别是什么?
为了达到事务的四大特性,数据库定义了4种不同的事务隔离级别,由低到高依次为Read uncommitted、Read committed、Repeatable read、Serializable,这四个级别可以逐个解决脏读、不可重复读、幻读这几类问题。
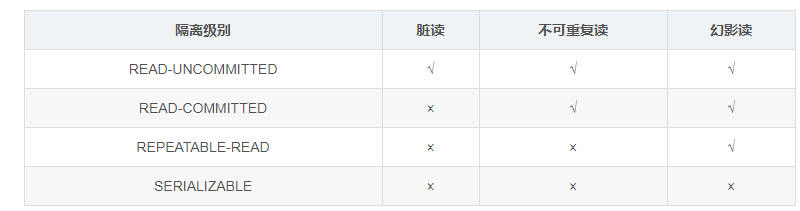
SQL 标准定义了四个隔离级别:
- READ-UNCOMMITTED(读取未提交): 最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。
- READ-COMMITTED(读取已提交): 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。
- REPEATABLE-READ(可重复读): 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
- SERIALIZABLE(可序列化): 最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
这里需要注意的是:Mysql 默认采用的 REPEATABLE_READ隔离级别 Oracle 默认采用的 READ_COMMITTED隔离级别
事务隔离机制的实现基于锁机制和并发调度。其中并发调度使用的是MVVC(多版本并发控制),通过保存修改的旧版本信息来支持并发一致性读和回滚等特性。
因为隔离级别越低,事务请求的锁越少,所以大部分数据库系统的隔离级别都是READ-COMMITTED(读取提交内容):,但是你要知道的是InnoDB 存储引擎默认使用 **REPEATABLE-READ(可重读)**并不会有任何性能损失。
InnoDB 存储引擎在 分布式事务 的情况下一般会用到**SERIALIZABLE(可串行化)**隔离级别。
锁
对MySQL的锁了解吗
当数据库有并发事务的时候,可能会产生数据的不一致,这时候需要一些机制来保证访问的次序,锁机制就是这样的一个机制。
就像酒店的房间,如果大家随意进出,就会出现多人抢夺同一个房间的情况,而在房间上装上锁,申请到钥匙的人才可以入住并且将房间锁起来,其他人只有等他使用完毕才可以再次使用。
隔离级别与锁的关系
在Read Uncommitted级别下,读取数据不需要加共享锁,这样就不会跟被修改的数据上的排他锁冲突
在Read Committed级别下,读操作需要加共享锁,但是在语句执行完以后释放共享锁;
在Repeatable Read级别下,读操作需要加共享锁,但是在事务提交之前并不释放共享锁,也就是必须等待事务执行完毕以后才释放共享锁。
SERIALIZABLE 是限制性最强的隔离级别,因为该级别锁定整个范围的键,并一直持有锁,直到事务完成。
按照锁的粒度分数据库锁有哪些?锁机制与InnoDB锁算法
在关系型数据库中,可以按照锁的粒度把数据库锁分为行级锁(INNODB引擎)、表级锁(MYISAM引擎)和页级锁(BDB引擎 )。
MyISAM和InnoDB存储引擎使用的锁:
- MyISAM采用表级锁(table-level locking)。
- InnoDB支持行级锁(row-level locking)和表级锁,默认为行级锁
行级锁,表级锁和页级锁对比
行级锁 行级锁是Mysql中锁定粒度最细的一种锁,表示**只针对当前操作的行进行加锁。**行级锁能大大减少数据库操作的冲突。其加锁粒度最小,但加锁的开销也最大。行级锁分为共享锁 和 排他锁。
特点:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
表级锁 表级锁是MySQL中锁定粒度最大的一种锁,表示对当前操作的整张表加锁,它实现简单,资源消耗较少,被大部分MySQL引擎支持。最常使用的MYISAM与INNODB都支持表级锁定。表级锁定分为表共享读锁(共享锁)与表独占写锁(排他锁)。
特点:开销小,加锁快;不会出现死锁;锁定粒度大,发出锁冲突的概率最高,并发度最低。
页级锁 页级锁是MySQL中锁定粒度介于行级锁和表级锁中间的一种锁。表级锁速度快,但冲突多,行级冲突少,但速度慢。所以取了折衷的页级,一次锁定相邻的一组记录。
特点:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般
从锁的类别上分MySQL都有哪些锁呢?像上面那样子进行锁定岂不是有点阻碍并发效率了
从锁的类别上来讲,有共享锁和排他锁。
共享锁: 又叫做读锁。 当用户要进行数据的读取时,对数据加上共享锁。共享锁可以同时加上多个。
排他锁: 又叫做写锁。 当用户要进行数据的写入时,对数据加上排他锁。排他锁只可以加一个,他和其他的排他锁,共享锁都相斥。
用上面的例子来说就是用户的行为有两种,一种是来看房,多个用户一起看房是可以接受的。 一种是真正的入住一晚,在这期间,无论是想入住的还是想看房的都不可以。
锁的粒度取决于具体的存储引擎,InnoDB实现了行级锁,页级锁,表级锁。
他们的加锁开销从大到小,并发能力也是从大到小。
MySQL中InnoDB引擎的行锁是怎么实现的?
答:InnoDB是基于索引来完成行锁
例: select * from tab_with_index where id = 1 for update;
for update 可以根据条件来完成行锁锁定,并且 id 是有索引键的列,如果 id 不是索引键那么InnoDB将完成表锁,并发将无从谈起
InnoDB存储引擎的锁的算法有三种
- Record lock:单个行记录上的锁
- Gap lock:间隙锁,锁定一个范围,不包括记录本身
- Next-key lock:record+gap 锁定一个范围,包含记录本身
相关知识点:
- innodb对于行的查询使用next-key lock
- Next-locking keying为了解决Phantom Problem幻读问题
- 当查询的索引含有唯一属性时,将next-key lock降级为record key
- Gap锁设计的目的是为了阻止多个事务将记录插入到同一范围内,而这会导致幻读问题的产生
- 有两种方式显式关闭gap锁:(除了外键约束和唯一性检查外,其余情况仅使用record lock) A. 将事务隔离级别设置为RC B. 将参数innodb_locks_unsafe_for_binlog设置为1
什么是死锁?怎么解决?
死锁是指两个或多个事务在同一资源上相互占用,并请求锁定对方的资源,从而导致恶性循环的现象。
常见的解决死锁的方法
1、如果不同程序会并发存取多个表,尽量约定以相同的顺序访问表,可以大大降低死锁机会。
2、在同一个事务中,尽可能做到一次锁定所需要的所有资源,减少死锁产生概率;
3、对于非常容易产生死锁的业务部分,可以尝试使用升级锁定颗粒度,通过表级锁定来减少死锁产生的概率;
如果业务处理不好可以用分布式事务锁或者使用乐观锁
数据库的乐观锁和悲观锁是什么?怎么实现的?
数据库管理系统(DBMS)中的并发控制的任务是确保在多个事务同时存取数据库中同一数据时不破坏事务的隔离性和统一性以及数据库的统一性。乐观并发控制(乐观锁)和悲观并发控制(悲观锁)是并发控制主要采用的技术手段。
悲观锁:假定会发生并发冲突,屏蔽一切可能违反数据完整性的操作。在查询完数据的时候就把事务锁起来,直到提交事务。实现方式:使用数据库中的锁机制
乐观锁:假设不会发生并发冲突,只在提交操作时检查是否违反数据完整性。在修改数据的时候把事务锁起来,通过version的方式来进行锁定。实现方式:乐一般会使用版本号机制或CAS算法实现。
两种锁的使用场景
从上面对两种锁的介绍,我们知道两种锁各有优缺点,不可认为一种好于另一种,像乐观锁适用于写比较少的情况下(多读场景),即冲突真的很少发生的时候,这样可以省去了锁的开销,加大了系统的整个吞吐量。
但如果是多写的情况,一般会经常产生冲突,这就会导致上层应用会不断的进行retry,这样反倒是降低了性能,所以一般多写的场景下用悲观锁就比较合适。
视图
为什么要使用视图?什么是视图?
为了提高复杂SQL语句的复用性和表操作的安全性,MySQL数据库管理系统提供了视图特性。所谓视图,本质上是一种虚拟表,在物理上是不存在的,其内容与真实的表相似,包含一系列带有名称的列和行数据。但是,视图并不在数据库中以储存的数据值形式存在。行和列数据来自定义视图的查询所引用基本表,并且在具体引用视图时动态生成。
视图使开发者只关心感兴趣的某些特定数据和所负责的特定任务,只能看到视图中所定义的数据,而不是视图所引用表中的数据,从而提高了数据库中数据的安全性。
视图有哪些特点?
视图的特点如下:
- 视图的列可以来自不同的表,是表的抽象和在逻辑意义上建立的新关系。
- 视图是由基本表(实表)产生的表(虚表)。
- 视图的建立和删除不影响基本表。
- 对视图内容的更新(添加,删除和修改)直接影响基本表。
- 当视图来自多个基本表时,不允许添加和删除数据。
视图的操作包括创建视图,查看视图,删除视图和修改视图。
视图的使用场景有哪些?
视图根本用途:简化sql查询,提高开发效率。如果说还有另外一个用途那就是兼容老的表结构。
下面是视图的常见使用场景:
- 重用SQL语句;
- 简化复杂的SQL操作。在编写查询后,可以方便的重用它而不必知道它的基本查询细节;
- 使用表的组成部分而不是整个表;
- 保护数据。可以给用户授予表的特定部分的访问权限而不是整个表的访问权限;
- 更改数据格式和表示。视图可返回与底层表的表示和格式不同的数据。
视图的优点
- 查询简单化。视图能简化用户的操作
- 数据安全性。视图使用户能以多种角度看待同一数据,能够对机密数据提供安全保护
- 逻辑数据独立性。视图对重构数据库提供了一定程度的逻辑独立性
视图的缺点
-
性能。数据库必须把视图的查询转化成对基本表的查询,如果这个视图是由一个复杂的多表查询所定义,那么,即使是视图的一个简单查询,数据库也把它变成一个复杂的结合体,需要花费一定的时间。
-
修改限制。当用户试图修改视图的某些行时,数据库必须把它转化为对基本表的某些行的修改。事实上,当从视图中插入或者删除时,情况也是这样。对于简单视图来说,这是很方便的,但是,对于比较复杂的视图,可能是不可修改的
这些视图有如下特征:1.有UNIQUE等集合操作符的视图。2.有GROUP BY子句的视图。3.有诸如AVG\SUM\MAX等聚合函数的视图。 4.使用DISTINCT关键字的视图。5.连接表的视图(其中有些例外)
什么是游标?
游标是系统为用户开设的一个数据缓冲区,存放SQL语句的执行结果,每个游标区都有一个名字。用户可以通过游标逐一获取记录并赋给主变量,交由主语言进一步处理。
存储过程与函数
什么是存储过程?有哪些优缺点?
**存储过程是一个预编译的SQL语句,优点是允许模块化的设计,就是说只需要创建一次,以后在该程序中就可以调用多次。**如果某次操作需要执行多次SQL,使用存储过程比单纯SQL语句执行要快。
优点
1)存储过程是预编译过的,执行效率高。
2)存储过程的代码直接存放于数据库中,通过存储过程名直接调用,减少网络通讯。
3)安全性高,执行存储过程需要有一定权限的用户。
4)存储过程可以重复使用,减少数据库开发人员的工作量。
缺点
1)调试麻烦,但是用 PL/SQL Developer 调试很方便!弥补这个缺点。
2)移植问题,数据库端代码当然是与数据库相关的。但是如果是做工程型项目,基本不存在移植问题。
3)重新编译问题,因为后端代码是运行前编译的,如果带有引用关系的对象发生改变时,受影响的存储过程、包将需要重新编译(不过也可以设置成运行时刻自动编译)。
4)如果在一个程序系统中大量的使用存储过程,到程序交付使用的时候随着用户需求的增加会导致数据结构的变化,接着就是系统的相关问题了,最后如果用户想维护该系统可以说是很难很难、而且代价是空前的,维护起来更麻烦。
触发器
什么是触发器?触发器的使用场景有哪些?
触发器是用户定义在关系表上的一类由事件驱动的特殊的存储过程。触发器是指一段代码,当触发某个事件时,自动执行这些代码。
使用场景
- 可以通过数据库中的相关表实现级联更改。
- 实时监控某张表中的某个字段的更改而需要做出相应的处理。
- 例如可以生成某些业务的编号。
- 注意不要滥用,否则会造成数据库及应用程序的维护困难。
- 大家需要牢记以上基础知识点,重点是理解数据类型CHAR和VARCHAR的差异,表存储引擎InnoDB和MyISAM的区别。
MySQL中都有哪些触发器?
在MySQL数据库中有如下六种触发器:
- Before Insert
- After Insert
- Before Update
- After Update
- Before Delete
- After Delete
常用SQL语句
SQL语句主要分为哪几类
数据定义语言DDL(Data Ddefinition Language)CREATE,DROP,ALTER
主要为以上操作 即对逻辑结构等有操作的,其中包括表结构,视图和索引。
数据查询语言DQL(Data Query Language)SELECT
这个较为好理解 即查询操作,以select关键字。各种简单查询,连接查询等 都属于DQL。
数据操纵语言DML(Data Manipulation Language)INSERT,UPDATE,DELETE
主要为以上操作 即对数据进行操作的,对应上面所说的查询操作 DQL与DML共同构建了多数初级程序员常用的增删改查操作。而查询是较为特殊的一种 被划分到DQL中。
数据控制功能DCL(Data Control Language)GRANT,REVOKE,COMMIT,ROLLBACK
主要为以上操作 即对数据库安全性完整性等有操作的,可以简单的理解为权限控制等。
sql语句的执行先后
查询语句的执行顺序
- from
- on
- join
- where
- group by(开始使用select中的别名,后面的语句中都可以使用)
- avg,sum…
- having
- select
- distinct
- order by
- limit
查找一个有大量数据的表中最后一条数据
SELECT * FROM student WHERE id=(SELECT MAX(id) FROM student)
SELECT * FROM student ORDER BY id DESC LIMIT 1
补充:https://blog.csdn.net/qq_39588003/article/details/90084255
EXISTS 会对外表进行循环查询匹配,它不在乎后面的内表子查询的返回值是什么,只在乎有没有存在返回值,存在返回值,则条件为真,该条数据匹配成功,加入查询结果集中;如果没有返回值,条件为假,丢弃该条数据。
Exists:EXISTS写法需要注意子查询中的条件语句一般需要带上外查询的表做关联,不然子查询的条件可能会一直为真,或者一直为假,外查询的表进行循环匹配的时候,要么全部都查询出来,要么一条也没有。
嵌套子查询
嵌套子查询的执行不依赖于外部的查询。
执行过程:
· (1)执行子查询,其结果不被显示,而是传递给外部查询,作为外部查询的条件使用。
· (2)执行外部查询,并显示整个结果。
相关子查询
相关子查询的执行依赖于外部查询。多数情况下是子查询的WHERE子句中引用了外部查询的表。
执行过程:
· (1)从外层查询中取出一个元组,将元组相关列的值传给内层查询。
· (2)执行内层查询,得到子查询操作的值。
· (3)外查询根据子查询返回的结果或结果集得到满足条件的行。
· (4)然后外层查询取出下一个元组重复做步骤1-3,直到外层的元组全部处理完毕。
https://blog.csdn.net/dta0502/article/details/92652156
Mysql练习题
https://www.cnblogs.com/kangxinxin/p/11585935.html
超键、候选键、主键、外键分别是什么?
- 超键:在关系中能唯一标识元组的属性集称为关系模式的超键。一个属性可以为作为一个超键,多个属性组合在一起也可以作为一个超键。超键包含候选键和主键。
- 候选键:是最小超键,即没有冗余元素的超键。
- 主键:数据库表中对储存数据对象予以唯一和完整标识的数据列或属性的组合。一个数据列只能有一个主键,且主键的取值不能缺失,即不能为空值(Null)。
- 外键:在一个表中存在的另一个表的主键称此表的外键。
SQL 约束有哪几种?
SQL 约束有哪几种?
- NOT NULL: 用于控制字段的内容一定不能为空(NULL)。
- UNIQUE: 控件字段内容不能重复,一个表允许有多个 Unique 约束。
- PRIMARY KEY: 也是用于控件字段内容不能重复,但它在一个表只允许出现一个。
- FOREIGN KEY: 用于预防破坏表之间连接的动作,也能防止非法数据插入外键列,因为它必须是它指向的那个表中的值之一。
- CHECK: 用于控制字段的值范围。
六种关联查询
- 交叉连接(CROSS JOIN)
- 内连接(INNER JOIN)
- 外连接(LEFT JOIN/RIGHT JOIN)
- 联合查询(UNION与UNION ALL)
- 全连接(FULL JOIN)
- 交叉连接(CROSS JOIN)
SELECT * FROM A,B(,C)或者SELECT * FROM A CROSS JOIN B (CROSS JOIN C)#没有任何关联条件,结果是笛卡尔积,结果集会很大,没有意义,很少使用内连接(INNER JOIN)SELECT * FROM A,B WHERE A.id=B.id或者SELECT * FROM A INNER JOIN B ON A.id=B.id多表中同时符合某种条件的数据记录的集合,INNER JOIN可以缩写为JOIN
内连接分为三类
- 等值连接:ON A.id=B.id
- 不等值连接:ON A.id > B.id
- 自连接:SELECT * FROM A T1 INNER JOIN A T2 ON T1.id=T2.pid
外连接(LEFT JOIN/RIGHT JOIN)
- 左外连接:LEFT OUTER JOIN, 以左表为主,先查询出左表,按照ON后的关联条件匹配右表,没有匹配到的用NULL填充,可以简写成LEFT JOIN
- 右外连接:RIGHT OUTER JOIN, 以右表为主,先查询出右表,按照ON后的关联条件匹配左表,没有匹配到的用NULL填充,可以简写成RIGHT JOIN
联合查询(UNION与UNION ALL)
SELECT * FROM A UNION SELECT * FROM B UNION ...
- 就是把多个结果集集中在一起,UNION前的结果为基准,需要注意的是联合查询的列数要相等,相同的记录行会合并
- 如果使用UNION ALL,不会合并重复的记录行
- 效率 UNION 高于 UNION ALL
全连接(FULL JOIN)
- MySQL不支持全连接
- 可以使用LEFT JOIN 和UNION和RIGHT JOIN联合使用
SELECT * FROM A LEFT JOIN B ON A.id=B.id UNIONSELECT * FROM A RIGHT JOIN B ON A.id=B.id
表连接面试题
有2张表,1张R、1张S,R表有ABC三列,S表有CD两列,表中各有三条记录。
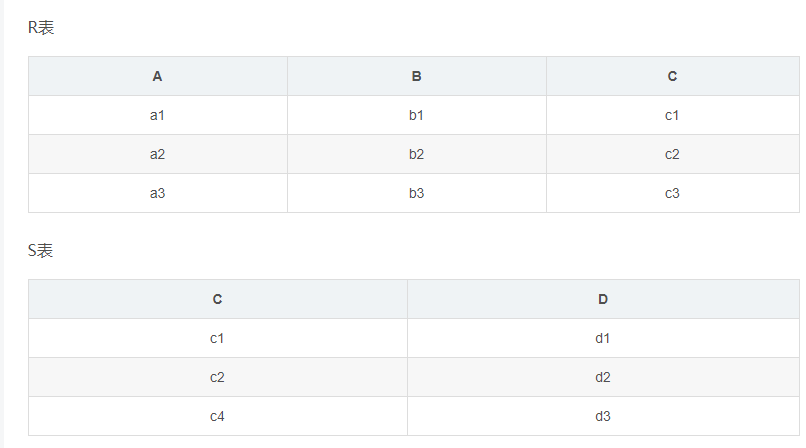
- 交叉连接(笛卡尔积):
select r.*,s.* from r,s
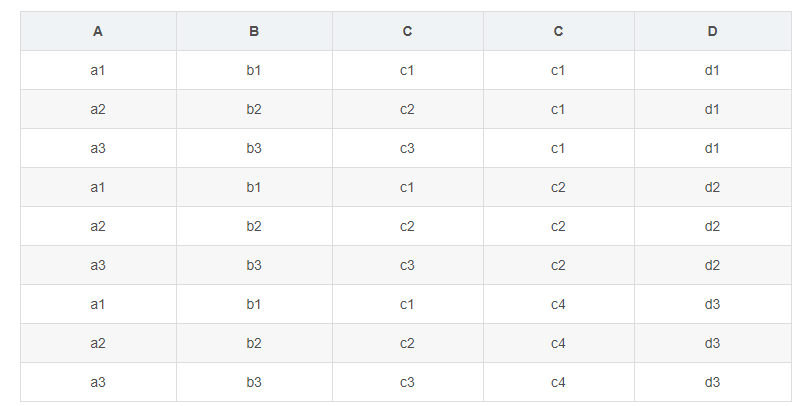
内连接结果:
select r.*,s.* from r inner join s on r.c=s.c

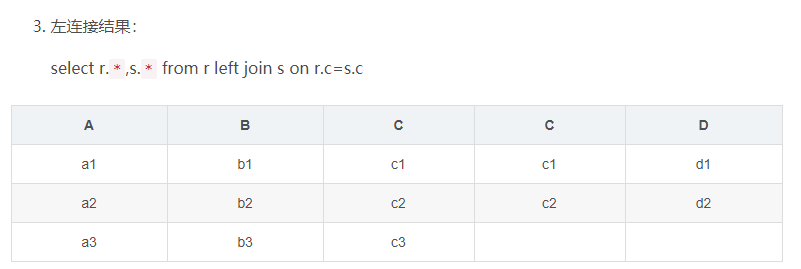

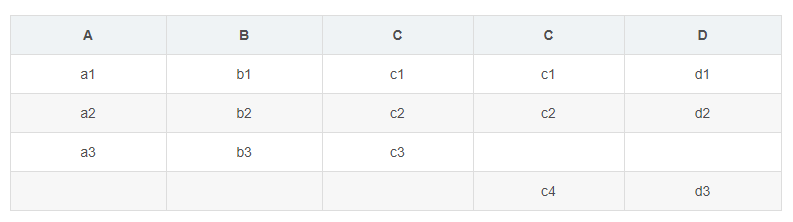
全表连接的结果(MySql不支持,Oracle支持):
select r.*,s.* from r full join s on r.c=s.c
什么是子查询
- 条件:一条SQL语句的查询结果做为另一条查询语句的条件或查询结果
- 嵌套:多条SQL语句嵌套使用,内部的SQL查询语句称为子查询。
子查询的三种情况
- 子查询是单行单列的情况:结果集是一个值,父查询使用:=、 <、 > 等运算符
-- 查询工资最高的员工是谁?
select * from employee where salary=(select max(salary) from employee);
- 子查询是多行单列的情况:结果集类似于一个数组,父查询使用:in 运算符
-- 查询工资最高的员工是谁?
select * from employee where salary=(select max(salary) from employee);
- 子查询是多行多列的情况:结果集类似于一张虚拟表,不能用于where条件,用于select子句中做为子表
-- 1) 查询出2011年以后入职的员工信息
-- 2) 查询所有的部门信息,与上面的虚拟表中的信息比对,找出所有部门ID相等的员工。
select * from dept d, (select * from employee where join_date > '2011-1-1') e where e.dept_id = d.id;
-- 使用表连接:
select d.*, e.* from dept d inner join employee e on d.id = e.dept_id where e.join_date > '2011-1-1'
mysql中 in 和 exists 区别
mysql中的in语句是把外表和内表作hash 连接,而exists语句是对外表作loop循环,**每次loop循环再对内表进行查询。**一直大家都认为exists比in语句的效率要高,这种说法其实是不准确的。这个是要区分环境的。
- 如果查询的两个表大小相当,那么用in和exists差别不大。
- 如果两个表中一个较小,一个是大表,则子查询表大的用exists,子查询表小的用in。
- not in 和not exists:如果查询语句使用了not in,那么内外表都进行全表扫描,没有用到索引;而not extsts的子查询依然能用到表上的索引。所以无论那个表大,用not exists都比not in要快。
varchar与char的区别
char的特点
- char表示定长字符串,长度是固定的;
- 如果插入数据的长度小于char的固定长度时,则用空格填充;
- 因为长度固定,所以存取速度要比varchar快很多,甚至能快50%,但正因为其长度固定,所以会占据多余的空间,是空间换时间的做法;
- 对于char来说,最多能存放的字符个数为255,和编码无关
varchar的特点
- varchar表示可变长字符串,长度是可变的;
- 插入的数据是多长,就按照多长来存储;
- varchar在存取方面与char相反,它存取慢,因为长度不固定,但正因如此,不占据多余的空间,是时间换空间的做法;
- 对于varchar来说,最多能存放的字符个数为65532
总之,结合性能角度(char更快)和节省磁盘空间角度(varchar更小),具体情况还需具体来设计数据库才是妥当的做法。
varchar(50)中50的涵义
最多存放50个字符,varchar(50)和(200)存储hello所占空间一样,但后者在排序时会消耗更多内存,因为order by col采用fixed_length计算col长度(memory引擎也一样)。在早期 MySQL 版本中, 50 代表字节数,现在代表字符数。
int(20)中20的涵义
是指显示字符的长度。20表示最大显示宽度为20,但仍占4字节存储,存储范围不变;
不影响内部存储,只是影响带 zerofill 定义的 int 时,前面补多少个 0,易于报表展示
mysql为什么这么设计
对大多数应用没有意义,只是规定一些工具用来显示字符的个数;int(1)和int(20)存储和计算均一样;
mysql中int(10)和char(10)以及varchar(10)的区别
-
int(10)的10表示显示的数据的长度,不是存储数据的大小;chart(10)和varchar(10)的10表示存储数据的大小,即表示存储多少个字符。
int(10) 10位的数据长度 9999999999,占32个字节,int型4位
char(10) 10位固定字符串,不足补空格 最多10个字符
varchar(10) 10位可变字符串,不足补空格 最多10个字符 -
char(10)表示存储定长的10个字符,不足10个就用空格补齐,占用更多的存储空间
-
varchar(10)表示存储10个变长的字符,存储多少个就是多少个,空格也按一个字符存储,这一点是和char(10)的空格不同的,char(10)的空格表示占位不算一个字符
FLOAT和DOUBLE的区别是什么?
- FLOAT类型数据可以存储至多8位十进制数,并在内存中占4字节。
- DOUBLE类型数据可以存储至多18位十进制数,并在内存中占8字节。
drop、delete与truncate的区别
三者都表示删除,但是三者有一些差别:
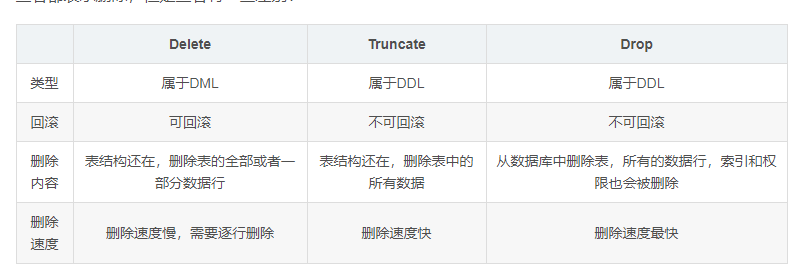
因此,在不再需要一张表的时候,用drop;在想删除部分数据行时候,用delete;在保留表而删除所有数据的时候用truncate。
UNION与UNION ALL的区别?
- 如果使用UNION ALL,不会合并重复的记录行
- 效率 UNION 高于 UNION ALL
SQL优化
–1.通过show status命令了解各种SQL的执行频率
–2.定位执行效率较低的SQL语句
–3.通过EXPLAIN分析较低SQL的执行计划
–4.通过show profile分析SQL
–5.通过trace分析优化器如何选择执行计划
–6.确定问题并采取相应的优化措施
如何定位及优化SQL语句的性能问题?创建的索引有没有被使用到?或者说怎么才可以知道这条语句运行很慢的原因?
对于低性能的SQL语句的定位,最重要也是最有效的方法就是使用执行计划,MySQL提供了explain命令来查看语句的执行计划。 我们知道,不管是哪种数据库,或者是哪种数据库引擎,在对一条SQL语句进行执行的过程中都会做很多相关的优化,对于查询语句,最重要的优化方式就是使用索引。 而执行计划,就是显示数据库引擎对于SQL语句的执行的详细情况,其中包含了是否使用索引,使用什么索引,使用的索引的相关信息等。
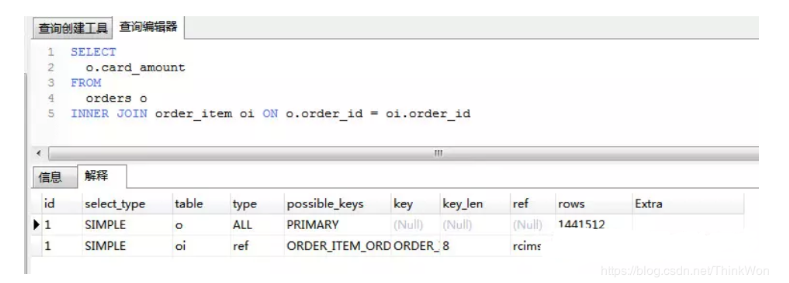
执行计划包含的信息 id 有一组数字组成。表示一个查询中各个子查询的执行顺序;
- id相同执行顺序由上至下。
- id不同,id值越大优先级越高,越先被执行。
- id为null时表示一个结果集,不需要使用它查询,常出现在包含union等查询语句中。
select_type 每个子查询的查询类型,一些常见的查询类型。
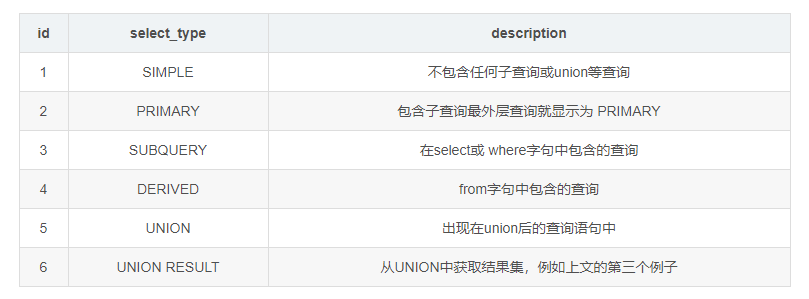
table 查询的数据表,当从衍生表中查数据时会显示 x 表示对应的执行计划id partitions 表分区、表创建的时候可以指定通过那个列进行表分区。 举个例子:
create table tmp (
id int unsigned not null AUTO_INCREMENT,
name varchar(255),
PRIMARY KEY (id)
) engine = innodb
partition by key (id) partitions 5;
type(非常重要,可以看到有没有走索引) 访问类型
- ALL 扫描全表数据
- index 遍历索引
- range 索引范围查找
- index_subquery 在子查询中使用 ref
- unique_subquery 在子查询中使用 eq_ref
- ref_or_null 对Null进行索引的优化的 ref
- fulltext 使用全文索引
- ref 使用非唯一索引查找数据
- eq_ref 在join查询中使用PRIMARY KEYorUNIQUE NOT NULL索引关联。
possible_keys 可能使用的索引,注意不一定会使用。查询涉及到的字段上若存在索引,则该索引将被列出来。当该列为 NULL时就要考虑当前的SQL是否需要优化了。
key 显示MySQL在查询中实际使用的索引,若没有使用索引,显示为NULL。
TIPS:查询中若使用了覆盖索引(覆盖索引:索引的数据覆盖了需要查询的所有数据),则该索引仅出现在key列表中
key_length 索引长度
ref 表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值
rows 返回估算的结果集数目,并不是一个准确的值。
extra 的信息非常丰富,常见的有:
- Using index 使用覆盖索引
- Using where 使用了用where子句来过滤结果集
- Using filesort 使用文件排序,使用非索引列进行排序时出现,非常消耗性能,尽量优化。
- Using temporary 使用了临时表 sql优化的目标可以参考阿里开发手册
【推荐】SQL性能优化的目标:至少要达到 range 级别,要求是ref级别,如果可以是consts最好。
说明:
1) consts 单表中最多只有一个匹配行(主键或者唯一索引),在优化阶段即可读取到数据。
2) ref 指的是使用普通的索引(normal index)。
3) range 对索引进行范围检索。
反例:explain表的结果,type=index,索引物理文件全扫描,速度非常慢,这个index级别比较range还低,与全表扫描是小巫见大巫。
SQL的生命周期?
SQL的生命周期?
- 应用服务器与数据库服务器建立一个连接
- 数据库进程拿到请求sql
- 解析并生成执行计划,执行
- 读取数据到内存并进行逻辑处理
- 通过步骤一的连接,发送结果到客户端
- 关掉连接,释放资源
大表数据查询,怎么优化
- 优化shema、sql语句+索引;
- 第二加缓存,memcached, redis;
- 主从复制,读写分离;
- 垂直拆分,根据你模块的耦合度,将一个大的系统分为多个小的系统,也就是分布式系统;
- 水平切分,针对数据量大的表,这一步最麻烦,最能考验技术水平,要选择一个合理的sharding key, 为了有好的查询效率,表结构也要改动,做一定的冗余,应用也要改,sql中尽量带sharding key,将数据定位到限定的表上去查,而不是扫描全部的表;
超大分页怎么处理?
超大的分页一般从两个方向上来解决.
- 数据库层面,这也是我们主要集中关注的(虽然收效没那么大),类似于
select * from table where age > 20 limit 1000000,10这种查询其实也是有可以优化的余地的. 这条语句需要load1000000数据然后基本上全部丢弃,只取10条当然比较慢. 当时我们可以修改为select * from table where id in (select id from table where age > 20 limit 1000000,10).这样虽然也load了一百万的数据,但是由于索引覆盖,要查询的所有字段都在索引中,所以速度会很快. 同时如果ID连续的好,我们还可以select * from table where id > 1000000 limit 10,效率也是不错的,优化的可能性有许多种,但是核心思想都一样,就是减少load的数据. - 从需求的角度减少这种请求…主要是不做类似的需求(直接跳转到几百万页之后的具体某一页.只允许逐页查看或者按照给定的路线走,这样可预测,可缓存)以及防止ID泄漏且连续被人恶意攻击.
解决超大分页,其实主要是靠缓存,可预测性的提前查到内容,缓存至redis等k-V数据库中,直接返回即可.
在阿里巴巴《Java开发手册》中,对超大分页的解决办法是类似于上面提到的第一种.
【推荐】利用延迟关联或者子查询优化超多分页场景。
说明:MySQL并不是跳过offset行,而是取offset+N行,然后返回放弃前offset行,返回N行,那当offset特别大的时候,效率就非常的低下,要么控制返回的总页数,要么对超过特定阈值的页数进行SQL改写。
正例:先快速定位需要获取的id段,然后再关联:
SELECT a.* FROM 表1 a, (select id from 表1 where 条件 LIMIT 100000,20 ) b where a.id=b.id
mysql 分页
LIMIT 子句可以被用于强制 SELECT 语句返回指定的记录数。LIMIT 接受一个或两个数字参数。参数必须是一个整数常量。如果给定两个参数,第一个参数指定第一个返回记录行的偏移量,第二个参数指定返回记录行的最大数目。初始记录行的偏移量是 0(而不是 1)
mysql> SELECT * FROM table LIMIT 5,10; // 检索记录行 6-15
为了检索从某一个偏移量到记录集的结束所有的记录行,可以指定第二个参数为 -1:
mysql> SELECT * FROM table LIMIT 95,-1; // 检索记录行 96-last.
如果只给定一个参数,它表示返回最大的记录行数目:
mysql> SELECT * FROM table LIMIT 5; //检索前 5 个记录行
换句话说,LIMIT n 等价于 LIMIT 0,n。
慢查询日志
用于记录执行时间超过某个临界值的SQL日志,用于快速定位慢查询,为我们的优化做参考。
开启慢查询日志
配置项:slow_query_log
可以使用show variables like ‘slov_query_log’查看是否开启,如果状态值为OFF,可以使用set GLOBAL slow_query_log = on来开启,它会在datadir下产生一个xxx-slow.log的文件。
设置临界时间
配置项:long_query_time
查看:show VARIABLES like 'long_query_time',单位秒
设置:set long_query_time=0.5
实操时应该从长时间设置到短的时间,即将最慢的SQL优化掉
查看日志,一旦SQL超过了我们设置的临界时间就会被记录到xxx-slow.log中
关心过业务系统里面的sql耗时吗?统计过慢查询吗?对慢查询都怎么优化过?
在业务系统中,除了使用主键进行的查询,其他的我都会在测试库上测试其耗时,慢查询的统计主要由运维在做,会定期将业务中的慢查询反馈给我们。
慢查询的优化首先要搞明白慢的原因是什么? 是查询条件没有命中索引?是load了不需要的数据列?还是数据量太大?
所以优化也是针对这三个方向来的,
- 首先分析语句,看看是否load了额外的数据,可能是查询了多余的行并且抛弃掉了,可能是加载了许多结果中并不需要的列,对语句进行分析以及重写。
- 分析语句的执行计划,然后获得其使用索引的情况,之后修改语句或者修改索引,使得语句可以尽可能的命中索引。
- 如果对语句的优化已经无法进行,可以考虑表中的数据量是否太大,如果是的话可以进行横向或者纵向的分表。
为什么要尽量设定一个主键?
主键是数据库确保数据行在整张表唯一性的保障,即使业务上本张表没有主键,也建议添加一个自增长的ID列作为主键。设定了主键之后,在后续的删改查的时候可能更加快速以及确保操作数据范围安全。
主键使用自增ID还是UUID?
推荐使用自增ID,不要使用UUID。
因为在InnoDB存储引擎中,主键索引是作为聚簇索引存在的,也就是说,主键索引的B+树叶子节点上存储了主键索引以及全部的数据(按照顺序),如果主键索引是自增ID,那么只需要不断向后排列即可,如果是UUID,由于到来的ID与原来的大小不确定,会造成非常多的数据插入,数据移动,然后导致产生很多的内存碎片,进而造成插入性能的下降。
总之,在数据量大一些的情况下,用自增主键性能会好一些。
关于主键是聚簇索引,如果没有主键,InnoDB会选择一个唯一键来作为聚簇索引,如果没有唯一键,会生成一个隐式的主键。
字段为什么要求定义为not null?
null值会占用更多的字节,且会在程序中造成很多与预期不符的情况。
如果要存储用户的密码散列,应该使用什么字段进行存储?
密码散列,盐,用户身份证号等固定长度的字符串应该使用char而不是varchar来存储,这样可以节省空间且提高检索效率。
优化查询过程中的数据访问
- 访问数据太多导致查询性能下降
- 确定应用程序是否在检索大量超过需要的数据,可能是太多行或列
- 确认MySQL服务器是否在分析大量不必要的数据行
- 避免犯如下SQL语句错误
- 查询不需要的数据。解决办法:使用limit解决
- 多表关联返回全部列。解决办法:指定列名
- 总是返回全部列。解决办法:避免使用SELECT *
- 重复查询相同的数据。解决办法:可以缓存数据,下次直接读取缓存
- 是否在扫描额外的记录。解决办法:
- 使用explain进行分析,如果发现查询需要扫描大量的数据,但只返回少数的行,可以通过如下技巧去优化:
- 使用索引覆盖扫描,把所有的列都放到索引中,这样存储引擎不需要回表获取对应行就可以返回结果。
- 改变数据库和表的结构,修改数据表范式
- 重写SQL语句,让优化器可以以更优的方式执行查询。
优化长难的查询语句
- 一个复杂查询还是多个简单查询
- MySQL内部每秒能扫描内存中上百万行数据,相比之下,响应数据给客户端就要慢得多
- 使用尽可能小的查询是好的,但是有时将一个大的查询分解为多个小的查询是很有必要的。
- 切分查询
- 将一个大的查询分为多个小的相同的查询
- 一次性删除1000万的数据要比一次删除1万,暂停一会的方案更加损耗服务器开销。
- 分解关联查询,让缓存的效率更高。
- 执行单个查询可以减少锁的竞争。
- 在应用层做关联更容易对数据库进行拆分。
- 查询效率会有大幅提升。
- 较少冗余记录的查询。
优化特定类型的查询语句
- count(*)会忽略所有的列,直接统计所有列数,不要使用count(列名)
- MyISAM中,没有任何where条件的count(*)非常快。
- 当有where条件时,MyISAM的count统计不一定比其它引擎快。
- 可以使用explain查询近似值,用近似值替代count(*)
- 增加汇总表
- 使用缓存
优化关联查询
- 确定ON或者USING子句中是否有索引。
- 确保GROUP BY和ORDER BY只有一个表中的列,这样MySQL才有可能使用索引。
优化子查询
- 用关联查询替代
- 优化GROUP BY和DISTINCT
- 这两种查询据可以使用索引来优化,是最有效的优化方法
- 关联查询中,使用标识列分组的效率更高
- 如果不需要ORDER BY,进行GROUP BY时加ORDER BY NULL,MySQL不会再进行文件排序。
- WITH ROLLUP超级聚合,可以挪到应用程序处理
优化LIMIT分页
- LIMIT偏移量大的时候,查询效率较低
- 可以记录上次查询的最大ID,下次查询时直接根据该ID来查询
优化UNION查询
- UNION ALL的效率高于UNION
优化WHERE子句
解题方法
对于此类考题,先说明如何定位低效SQL语句,然后根据SQL语句可能低效的原因做排查,先从索引着手,如果索引没有问题,考虑以上几个方面,数据访问的问题,长难查询句的问题还是一些特定类型优化的问题,逐一回答。
SQL语句优化的一些方法?
- 1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
- 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num is null
-- 可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:
select id from t where num=
- 3.应尽量避免在 where 子句中使用!=或<>操作符,否则引擎将放弃使用索引而进行全表扫描。
- 4.应尽量避免在 where 子句中使用or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num=10 or num=20
-- 可以这样查询:
select id from t where num=10 union all select id from t where num=20
123
- 5.in 和 not in 也要慎用,否则会导致全表扫描,如:
select id from t where num in(1,2,3)
-- 对于连续的数值,能用 between 就不要用 in 了:
select id from t where num between 1 and 3
123
- 6.下面的查询也将导致全表扫描:select id from t where name like ‘%李%’若要提高效率,可以考虑全文检索。
- 7.如果在 where 子句中使用参数,也会导致全表扫描。因为SQL只有在运行时才会解析局部变量,但优化程序不能将访问计划的选择推迟到运行时;它必须在编译时进行选择。然 而,如果在编译时建立访问计划,变量的值还是未知的,因而无法作为索引选择的输入项。如下面语句将进行全表扫描:
select id from t where num=@num
-- 可以改为强制查询使用索引:
select id from t with(index(索引名)) where num=@num
123
- 8.应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where num/2=100
-- 应改为:
select id from t where num=100*2
- 9.应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where substring(name,1,3)=’abc’
-- name以abc开头的id应改为:
select id from t where name like ‘abc%’
123
- 10.不要在 where 子句中的“=”左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引。
https://www.cnblogs.com/wangzhengyu/p/10412499.html
补充:
distinct是用来去重的,group by是用来聚合统计的
单纯的去重操作使用distinct,速度是快于groub by的
导致SQL执行慢的原因:
- 硬件问题。如网络速度慢,内存不足,I/O吞吐量小,磁盘空间满了等。
- 没有索引或者索引失效。(一般在互联网公司,DBA会在半夜把表锁了,重新建立一遍索引,因为当你删除某个数据的时候,索引的树结构就不完整了。所以互联网公司的数据做的是假删除.一是为了做数据分析,二是为了不破坏索引 )
- 数据过多(分库分表)
- 服务器调优及各个参数设置(调整my.cnf)
数据库优化
为什么要优化
- 系统的吞吐量瓶颈往往出现在数据库的访问速度上
- 随着应用程序的运行,数据库的中的数据会越来越多,处理时间会相应变慢
- 数据是存放在磁盘上的,读写速度无法和内存相比
优化原则:减少系统瓶颈,减少资源占用,增加系统的反应速度。
数据库结构优化
一个好的数据库设计方案对于数据库的性能往往会起到事半功倍的效果。
需要考虑数据冗余、查询和更新的速度、字段的数据类型是否合理等多方面的内容。
将字段很多的表分解成多个表
对于字段较多的表,如果有些字段的使用频率很低,可以将这些字段分离出来形成新表。
因为当一个表的数据量很大时,会由于使用频率低的字段的存在而变慢。
增加中间表
对于需要经常联合查询的表,可以建立中间表以提高查询效率。
通过建立中间表,将需要通过联合查询的数据插入到中间表中,然后将原来的联合查询改为对中间表的查询。
增加冗余字段
设计数据表时应尽量遵循范式理论的规约,尽可能的减少冗余字段,让数据库设计看起来精致、优雅。但是,合理的加入冗余字段可以提高查询速度。
表的规范化程度越高,表和表之间的关系越多,需要连接查询的情况也就越多,性能也就越差。
注意:
冗余字段的值在一个表中修改了,就要想办法在其他表中更新,否则就会导致数据不一致的问题。
MySQL数据库cpu飙升到500%的话他怎么处理?
当 cpu 飙升到 500%时,先用操作系统命令 top 命令观察是不是 mysqld 占用导致的,如果不是,找出占用高的进程,并进行相关处理。
如果是 mysqld 造成的, show processlist,看看里面跑的 session 情况,是不是有消耗资源的 sql 在运行。找出消耗高的 sql,看看执行计划是否准确, index 是否缺失,或者实在是数据量太大造成。
一般来说,肯定要 kill 掉这些线程(同时观察 cpu 使用率是否下降),等进行相应的调整(比如说加索引、改 sql、改内存参数)之后,再重新跑这些 SQL。
也有可能是每个 sql 消耗资源并不多,但是突然之间,有大量的 session 连进来导致 cpu 飙升,这种情况就需要跟应用一起来分析为何连接数会激增,再做出相应的调整,比如说限制连接数等
大表怎么优化?某个表有近千万数据,CRUD比较慢,如何优化?分库分表了是怎么做的?分表分库了有什么问题?有用到中间件么?他们的原理知道么?
当MySQL单表记录数过大时,数据库的CRUD性能会明显下降,一些常见的优化措施如下:
- 限定数据的范围: 务必禁止不带任何限制数据范围条件的查询语句。比如:我们当用户在查询订单历史的时候,我们可以控制在一个月的范围内。;
- 读/写分离: 经典的数据库拆分方案,主库负责写,从库负责读;
- 缓存: 使用MySQL的缓存,另外对重量级、更新少的数据可以考虑使用应用级别的缓存;
还有就是通过分库分表的方式进行优化,主要有垂直分表和水平分表
垂直分区:
根据数据库里面数据表的相关性进行拆分。 例如,用户表中既有用户的登录信息又有用户的基本信息,可以将用户表拆分成两个单独的表,甚至放到单独的库做分库。
简单来说垂直拆分是指数据表列的拆分,把一张列比较多的表拆分为多张表。 如下图所示,这样来说大家应该就更容易理解了。
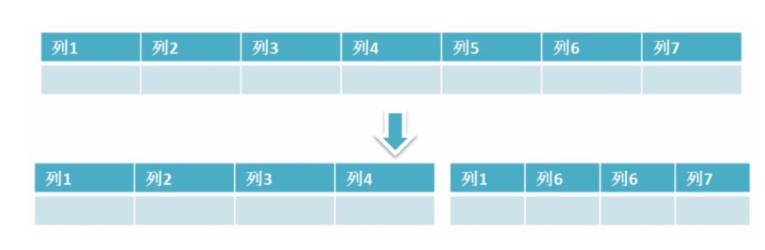
垂直拆分的优点: 可以使得行数据变小,在查询时减少读取的Block数,减少I/O次数。此外,垂直分区可以简化表的结构,易于维护。
垂直拆分的缺点: 主键会出现冗余,需要管理冗余列,并会引起Join操作,可以通过在应用层进行Join来解决。此外,垂直分区会让事务变得更加复杂;
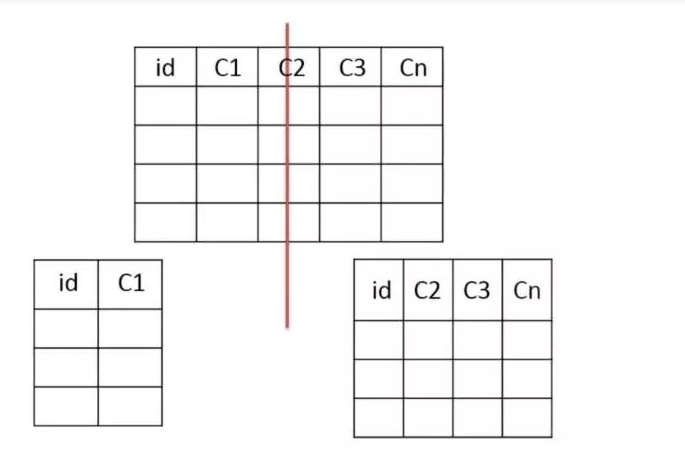
垂直分表
把主键和一些列放在一个表,然后把主键和另外的列放在另一个表中
-
适用场景
- 1、如果一个表中某些列常用,另外一些列不常用
- 2、可以使数据行变小,一个数据页能存储更多数据,查询时减少I/O次数
缺点
- 有些分表的策略基于应用层的逻辑算法,一旦逻辑算法改变,整个分表逻辑都会改变,扩展性较差
- 对于应用层来说,逻辑算法增加开发成本
- 管理冗余列,查询所有数据需要join操作
-
水平分区:
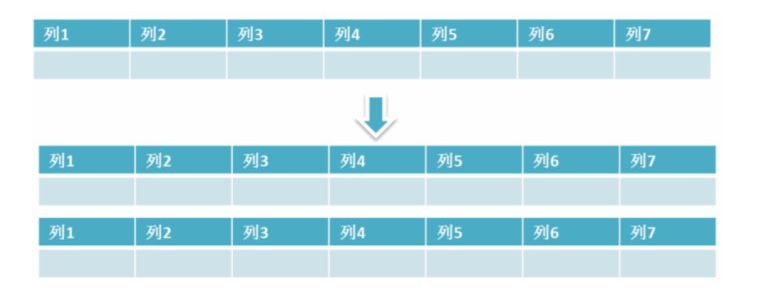
保持数据表结构不变,通过某种策略存储数据分片。这样每一片数据分散到不同的表或者库中,达到了分布式的目的。 水平拆分可以支撑非常大的数据量。
水平拆分是指数据表行的拆分,表的行数超过200万行时,就会变慢,这时可以把一张的表的数据拆成多张表来存放。举个例子:我们可以将用户信息表拆分成多个用户信息表,这样就可以避免单一表数据量过大对性能造成影响。
水平拆分可以支持非常大的数据量。需要注意的一点是:分表仅仅是解决了单一表数据过大的问题,但由于表的数据还是在同一台机器上,其实对于提升MySQL并发能力没有什么意义,所以 水平拆分最好分库 。
水平拆分能够 支持非常大的数据量存储,应用端改造也少,但 分片事务难以解决 ,跨界点Join性能较差,逻辑复杂。
《Java工程师修炼之道》的作者推荐 尽量不要对数据进行分片,因为拆分会带来逻辑、部署、运维的各种复杂度 ,一般的数据表在优化得当的情况下支撑千万以下的数据量是没有太大问题的。如果实在要分片,尽量选择客户端分片架构,这样可以减少一次和中间件的网络I/O。
水平分表:
表很大,分割后可以降低在查询时需要读的数据和索引的页数,同时也降低了索引的层数,提高查询次数
适用场景
- 1、表中的数据本身就有独立性,例如表中分表记录各个地区的数据或者不同时期的数据,特别是有些数据常用,有些不常用。
- 2、需要把数据存放在多个介质上。
水平切分的缺点
- 1、给应用增加复杂度,通常查询时需要多个表名,查询所有数据都需UNION操作
- 2、在许多数据库应用中,这种复杂度会超过它带来的优点,查询时会增加读一个索引层的磁盘次数
下面补充一下数据库分片的两种常见方案:
- 客户端代理: 分片逻辑在应用端,封装在jar包中,通过修改或者封装JDBC层来实现。 当当网的 Sharding-JDBC 、阿里的TDDL是两种比较常用的实现。
- 中间件代理: 在应用和数据中间加了一个代理层。分片逻辑统一维护在中间件服务中。 我们现在谈的 Mycat 、360的Atlas、网易的DDB等等都是这种架构的实现。
分库分表后面临的问题
-
事务支持 分库分表后,就成了分布式事务了。如果依赖数据库本身的分布式事务管理功能去执行事务,将付出高昂的性能代价; 如果由应用程序去协助控制,形成程序逻辑上的事务,又会造成编程方面的负担。
-
跨库join
只要是进行切分,跨节点Join的问题是不可避免的。但是良好的设计和切分却可以减少此类情况的发生。解决这一问题的普遍做法是分两次查询实现。在第一次查询的结果集中找出关联数据的id,根据这些id发起第二次请求得到关联数据。 分库分表方案产品
-
跨节点的count,order by,group by以及聚合函数问题 这些是一类问题,因为它们都需要基于全部数据集合进行计算。多数的代理都不会自动处理合并工作。解决方案:与解决跨节点join问题的类似,分别在各个节点上得到结果后在应用程序端进行合并。和join不同的是每个结点的查询可以并行执行,因此很多时候它的速度要比单一大表快很多。但如果结果集很大,对应用程序内存的消耗是一个问题。
-
数据迁移,容量规划,扩容等问题 来自淘宝综合业务平台团队,它利用对2的倍数取余具有向前兼容的特性(如对4取余得1的数对2取余也是1)来分配数据,避免了行级别的数据迁移,但是依然需要进行表级别的迁移,同时对扩容规模和分表数量都有限制。总得来说,这些方案都不是十分的理想,多多少少都存在一些缺点,这也从一个侧面反映出了Sharding扩容的难度。
-
ID问题
-
一旦数据库被切分到多个物理结点上,我们将不能再依赖数据库自身的主键生成机制。一方面,某个分区数据库自生成的ID无法保证在全局上是唯一的;另一方面,应用程序在插入数据之前需要先获得ID,以便进行SQL路由. 一些常见的主键生成策略
UUID 使用UUID作主键是最简单的方案,但是缺点也是非常明显的。由于UUID非常的长,除占用大量存储空间外,最主要的问题是在索引上,在建立索引和基于索引进行查询时都存在性能问题。 Twitter的分布式自增ID算法Snowflake 在分布式系统中,需要生成全局UID的场合还是比较多的,twitter的snowflake解决了这种需求,实现也还是很简单的,除去配置信息,核心代码就是毫秒级时间41位 机器ID 10位 毫秒内序列12位。
-
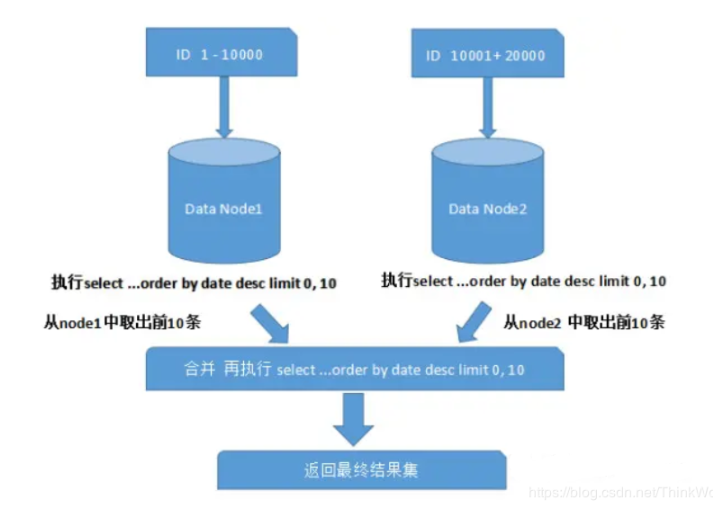
跨分片的排序分页
般来讲,分页时需要按照指定字段进行排序。当排序字段就是分片字段的时候,我们通过分片规则可以比较容易定位到指定的分片,而当排序字段非分片字段的时候,情况就会变得比较复杂了。为了最终结果的准确性,我们需要在不同的分片节点中将数据进行排序并返回,并将不同分片返回的结果集进行汇总和再次排序,最后再返回给用户。如下图所示:
MySQL的复制原理以及流程
主从复制:将主数据库中的DDL和DML操作通过二进制日志(BINLOG)传输到从数据库上,然后将这些日志重新执行(重做);从而使得从数据库的数据与主数据库保持一致。
主从复制的作用
- 主数据库出现问题,可以切换到从数据库。
- 可以进行数据库层面的读写分离。
- 可以在从数据库上进行日常备份。
MySQL主从复制解决的问题
- 数据分布:随意开始或停止复制,并在不同地理位置分布数据备份
- 负载均衡:降低单个服务器的压力
- 高可用和故障切换:帮助应用程序避免单点失败
- 升级测试:可以用更高版本的MySQL作为从库
MySQL主从复制工作原理
- 在主库上把数据更高记录到二进制日志
- 从库将主库的日志复制到自己的中继日志
- 从库读取中继日志的事件,将其重放到从库数据中
基本原理流程,3个线程以及之间的关联
主:binlog线程——记录下所有改变了数据库数据的语句,放进master上的binlog中;
从:io线程——在使用start slave 之后,负责从master上拉取 binlog 内容,放进自己的relay log中;
从:sql执行线程——执行relay log中的语句;
复制过程
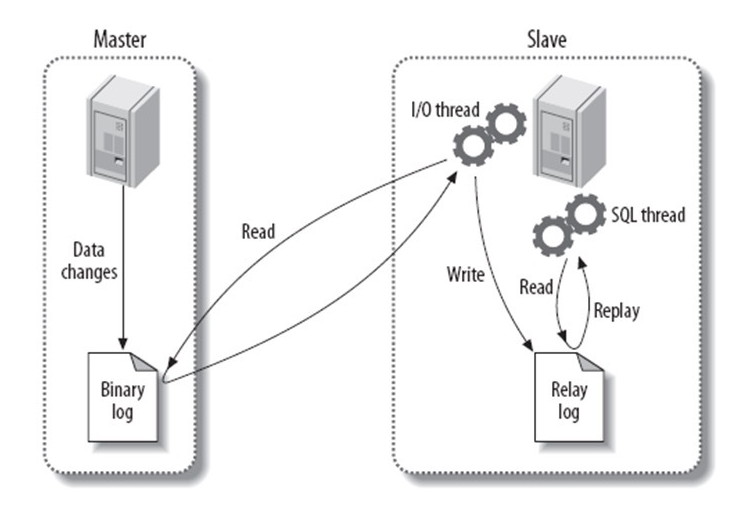
Binary log:主数据库的二进制日志
Relay log:从服务器的中继日志
第一步:master在每个事务更新数据完成之前,将该操作记录串行地写入到binlog文件中。
第二步:salve开启一个I/O Thread,该线程在master打开一个普通连接,主要工作是binlog dump process。如果读取的进度已经跟上了master,就进入睡眠状态并等待master产生新的事件。I/O线程最终的目的是将这些事件写入到中继日志中。
第三步:SQL Thread会读取中继日志,并顺序执行该日志中的SQL事件,从而与主数据库中的数据保持一致。
读写分离有哪些解决方案?
读写分离是依赖于主从复制,而主从复制又是为读写分离服务的。因为主从复制要求slave不能写只能读(如果对slave执行写操作,那么show slave status将会呈现Slave_SQL_Running=NO,此时你需要按照前面提到的手动同步一下slave)。
方案一
使用mysql-proxy代理
优点:直接实现读写分离和负载均衡,不用修改代码,master和slave用一样的帐号,mysql官方不建议实际生产中使用
缺点:降低性能, 不支持事务
方案二
使用AbstractRoutingDataSource+aop+annotation在dao层决定数据源。
如果采用了mybatis, 可以将读写分离放在ORM层,比如mybatis可以通过mybatis plugin拦截sql语句,所有的insert/update/delete都访问master库,所有的select 都访问salve库,这样对于dao层都是透明。 plugin实现时可以通过注解或者分析语句是读写方法来选定主从库。不过这样依然有一个问题, 也就是不支持事务, 所以我们还需要重写一下DataSourceTransactionManager, 将read-only的事务扔进读库, 其余的有读有写的扔进写库。
方案三
使用AbstractRoutingDataSource+aop+annotation在service层决定数据源,可以支持事务.
缺点:类内部方法通过this.xx()方式相互调用时,aop不会进行拦截,需进行特殊处理。
备份计划,mysqldump以及xtranbackup的实现原理
(1)备份计划
视库的大小来定,一般来说 100G 内的库,可以考虑使用 mysqldump 来做,因为 mysqldump更加轻巧灵活,备份时间选在业务低峰期,可以每天进行都进行全量备份(mysqldump 备份出来的文件比较小,压缩之后更小)。
100G 以上的库,可以考虑用 xtranbackup 来做,备份速度明显要比 mysqldump 要快。一般是选择一周一个全备,其余每天进行增量备份,备份时间为业务低峰期。
(2)备份恢复时间
物理备份恢复快,逻辑备份恢复慢
这里跟机器,尤其是硬盘的速率有关系,以下列举几个仅供参考
20G的2分钟(mysqldump)
80G的30分钟(mysqldump)
111G的30分钟(mysqldump)
288G的3小时(xtra)
3T的4小时(xtra)
逻辑导入时间一般是备份时间的5倍以上
(3)备份恢复失败如何处理
首先在恢复之前就应该做足准备工作,避免恢复的时候出错。比如说备份之后的有效性检查、权限检查、空间检查等。如果万一报错,再根据报错的提示来进行相应的调整。
(4)mysqldump和xtrabackup实现原理
mysqldump
**mysqldump 属于逻辑备份。**加入–single-transaction 选项可以进行一致性备份。后台进程会先设置 session 的事务隔离级别为 RR(SET SESSION TRANSACTION ISOLATION LEVELREPEATABLE READ),之后显式开启一个事务(START TRANSACTION /*!40100 WITH CONSISTENTSNAPSHOT */),这样就保证了该事务里读到的数据都是事务事务时候的快照。之后再把表的数据读取出来。如果加上–master-data=1 的话,在刚开始的时候还会加一个数据库的读锁(FLUSH TABLES WITH READ LOCK),等开启事务后,再记录下数据库此时 binlog 的位置(showmaster status),马上解锁,再读取表的数据。等所有的数据都已经导完,就可以结束事务
Xtrabackup:
xtrabackup 属于物理备份,直接拷贝表空间文件,同时不断扫描产生的 redo 日志并保存下来。最后完成 innodb 的备份后,会做一个 flush engine logs 的操作(老版本在有 bug,在5.6 上不做此操作会丢数据),确保所有的 redo log 都已经落盘(涉及到事务的两阶段提交
概念,因为 xtrabackup 并不拷贝 binlog,所以必须保证所有的 redo log 都落盘,否则可能会丢最后一组提交事务的数据)。这个时间点就是 innodb 完成备份的时间点,数据文件虽然不是一致性的,但是有这段时间的 redo 就可以让数据文件达到一致性(恢复的时候做的事
情)。然后还需要 flush tables with read lock,把 myisam 等其他引擎的表给备份出来,备份完后解锁。这样就做到了完美的热备。
数据表损坏的修复方式有哪些?
使用 myisamchk 来修复,具体步骤:
- 1)修复前将mysql服务停止。
- 2)打开命令行方式,然后进入到mysql的/bin目录。
- 3)执行myisamchk –recover 数据库所在路径/*.MYI
使用repair table 或者 OPTIMIZE table命令来修复,REPAIR TABLE table_name 修复表 OPTIMIZE TABLE table_name 优化表 REPAIR TABLE 用于修复被破坏的表。 OPTIMIZE TABLE 用于回收闲置的数据库空间,当表上的数据行被删除时,所占据的磁盘空间并没有立即被回收,使用了OPTIMIZE TABLE命令后这些空间将被回收,并且对磁盘上的数据行进行重排(注意:是磁盘上,而非数据库)
分页
自定义分页组件应该包含那些属性
https://www.cnblogs.com/itzfz/p/10007502.html
分页的实现可分为两大类相信你也懂得这个,
一、数据在Java代码中进行分页;
二、在数据库中直接取得当前页数据。
通常面试官都希望听到后者,因为那才是高效的方法。你如果想让面试官觉得你的能力高的话你就先否定他的问题,你可以回答说:“Java中根本不需要做分页的实现代码只管拿数据库中的当前页数据即可,数据分页功能应该交由SQL处理,在分页实现中Java最多只实现总页数的计算,除此以外几乎不用管。”如果你这么答的话面试官通常会问你总页数的算法,至于这个你可以网上找个高效点的方法,我现在知道最高效的就是:(数据总行数+每页数据行数-1)/每页数据行数。
sql分页部分: limit (pageNo-1)*pageSize , pageSize
查询总记录数:SELECT COUNT(*) FROM 表名
分页重要数据
//每页多少条数据
private int pageSize;
//第几页
private int pageNo;
//总共有多少条数据(从数据库查出来的)
private int totalRecords;
//总页数
private int totalPage;
totalPage=(totalRecords + pageSize - 1) / pageSize;
其中 pageSize - 1 就是totalRecords / pageSize 的最大的余数
首页:1
尾页:totalPage
上一页
public int getPreviousPageNo() {
if (pageNo <= 1) {
return 1;
}
return pageNo - 1;
}
下一页
public int getNextPageNo() {
if (pageNo >= totalPage()) {
return totalPage();
}
return pageNo + 1;
}
mysql主键自增为什么比随机和自定义快?
1、如果表使用自增主键,那么每次插入新的记录,记录就会顺序添加到当前索引节点的后续位置,当一页写满,就会自动开辟一个新的页
2、如果使用非自增主键(如果身份证号或学号等),由于每次插入主键的值近似于随机,因此每次新纪录都要被插到现有索引页得中间某个位置,此时MySQL不得不为了将新记录插到合适位置而移动数据,甚至目标页面可能已经被回写到磁盘上而从缓存中清掉,此时又要从磁盘上读回来,这增加了很多开销,同时频繁的移动、分页操作造成了大量的碎片,得到了不够紧凑的索引结构,后续不得不通过OPTIMIZE TABLE来重建表并优化填充页面。
聚集索引就是主键索引
非聚集索引就是 联合索引
主键索引 节点存放数据
非主键索引存在 主键索引的id 然后再查一遍主键索引
我们都知道表的主键一般都要使用自增 id,不建议使用业务 id ,是因为使用自增 id 可以避免页分裂。这个其实可以相当于一个结论,你都可以直接记住这个结论就可以了。
但是如果你要弄明白什么是页分裂,或者什么情况下会页分裂,这个时候你就需要对 mysql 的底层数据结构要有一定的理解了。
我这里也稍微解释一下页分裂,mysql (注意本文讲的 mysql 默认为InnoDB 引擎)底层数据结构是 B+ 树,所谓的索引其实就是一颗 B+ 树,一个表有多少个索引就会有多少颗 B+ 树,mysql 中的数据都是按顺序保存在 B+ 树上的(所以说索引本身是有序的)。
然后 mysql 在底层又是以数据页为单位来存储数据的,一个数据页大小默认为 16k,当然你也可以自定义大小,也就是说如果一个数据页存满了,mysql 就会去申请一个新的数据页来存储数据。
如果主键为自增 id 的话,mysql 在写满一个数据页的时候,直接申请另一个新数据页接着写就可以了。
如果主键是非自增 id,为了确保索引有序,mysql 就需要将每次插入的数据都放到合适的位置上。
当往一个快满或已满的数据页中插入数据时,新插入的数据会将数据页写满,mysql 就需要申请新的数据页,并且把上个数据页中的部分数据挪到新的数据页上。
这就造成了页分裂,这个大量移动数据的过程是会严重影响插入效率的。
其实对主键 id 还有一个小小的要求,在满足业务需求的情况下,尽量使用占空间更小的主键 id,因为普通索引的叶子节点上保存的是主键 id 的值,如果主键 id 占空间较大的话,那将会成倍增加 mysql 空间占用大小。
那为什么推荐使用整型自增主键而不是选择UUID?
- UUID是字符串,比整型消耗更多的存储空间;
- 在B+树中进行查找时需要跟经过的节点值比较大小,整型数据的比较运算比字符串更快速;
- 自增的整型索引在磁盘中会连续存储,在读取一页数据时也是连续;UUID是随机产生的,读取的上下两行数据存储是分散的,不适合执行where id > 5 && id < 20的条件查询语句。
- 在插入或删除数据时,整型自增主键会在叶子结点的末尾建立新的叶子节点,不会破坏左侧子树的结构;UUID主键很容易出现这样的情况,B+树为了维持自身的特性,有可能会进行结构的重构,消耗更多的时间。
- 为什么非主键索引结构叶子节点存储的是主键值?
保证数据一致性和节省存储空间,可以这么理解:商城系统订单表会存储一个用户ID作为关联外键,而不推荐存储完整的用户信息,因为当我们用户表中的信息(真实名称、手机号、收货地址···)修改后,不需要再次维护订单表的用户数据,同时也节省了存储空间。
MVCC
https://www.jianshu.com/p/8845ddca3b23
英文全称为Multi-Version Concurrency Control,翻译为中文即 多版本并发控制。他无非就是乐观锁的一种实现方式。在Java编程中,如果把乐观锁看成一个接口,MVCC便是这个接口的一个实现类而已。
特点
1.MVCC其实广泛应用于数据库技术,像Oracle,PostgreSQL等也引入了该技术,即适用范围广
2.MVCC并没有简单的使用数据库的行锁,而是使用了行级锁,row_level_lock,而非InnoDB中的innodb_row_lock.
基本原理
MVCC的实现,通过保存数据在某个时间点的快照来实现的。这意味着一个事务无论运行多长时间,在同一个事务里能够看到数据一致的视图。根据事务开始的时间不同,同时也意味着在同一个时刻不同事务看到的相同表里的数据可能是不同的。
基本特征
- 每行数据都存在一个版本,每次数据更新时都更新该版本。
- 修改时Copy出当前版本随意修改,各个事务之间无干扰。
- 保存时比较版本号,如果成功(commit),则覆盖原记录;失败则放弃copy(rollback)
GAP锁
A place in an InnoDB index data structure where new values could be inserted.
说白了gap就是索引树中插入新记录的空隙。相应的gap lock就是加在gap上的锁,还有一个next-key锁,是记录+记录前面的gap的组合的锁。
简单讲就是防止幻读。通过锁阻止特定条件的新记录的插入,因为插入时也要获取gap锁(Insert Intention Locks)。
为什么MySQL使用B+而不是使用B树、二叉树、AVL树呢?(来龙去脉的去理解)
(1)先从二叉树开始说起:
- 首先你得知道二叉树是什么吧:看下面的图一你就该很熟悉了吧
- 然后你得知道二叉树查询的时间复杂度是O(log2(n)),这样感觉其实二叉树的查询效率挺高的,但是他会出现另一种现象,就是下面的图二:
- 这样就导致了二叉树的查询效率不问题,如果运气好的话查询效率就很高,如果运气不好的话,就会出现图二的情况,因此在二叉树的基础上又进行的改进,演变出来了平衡二叉树(AVL树)
图一:

图二:
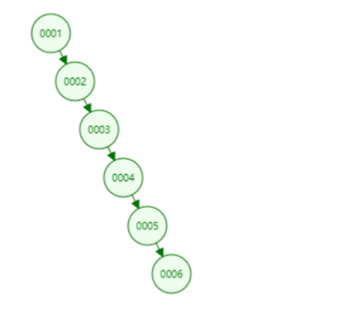
(2)然后到了平衡二叉树(AVL树):
- 首先你得知道平衡二叉树的定义吧:在满足二叉树的基础上,任意两个节点的两个子树的高度差不能超过1:就好比下面的这个图的一个效率很差的二叉树,比如5节点的左子树的高度是0,右字树的高度是2,,所以很明显不满足平衡二叉树的概念
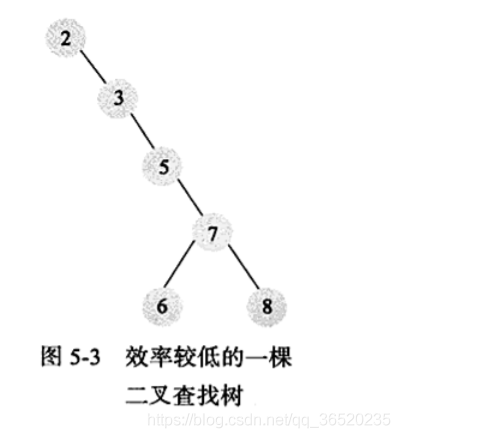
AVL树主要是为了解决上面的图出现的情况,所以现在要把上图的二叉树转插入一个“9”节点然后换为一个平衡二叉树的情况就是下面的:
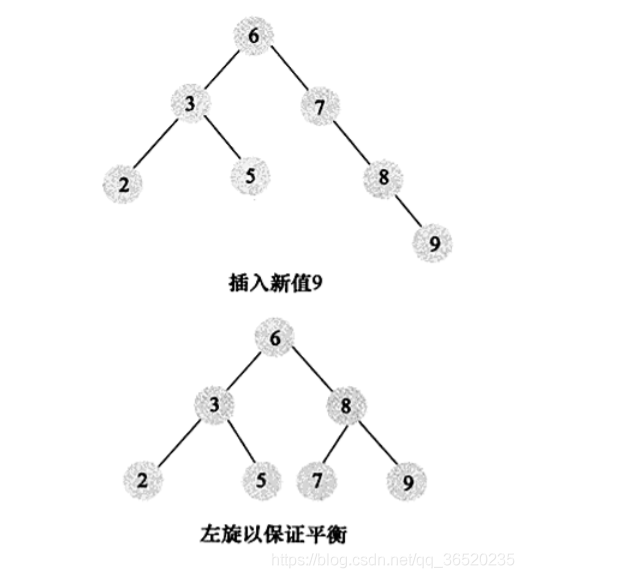
-
可以看出平衡二叉树的缺点就是:
(1)维护平衡过程的成本代价很高,因为每次删除一个节点或者增加一个节点的话,需要一次或者多次的左旋,右旋等去维护“平衡”状态,
(2)然后是查询的效率不稳定,还是会有看运气的成分在里面,
(3)然后是如果节点很多的话,那么这个AVL树的高度还是会很高的,那么查询效率还是会很低,
-
还有就是节点存储的数据内容太少。没有很好利用操作系统和磁盘数据交换特性,也没有利用好磁盘IO的预读能力。因为操作系统和磁盘之间一次数据交换是已页为单位的,一页 = 4K,即每次IO操作系统会将4K数据加载进内存。但是,在二叉树每个节点的结构只保存一个关键字,一个数据区,两个子节点的引用,并不能够填满4K的内容。幸幸苦苦做了一次的IO操作,却只加载了一个关键字,在树的高度很高,恰好又搜索的关键字位于叶子节点或者支节点的时候,取一个关键字要做很多次的IO。因此平衡二叉树也是不太符合MySQL的查询结构的。
(3)然后到了使用B Tree(多路平衡查找树)
- 首先你也得知道B Tree的基本概念:所有的叶子节点的高度都是一样,这个保证了每次查询数据的时候都是稳定的查询效率,不会因为运气的影响
- 然后B Tree中其实每个非叶子节点内的小节点内其实都是一个二元组[key, data],key其实就是下图的那个25这种的,然后这个data其实对应的就是数据库中id等于25这条完整的数据记录的内存地址(因为在Myisam中他是数据和索引数据是分开的)
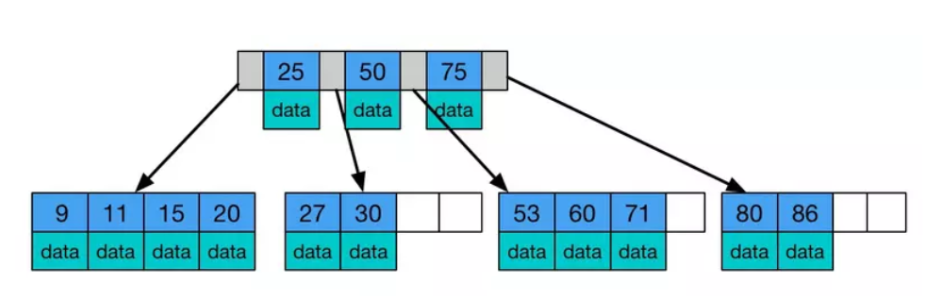
B树的特点:
- 首先B Tree的每一个节点上其实是有data的,这个data其实就是数据库中id这条完整的数据记录的内存地址
- 然后是B Tree查询的效率不够稳定,他有可能在第一个节点中就查到了数据,并且返回
- 他的键值其实都是分布在整棵树上的节点上的任何一个节点
(4)然后到了使用B+ Tree(多路平衡查找树)
- 首先你要知道什么B+ Tree,其实他是专门为磁盘或者其他的直接存取辅助设备设计的一种平衡查找树,在B树中,所有的节点都是按照键值的大小顺序存放在同一层的叶子节点上,由各叶子节点的指针连接。
- 下图的一颗B树,是一个高度为2,每一页可以放4条记录,扇出是5。
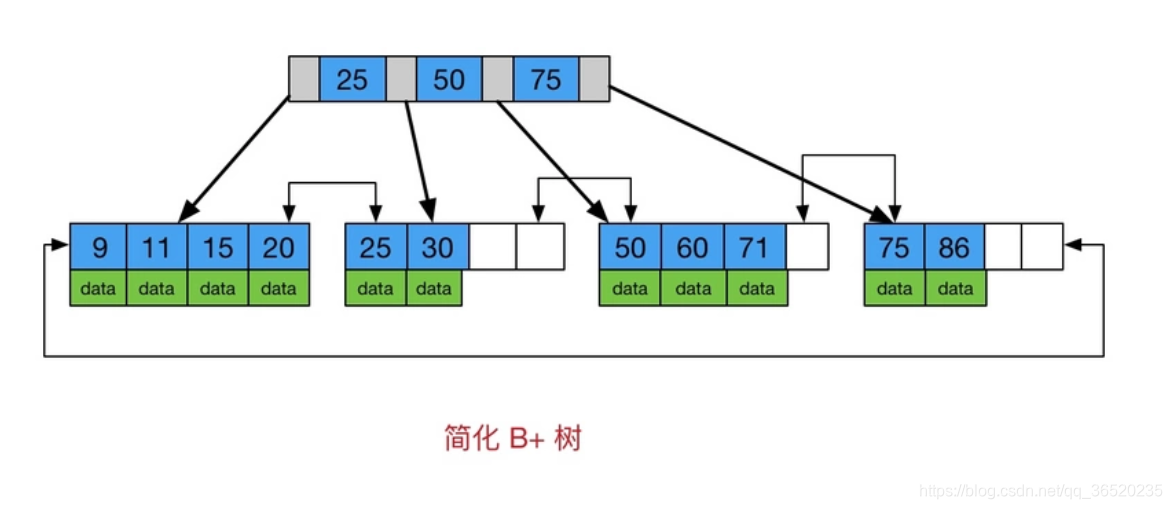
重要的第一点: - 重要的第一点:B+ Tree有一个很大的改变就是他的每一个非叶子节点的内节点中都没有date这个概念了,都变成了key,因为他的date都放在了叶子节点上,这样的一个最大的好处就利用了局部性原理(当一个数据被用到时,其附近的数据也通常会马上被使用)与磁盘预读的特性(磁盘往往不是严格按需读取,而是每次都会预读,即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据【这个一定的长度就是一个节点的大小设置为16K】放入内存)
- 接着上面的:预读的长度一般为页(page)的整倍数。页是计算机管理存储器的逻辑块,硬件及操作系统往往将主存和磁盘存储区分割为连续的大小相等的块,每个存储块称为一页(在许多操作系统中,页得大小通常为4k),主存和磁盘以页为单位交换数据。当程序要读取的数据不在主存中时,会触发一个缺页异常,此时系统会向磁盘发出读盘信号,磁盘会找到数据的起始位置并向后连续读取一页或几页载入内存中,然后异常返回,程序继续运行。
- 重要的第二点:由于上面我们说的预读原理,因为B+ Tree中节点的内节点无 data 域,其实就是因为没有date域了,但是每次IO的页的大小是固定的,但是B+Tree中没有了date域,那么肯定每次IO读取若干个块块中包含的Key域的值肯定更多啊,B+树单次磁盘 IO 的信息量大于B树,从这点来看B+树相对B树磁盘 IO 次数少。
- 据库系统的设计者巧妙利用了磁盘预读原理,将一个节点的大小设为等于一个页,这样每个节点只需要一次I/O就可以完全载入。
- 为了达到这个目的在实际实现B-Tree还需要使用如下技巧:每次新建节点时,直接申请一个页的空间,这样就保证一个节点物理上也存储在一个页里,加之计算机存储分配都是按页对齐的,就实现了一个node只需一次I/O。
重要的第二点:
- B+Tree中因为数据都在叶子节点,所以每次查询的时间复杂度是固定的,因为稳定性保证了
- 而且叶子节点之间都是链表的结构,所以B+ Tree也是可以支持范围查询的,而B树每个节点 key 和 data 在一起,则无法区间查找。
MySQL事务底层实现原理
事务特性
事务特性分为:
原子性 每一个事务都是不可分割的整体,要么全部成功要么全部失败;
一致性 事务执行后的结果是和预设的规则完全符合的,不会因为出现系统意外等原因和预测的结果不一致;
隔离性 事务与事务之间是相互独立的,互不影响;也是在事务并发时实现一致性的一个前提,可以设置4种隔离级别。级别越高一致性越强,但并发性越低;
持久性 事务一旦提交就会永久保存,不会因为系统意外原因而丢失
1.读未提交 会读到其他事务未提交的数据,产生脏读
2.读已提交 解决脏读,但在同一事务中多次读取单行数据会得到不同结果,即不可重复读的问题
3.可重复读 解决不可重复读,但会在多次范围查询时,得到数量不同的结果,即幻读。在innodb引擎中,不会存在此问题,实现原理是临键锁。
4.可串行化 解决幻读
innodb事务的这些特性如何实现?锁、MVCC
锁
innodb一共有5种锁:共享锁(行)、排它锁(行)、意向共享锁(表)、意向排它锁(表)、自增锁。
行锁实现有三种算法,又称为:临键锁next-key、间隙所gap和记录锁record。默认隔离级别可重复读使用临键锁作为行锁的实现算法。
InnoDB的行锁是通过给索引上的索引项加锁来实现的,只有通过索引条件进行数据检索,InnoDB才使用行级锁,否则InnoDB 将使用表锁(锁住全部索引)。
锁的类型
1.共享锁:也称为==读锁==,可以让多个事务同时对数据进行操作时可以访问到数据,但不能修改。使用方式:
select语句+LOCK IN SHARE MOD
2.排它锁:又称为==写锁==。一个事务持有了一行数据的排它锁时,其他事务不能再访问和修改这行数据。innodb默认update delete insert上会加排它锁,select使用方式:
select语句+for update
3.意向共享锁:在事务对某一行加共享锁时,要先给该表加上意向共享锁。
4.意向排它锁:在事务对某一行数据加排它锁时,必须要先给该表加上意向排它锁。
作用是,当某一个事务需要去锁表时,不用判断每一行上是否有不兼容的锁,只需要判断有没有意向锁。如写操作锁表,判断某行数据是否存在共享锁,如果拿不到意向锁就可直接阻塞操作。
5.自增锁:针对自增列自增长的一个特殊的表级别锁。
锁的算法
1.临键锁next-key:当sql语句按照范围查询,并且有数据命中的时候会给索引加上临键锁,锁住命中索引项的前一个索引到命中索引项的后一个索引之间的一个左开右闭区间。因为锁住区间,所以避免了幻读。
2.间隙锁gap:当sql语句查找未命中时,会锁住查询条件值附近的间隙。
3.记录锁record:使用唯一索引查询并精准匹配到数据,则只会锁住该索引项。
这三种算法锁的原理基于b+tree索引。
死锁
事务并发时,每个事务都持有锁(或者是已经在等待锁),每个事务都需要再继续持有锁,然后事务之间产生加锁的循环等待,形成死锁。避免死锁:
1)类似的业务逻辑以固定的顺序访问表和行。
2)大事务拆小。大事务更倾向于死锁,如果业务允许,将大事务拆小。
3)在同一个事务中,尽可能做到一次锁定所需要的所有资源,减少死锁概 率。
4)降低隔离级别,如果业务允许,将隔离级别调低也是较好的选择 。
5)为表添加合理的索引。可以看到如果不走索引将会为表的每一行记录添 加上锁(或者说是表锁)
MVCC多版本并发控制
并发访问(读或写)数据库时,对正在事务内处理的数据做 多版本的管理。以达到用来避免写操作的堵塞,从而引发读操 作的并发问题。
新增:会给行数据添加两个隐藏列,数据版本号和删除版本号。数据版本号值为插入时的事务id,删除版本号默认为null。
删除:会给行数据的删除版本号设一个当前事务id值。
修改:会先拷贝一份行数据,再把原先行数据的删除版本号设值,再修改拷贝的数据,并改变数据版本号值。
查询:必须保证当前事务ID大于等于该行数据的数据版本号,并且删除版本号必须为null或者大于当前事务ID值。
undo log
undo log作用是保证了事务的原子性和普通select的快照读。当事务开启的时候会拷贝当前数据到undo log中,此时有其他事务中的select读取数据直接从undo log中获取,若事务回滚可根据undo log恢复原始数据。
redo log
redo log保证了事务的持久性。事务开启后,只要开始改变数据信息就会持续写入redo buffer中,具体落盘可以指定不同的策略。在数据库发生意外故障时,尚有修改的数据未写入磁盘,在重启mysql服务的时候,根据redo log恢复事务修改后的新数据。
Redo buffer 持久化到Redo log的策略有三种:
取值 0 每秒一次进行提交持久化[可能丢失一秒内 的事务数据]
取值 1 默认值,每次事务提交执行Redo buffer --> Redo log OS cache -->flush cache to disk [最安全,性能最差的方式]
取值 2 每次事务提交到系统缓存OS cache,再每一秒从系统缓存中执行持久化 操作
数据库的乐观锁和悲观锁
https://www.cnblogs.com/kyoner/p/11318979.html
详细分析MySQL事务日志(redo log和undo log)
我们发现三个单列索引只有 userid 有效(位置为查询条件第一个),其他两个都没有用上。
那么为什么没有用上呢?按照我们的理解,三个字段都加索引了,无论怎么排列组合查询,应该都能利用到这三个索引才对!
其实这里其实涉及到了mysql优化器的优化策略!当多条件联合查询时,优化器会评估用哪个条件的索引效率最高!它会选择最佳的索引去使用,也就是说,此处userid 、mobile 、billMonth这三个索引列都能用,只不过优化器判断只需要使用userid这一个索引就能完成本次查询,故最终explain展示的key为userid。
当然,如果优化器判断本次查询非要全使用三个索引才能效率最高,那么explain的key就会是userid 、mobile 、billMonth,都会生效!
https://my.oschina.net/xiaoyoung/blog/3046779
创建组合索引时,索引列顺序的选择
https://blog.csdn.net/miaoyibo12/article/details/89091329
https://www.cnblogs.com/wzyxidian/p/5400530.html
CPU的缓存一致性协议
https://www.cnblogs.com/zhuifeng523/p/11985842.html
MySQL B+Tree 索引和 Hash 索引的区别?
Hash 索引结构的特殊性,其检索效率非常高,索引的检索可以一次定位;
B+树索引需要从根节点到枝节点,最后才能访问到页节点这样多次的 IO访问;
那为什么大家不都用 Hash 索引而还要使用 B+树索引呢?
Hash 索引
- Hash 索引仅仅能满足"=",“IN"和”<=>"查询,不能使用范围查询,因为经过相应的 Hash 算法处理之后的 Hash 值的大小关系,并不能保证和 Hash 运算前完全一样;
- Hash 索引无法被用来避免数据的排序操作,因为 Hash 值的大小关系并不一定和 Hash 运算前的键值完全一样;
Hash 索引不能利用部分索引键查询,对于组合索引,Hash 索引在计算Hash 值的时候是组合索引键合并后再一起计算 Hash 值,而不是单独计算Hash 值,所以通过组合索引的前面一个或几个索引键进行查询的时候,Hash 索引也无法被利用; - Hash 索引在任何时候都不能避免表扫描,由于不同索引键存在相同 Hash 值,所以即使取满足某个 Hash 键值的数据的记录条数,也无法从 Hash 索引中直接完成查询,还是要回表查询数据;
- Hash 索引遇到大量Hash 值相等的情况后性能并不一定就会比B+树索引高。
B+Tree 索引
MySQL 中,只有 HEAP/MEMORY 引擎才显示支持 Hash 索引。
常用的 InnoDB 引擎中默认使用的是 B+树索引,它会实时监控表上索引的使用情况,如果认为建立哈希索引可以提高查询效率,则自动在内存中的“自适应哈希索引缓冲区”建立哈希索引(在 InnoDB 中默认开启自适应哈希索引),通过观察搜索模式,MySQL 会利用 index key 的前缀建立哈希索引,如果一个表几乎大部分都在缓冲池中,那么建立一个哈希索引能够加快等值查询。
B+树索引和哈希索引的明显区别是:
如果是等值查询,那么哈希索引明显有绝对优势,因为只需要经过一次算法即可找到相应的键值;当然了,这个前提是,键值都是唯一的。如果键值不是唯一的,就需要先找到该键所在位置,然后再根据链表往后扫描,直到找到相应的数据;
如果是范围查询检索,这时候哈希索引就毫无用武之地了,因为原先是有序的键值,经过哈希算法后,有可能变成不连续的了,就没办法再利用索引完成范围查询检索;
同理,哈希索引没办法利用索引完成排序,以及 like ‘xxx%’ 这样的部分模糊查询(这种部分模糊查询,其实本质上也是范围查询);
哈希索引也不支持多列联合索引的最左匹配规则;
B+树索引的关键字检索效率比较平均,不像 B 树那样波动幅度大,在有大量重复键值情况下,哈希索引的效率也是极低的,因为存在所谓的哈希碰撞问题。
在大多数场景下,都会有范围查询、排序、分组等查询特征,用 B+树索引就可以了。
sql 查询语句确定创建哪种类型的索引,如何优化查询:
性能优化过程中,选择在哪个列上创建索引是最重要的步骤之一,可以考虑使用索引的主要有两种类型的列:
在 where 子句中出现的列,在 join 子句中出现的列。
考虑列中值的分布,索引的列的基数越大,索引的效果越好。
使用短索引,如果对字符串列进行索引,应该指定一个前缀长度,可节省大量索引空间,提升查询速度。
利用最左前缀,顾名思义,就是最左优先,在多列索引,有体现:(ALTER TABLE people ADD INDEX lname_fname_age (lame,fname,age); ),所谓最左前缀原则就是先要看第一列,在第一列满足的条件下再看左边第二列,以此类推。
不要过度建索引,只保持所需的索引。每个额外的索引都要占用额外的磁盘空间,并降低写操作的性能。
在修改表的内容时,索引必须进行更新,有时可能需要重构,因此,索引越多,所花的时间越长。
MySQL 只对一下操作符才使用索引:<,<=,=,>,>=,between,in
以及某些时候的 like(不以通配符%或_开头的情形)。
.数据库崩溃时事务的恢复机制(REDO 日志和UNDO 日志)?
Undo Log
Undo Log 是为了实现事务的原子性,在 MySQL 数据库 InnoDB 存储引擎中, 还用了 Undo Log 来实现多版本并发控制(简称:MVCC)。
事务的原子性(Atomicity)事务中的所有操作,要么全部完成,要么不做任何操作, 不能只做部分操作。
如果在执行的过程中发生了错误,要回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过。
原理 Undo Log 的原理很简单,为了满足事务的原子性,在操作任何数据之前, 首先将数据备份到一个地方(这个存储数据备份的地方称为 UndoLog)。
然后进行数据的修改。如果出现了错误或者用户执行了 ROLLBACK 语句,系统可以利用 Undo Log 中的备份将数据恢复到事务开始之前的状态。
之所以能同时保证原子性和持久化,是因为以下特点:
更新数据前记录 Undo log。
为了保证持久性,必须将数据在事务提交前写到磁盘。只要事务成功提交, 数据必然已经持久化。
Undo log 必须先于数据持久化到磁盘。如果在 G,H 之间系统崩溃,undolog 是完整的, 可以用来回滚事务。
如果在 A-F 之间系统崩溃,因为数据没有持久化到磁盘。所以磁盘上的数据还是保持在事务开始前的状态。
缺陷:每个事务提交前将数据和 Undo Log 写入磁盘,这样会导致大量的磁盘IO,因此性能很低。
如果能够将数据缓存一段时间,就能减少 IO 提高性能。但是这样就会丧失事务的持久性。因此引入了另外一种机制来实现持久化,即 Redo Log。
Redo Log
原理和 Undo Log 相反,Redo Log 记录的是新数据的备份。在事务提交前,只要将 Redo Log 持久化即可,不需要将数据持久化。当系统崩溃时, 虽然数据没有持久化,但是 Redo Log 已经持久化。系统可以根据 Redo Log 的内容,将所有数据恢复到最新的状态。
MYSQL 表左连接 ON AND 和ON WHERE 的区别
\1. on的条件是在连接生成临时表时使用的条件,以左表为基准 ,不管on中的条件真否,都会返回左表中的记录
2.**where条件是在临时表生成好后,再对临时表过滤。**此时 和left join有区别(返回左表全部记录),条件不为真就全部过滤掉,on后的条件来生成左右表关联的临时表,
where后的条件是生成临时表后对临时表过滤
on and是进行韦恩运算时 连接时就做的动作,where是全部连接完后,再根据条件过滤
MySQL中MyISAM和InnoDB的索引方式以及区别与选择
https://blog.csdn.net/LJFPHP/article/details/80029968
select 中 in 和 exist 有什么区别
https://www.cnblogs.com/emilyyoucan/p/7833769.html
提交读和可重复读的实现原理
https://blog.csdn.net/qq_36951116/article/details/88832798?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-3.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-3.control
主键和索引的区别
https://zhuanlan.zhihu.com/p/158745657
mysql的锁类型
https://www.cnblogs.com/lamp01/p/10751908.html
mysql行锁什么时候变表锁
SQL语句赋值与表列类型不匹配时,MySql的优化器强制转化为匹配的类型,导致行锁升级为表锁。
当 Where 查询条件中的字段没有索引时,更新操作会锁住全表!
可以看到,在有索引的情况下,更新不同的行,InnoDB 默认的行锁不会阻塞。
没有索引或者索引失效时,InnoDB 的行锁变表锁
select语句什么时候行锁变表锁
索引失效就会行锁变表锁,在索引上运算、把索引写在函数里面(count)、like %…等等吧
检索字段包含非索引字段时候
建立索引 一般是是按照数据库字段顺序 去建立吗? 不按照这种顺序建立索引,这两种有什么区别呢?
MySql的索引类型
https://www.cnblogs.com/huangrenhui/p/12576366.html
mysql 不同索引的区别和适用情况总结
mysql的主从复制
https://www.jianshu.com/p/faf0127f1cb2
为什么MyISAM会比Innodb的查询速度快
https://blog.csdn.net/jc_benben/article/details/83243288
数据库优化-索引的创建-MySql-index-SQL优化-避免全表扫描
https://blog.csdn.net/li1375942531/article/details/107387697
为何PreparedStatement能够防止Sql注入
https://www.jianshu.com/p/aaf6b253c50a
将对应的应的条件前面加了对应引号,标识这个条件是一个不可变整体,不是两个Sql语句,例如对应的sql
select * from test where name = ‘123456789123456’ or 1=1;
加上单引号之后变为
select * from test where name = ‘123456789123456 or 1=1’;
有效的防止了Sql注入.
彻底搞清分库分表(垂直分库,垂直分表,水平分库,水平分表)
https://blog.csdn.net/weixin_44062339/article/details/100491744?utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.control&dist_request_id=&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.control
mysql-覆盖索引
数据库事务学习理解(二)事务是如何保证ACID的
https://blog.csdn.net/weixin_43326401/article/details/104003945
数据库乐观锁和悲观锁的理解和实现
https://blog.csdn.net/qq_35868412/article/details/89638759
myisam的select为什么快呢? 什么原因呢?
Innodb查询时要先映射到块 再映射到行 而myisam 直接映射的是文件的地址
隔离级别的实现原理
MYSQL的B+Tree索引树高度如何计算
红黑树与平衡二叉树的比较
2:mysql事务的特性,事务的实现方式
A:A:A:ACID特性
1)原子性 指的是一个事务里的命令要不全部执行,要不就全部不执行,如果中间发生了错误,会导致前面的命令发生回滚,后面的命令不在执行
2)一致性 指的是事务在执行前后,数据应该是一致的,举个例子说 A向B转了100块钱,B的账户里应该多100,如果A的账户没有减100,那么就是不一致的
3)隔离性 针对并发事务来说的,事务之间应该是隔离的,不能由一个事务影响到其他事务;
4)持久性 事务执行完以后,数据可以永久的保持在数据库中,要是中间发生了故障,也能进行修复
OS:OS:OS:因为这个题我会,所以我问了一下需不需要说一下事务是怎么实现的,面试官说可以
1)原子性实现:是用undolog实现的,uodolog的意思是回滚日志,指的是每次在有写命令的时候,会先向undolog中写入一份,如果中间发生了故障,就可以通过uodolog进行回滚,比如说如果是insert命令只要delete就可以了,delete命令只要insert就可以了,update命令只要更新回原来的值就可以了
2)持久性实现:是用redolog实现的,意思是重做日志,mysql在读取或者修改数据的时候并不是直接进行读取修改的,而是用到了缓存的概念,因为如果每次读取修改都要对数据库进行操作,那么会对mysql造成压力,所以先对缓存进行操作,在对mysql进行操作,
如果要读取数据的话,是先去缓存中读取,如果缓存中没有,才去mysql中读取,然后再丢到缓存中去,修改数据的话也是先修改缓存,再修改数据库,但是这样的话就会出现问题,如果修改了缓存,但是还没有同步到数据库中去,这时候mysql宕机了,就会发生数据不一致的问题;
所以每次再有写命令的时候,先向redolog中写入,再写入缓存,要是mysql宕机了,我们也可以靠redolog进行恢复;
3)隔离性实现:隔离性的实现有两种方式,一种是锁机制,一种是MVCC多版本并发控制
锁机制的话就是加锁,行锁和表锁,加锁以后数据就不能被其他事务读取并且修改了,通过加锁的方式可以解决并发修改的问题,也就是写操作对写操作的影响
MVCC的话是多版本并发控制,在数据库的每一行后面都有一个隐藏的列,记录的事务的id和指向undolog的指针, undolog的指针又指向更早版本的undolog,通过隐藏的列和undolog可以把数据恢复到任一版本,然后还有一个readview,可重复读是在事务执行之后,第一个select语句之前生成readview,可以解决脏读,不可重复读,幻读的问题,读已提交是在事务执行之后,每个select之前生成readview,可以解决脏读的问题,但是解决不了不可重复读,幻读的问题(这里的话我本来是想举几个例子来说明一下,但是不知道怎么举,怕面试官理解不了我的想法)
它们是怎么解决的呢,是通过三方面的比较实现的,拿数据事务的id和下一个要分配的事务id(low_limit_id)进行比较,如果比low_limit_id小才可见,拿数据的事务id和当前活跃事务的最小id(up_limit_id)进行比较,如果比up_limit_id小才可见,可重复读会在事务执行之后,第一个select语句之前生成readview,保存了当前活跃事务的id,如果数据的事务id在活跃事务中,那么是不可见的,否则是可见的(这段话因为紧张没有说出来)
还有一种方式是加锁读,通过加共享锁和排他锁实现,共享锁的话是如果一个数据要读取数据,那么就会加共享锁,加了共享锁一种就只能加共享锁,不能再加排他锁;排他锁的话是一个事务如果要修改数据就会加排他锁,加了排他锁就什么锁都不能再加了,这样可以解决脏读,不可重复读的问题
如果要解决幻读的问题,还需要用到next-key lock,这个是行锁 和 间隙锁的结合,间隙锁指的是锁住一段数据的间隙,不锁存在的数据,next-key lock的话就是即要锁数据也要锁间隙,就可以解决幻读的问题;
4)一致性的实现:一致性的实现已经不能单纯靠日志实现了,而是要服务器层面 和 数据库本身实现,因为我不会mysql的架构,所以也就没有多说
MYSQL索引失效的原理
https://cloud.tencent.com/developer/article/1704743
事务实现原理重要
https://cloud.tencent.com/developer/article/1527179
https://juejin.cn/post/6871046354018238472
MySQL 覆盖索引详解
https://juejin.cn/post/6844903967365791752
覆盖索引(covering index ,或称为索引覆盖)即从非主键索引中就能查到的记录,而不需要查询主键索引中的记录,避免了回表的产生减少了树的搜索次数,显著提升性能。
MySQL深度分页的问题及优化方案:千万级数据量如何快速分页
MySQL中数据类型介绍
https://www.huaweicloud.com/articles/5ee2366eadeff0d0c19d992495109056.html
多版本并发控制
MVCC 是 MySQL 的 InnoDB 存储引擎实现隔离级别的一种具体方式,用于实现提交读和可重复读这两种隔离级别。而未提交读隔离级别总是读取最新的数据行,要求很低,无需使用 MVCC。可串行化隔离级别需要对所有读取的行都加锁,单纯使用 MVCC 无法实现。
版本号
- 系统版本号 SYS_ID:是一个递增的数字,每开始一个新的事务,系统版本号就会自动递增。
- 事务版本号 TRX_ID :事务开始时的系统版本号。
Undo 日志
MVCC 的多版本指的是多个版本的快照,快照存储在 Undo 日志中,该日志通过回滚指针 ROLL_PTR 把一个数据行的所有快照连接起来。
例如在 MySQL 创建一个表 t,包含主键 id 和一个字段 x。我们先插入一个数据行,然后对该数据行执行两次更新操作。
INSERT INTO t(id, x) VALUES(1, "a");
UPDATE t SET x="b" WHERE id=1;
UPDATE t SET x="c" WHERE id=1;
因为没有使用 START TRANSACTION 将上面的操作当成一个事务来执行,根据 MySQL 的 AUTOCOMMIT 机制,每个操作都会被当成一个事务来执行,所以上面的操作总共涉及到三个事务。快照中除了记录事务版本号 TRX_ID 和操作之外,还记录了一个 bit 的 DEL 字段,用于标记是否被删除。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-q9Az4n62-1673797193274)(…/…/…/typora/image/image-20191208164808217.png)]
INSERT、UPDATE、DELETE 操作会创建一个日志,并将事务版本号 TRX_ID 写入。DELETE 可以看成是一个特殊的 UPDATE,还会额外将 DEL 字段设置为 1。
ReadView
MVCC 维护了一个 ReadView 结构,主要包含了当前系统未提交的事务列表 TRX_IDs {TRX_ID_1, TRX_ID_2, …},还有该列表的最小值 TRX_ID_MIN 和 TRX_ID_MAX。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-K4Qo3nEC-1673797193274)(…/…/…/typora/image/image-20191208171445674.png)]
在进行 SELECT 操作时,根据数据行快照的事务版本号 TRX_ID 与 TRX_ID_MIN 和 TRX_ID_MAX 之间的关系,从而判断数据行快照是否可以使用:
- TRX_ID < TRX_ID_MIN,表示该数据行快照时在当前所有未提交事务之前进行更改的,因此可以使用。
- TRX_ID > TRX_ID_MAX,表示该数据行快照是在事务启动之后被更改的,因此不可使用。
- TRX_ID_MIN <= TRX_ID <= TRX_ID_MAX,需要根据隔离级别再进行判断:
- 提交读:如果 TRX_ID 在 **未提交的事务列表 TRX_IDs ** 列表中,表示该数据行快照对应的事务还未提交,则该快照不可使用。否则(不在未提交事务id序列中)表示已经提交,可以使用。
- 可重复读:都不可以使用。因为如果可以使用的话,那么其它事务也可以读到这个数据行快照并进行修改,那么当前事务再去读这个数据行得到的值就会发生改变,也就是出现了不可重复读问题。
在数据行快照不可使用的情况下,需要沿着 Undo Log 的回滚指针 ROLL_PTR 找到下一个快照,再进行上面的判断。
MySQL中binlog和redo log的一致性问题
https://blog.csdn.net/huangjw_806/article/details/100927097