InfluxDB的查询优化
首先,在学习influxDB的查询优化之前,我们要先学习下InfluxDB的解释器profiler(类似于mysql的Explain语句,不一样的是,sql,hivesql是提前查看执行计划等,Influx是在当前查询的最后一页两张表),能够很好的帮助我们理解和查看执行步骤计划,从而优化你的查询语句
我们先来看看官网是如何解释的:
Use the Flux Profiler package to measure query performance and append performance metrics to your query output. The following Flux profilers are available:
使用 Flux 探查器包测量查询性能并将性能指标追加到查询输出
一、如何使用InfluxDB的查询优化器:profiler
1,先看官网的解释
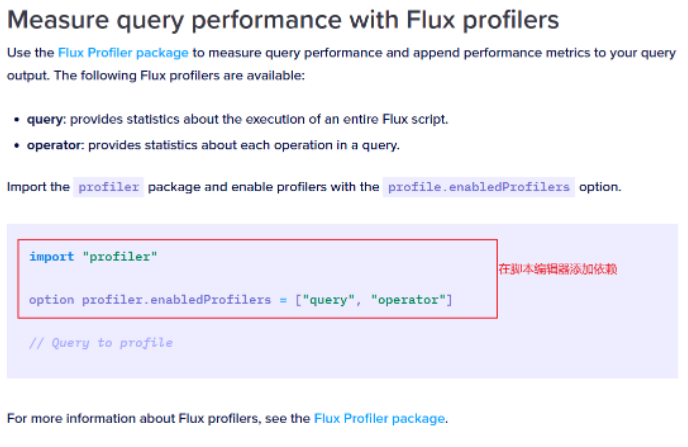
import "profiler"
option profiler.enabledProfilers = ["query", "operator"]
// Query to profile
2,在脚本编辑器中添加依赖后点击submit,并翻到最后一页
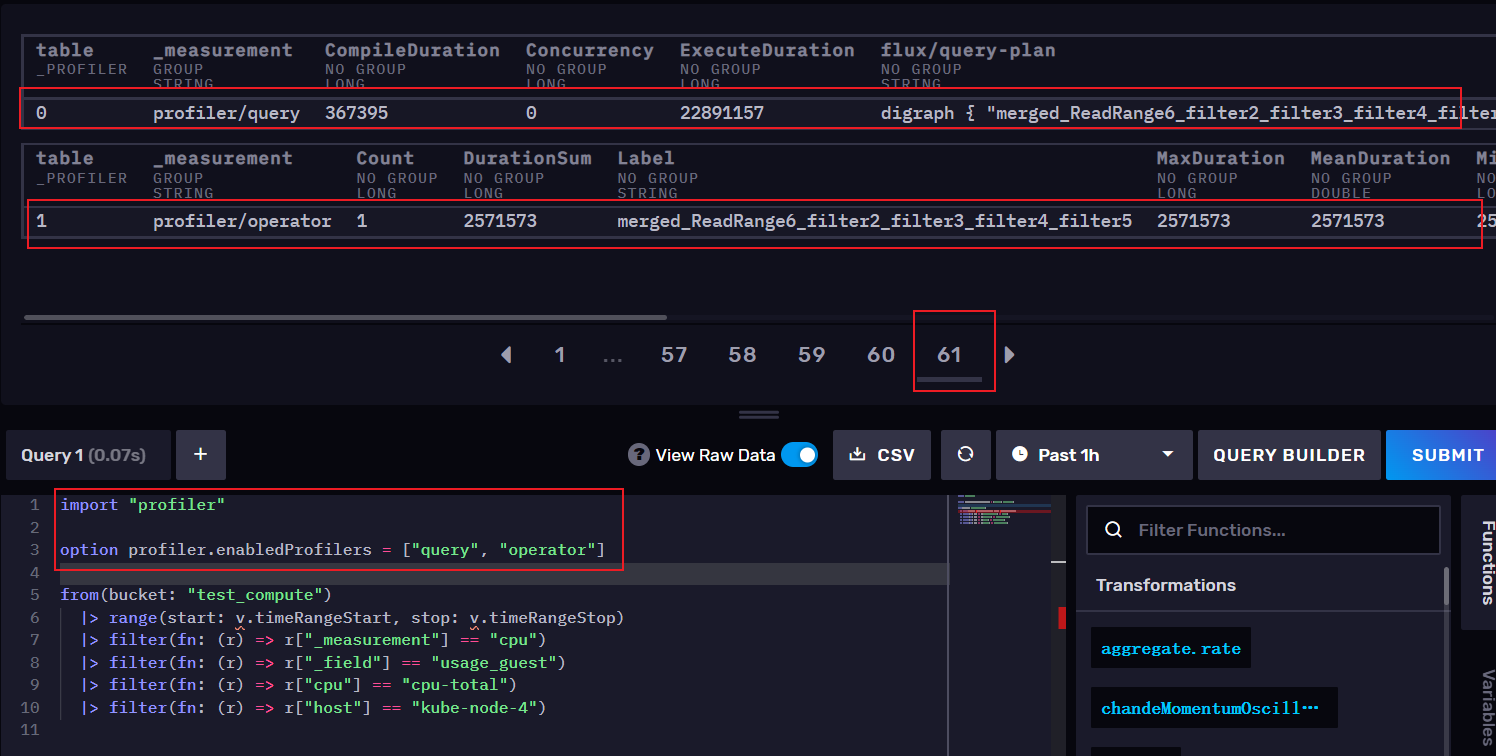
3,如何看懂执行计划
简单来说,query代表提供有关整个 Flux 脚本执行的统计信息。operator 提供有关查询中每个操作的统计信息。相当于算子,类似于Map-Reduce
下面是官网的具体解释
- query: provides statistics about the execution of an entire Flux script.
- operator: provides statistics about each operation in a query.
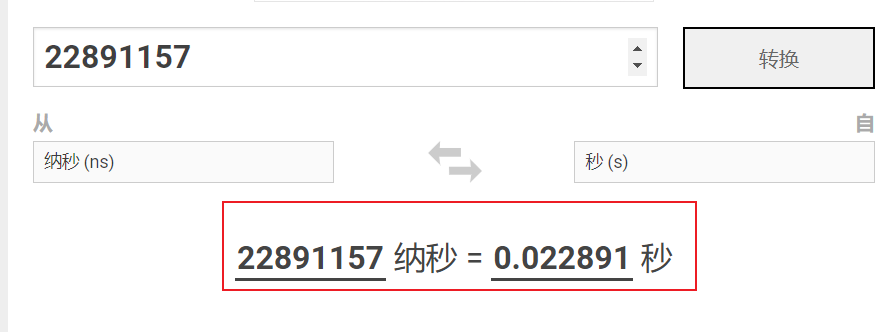
需要注意的是,这里的时间都代表纳秒,long类型,我们需要使用工具将时间转换成秒,由上图可以看出此查询执执行0.022891 秒
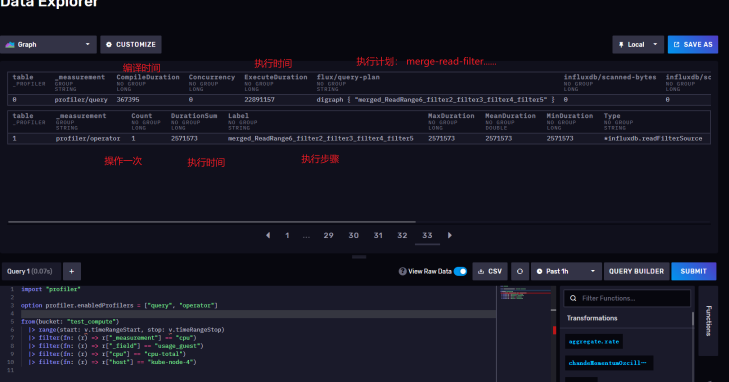
下面贴出来所有字段的明细解释:
1,query
| TotalDuration | 查询总持续时间(以纳秒为单位) |
|---|---|
| CompileDuration | 编译查询脚本所花费的时间(以纳秒为单位) |
| QueueDuration | 排队所花费的时间(以纳秒为单位) |
| RequeueDration | 重新排队花费的时间(以纳秒为单位) |
| PlanDuration | 计划查询所花费的时间(以纳秒为单位) |
| ExecuteDuration | 执行查询所花费的时间(以纳秒为单位) |
| Concurrency | 并发,分配给处理查询的 goroutines。 |
| MaxAllocated | 查询分配的最大字节数(内存) |
| TotalAllocated | 查询时分配的总字节数(包括释放然后再次使用的内存) |
| RuntimeErrors | 查询执行期间返回的错误消息 |
| flux/query-plan | flux 查询计划 |
| influxdb/scanned-values | 数据库扫描磁盘的数据条数 |
| influxdb/scanned-buytes | 数据库扫描磁盘的字节数 |
2,operator
| Type | 操作类型 |
|---|---|
| Label | 标签(标明执行步骤) |
| count | 执行这个操作的总次数 |
| MinDuration | 操作被执行多次中,最快的一次花费的时间(以纳秒为单位) |
| MaxDuration | 操作被执行多次中,最慢的一次花费的时间(以纳秒为单位) |
| DurationSum | 当前操作完成的总持续时间(以纳秒为单位)。 |
| MeanDuration | 操作被执行多次的平均持续时间(以纳秒为单位)。 |
我简单标注几个,给大家参考:
二、flux语句的查询优化
先看官网给出的,由于InfluxDB是时序数据库,存储数据是按照一个个序列来存的,所以,通过存储时间序列的方式来存储对应value,这样能大大的提高效率,为了减少CPU和内存的占用,Influx的语句执行也是有相应的要求,接下来我们分五种方式来分析

1,谓词下推(Pushdowns)
什么是谓词?比如:select * from tbl1 where a>1,那么谓词就是指的是a>1,简单理解为就是查询条件
Use pushdown functions and function combinations at the beginning of your query. Once a non-pushdown function runs, Flux pulls data into memory and runs all subsequent operations there.(在查询开始时使用下推函数和函数组合。一旦非下推函数运行,Flux 就会将数据拉入内存并在那里运行所有后续操作)
下推是将数据操作推送到基础数据源而不是对内存中的数据进行操作的函数或函数组合。使用下推启动查询以提高查询性能。一旦非下推函数运行,Flux 就会将数据拉入内存并在那里运行所有后续操作
简单理解:尽量少的使用内存,在数据进入内存之前进行操作,提前将a>1的数据筛选出来再拉入内存计算
官网给出了用于谓词下推的函数:

注意:由于InfluxDBcloud版本收费,部分函数不支持谓词下推
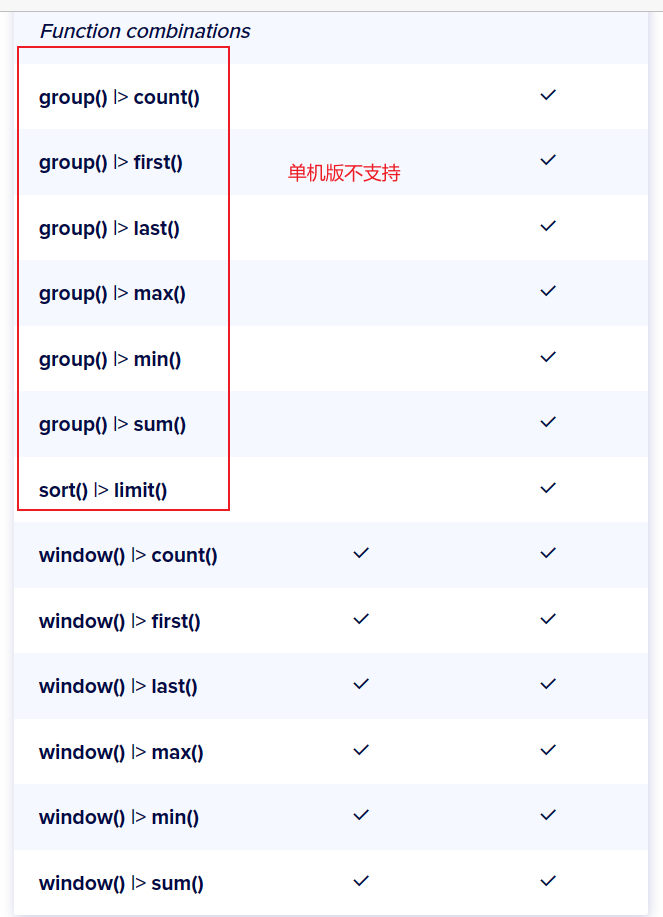
接下来通过有下推和无下推的两条Flux脚本,查看profliler对比一下
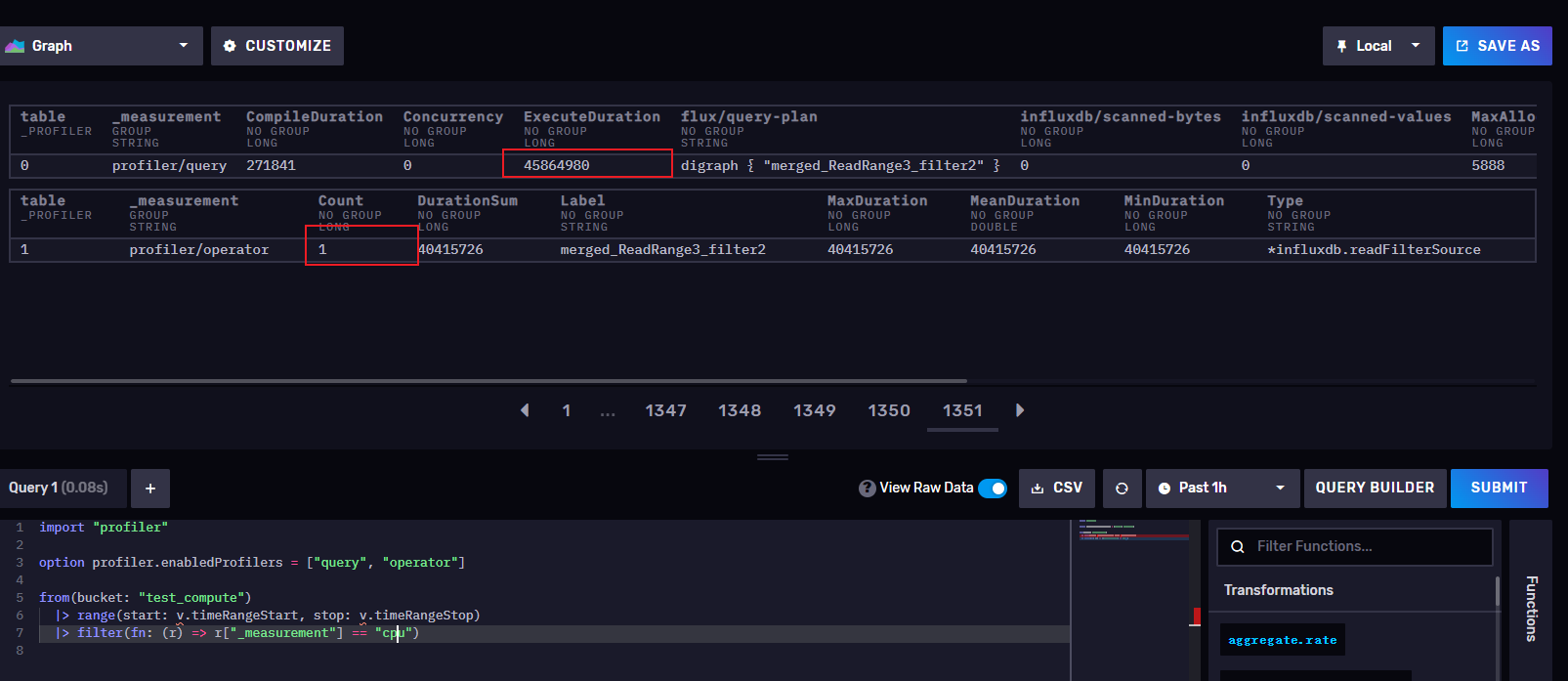
1:在filter中过滤measurement
import "profiler"
option profiler.enabledProfilers = ["query", "operator"]
from(bucket: "test_compute")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "cpu")
2:在filter中过滤measurement,但是cpu我是用字符串来拼接,意思就是说我在执行filter之前又进行了一步计算
import "profiler"
option profiler.enabledProfilers = ["query", "operator"]
from(bucket: "test_compute")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "cp"+"u")
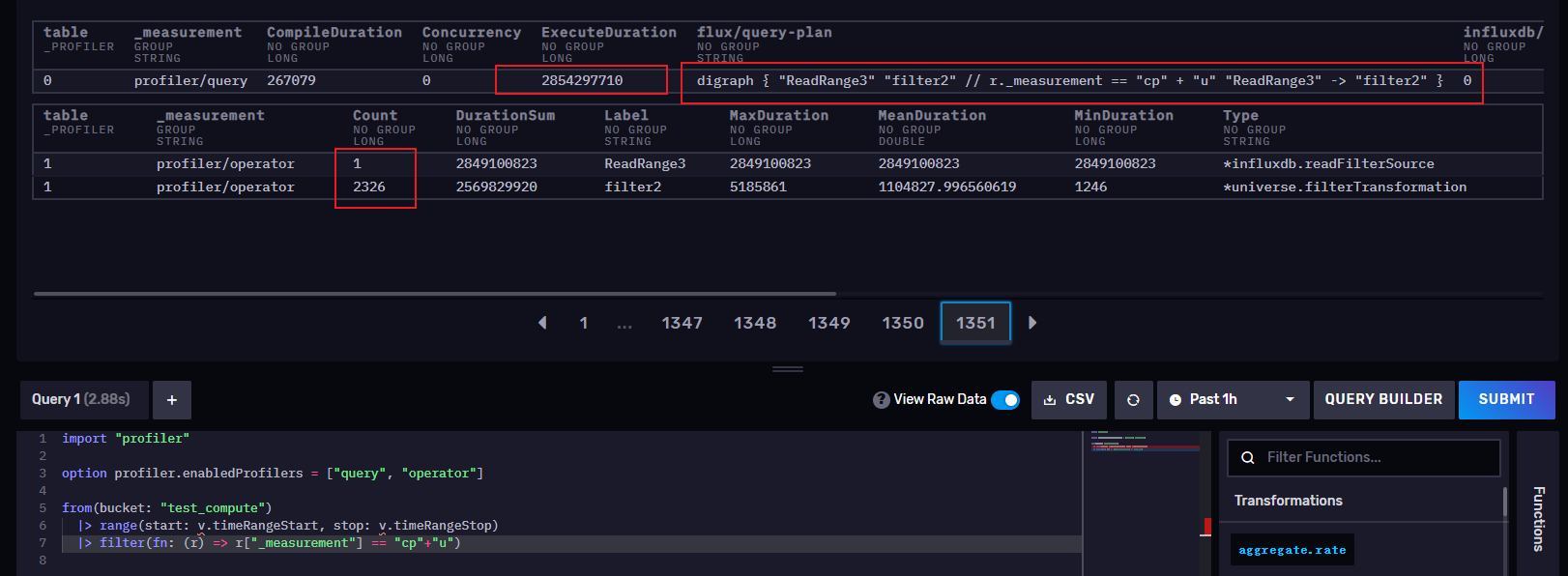
从上面可以看出来,2计划的operator执行了两步,query查询,2计划执行了2854297710NS->2.8543 S,1计划执行了48421932 Ns ->0.048422s,相差了大概60倍的差距,目前测试环境的数据不大,如果数据量大的时候差距还会越来越大
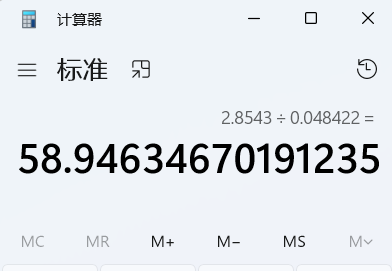
接下里我们再使用谓词下推的函数看一下,可以发现operator执行了一步,查询cpu时一共用时82201876 ns-> 0.08秒
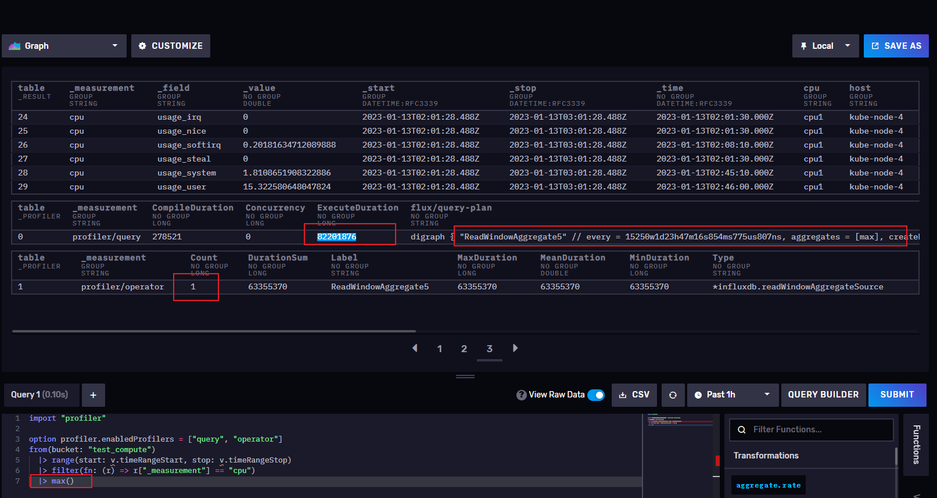
总结:
由上可以看出,谓词下推会大大提高我们的执行效率,所以,我们再filter() 等函数里面切记不要进行复杂计算,在平时工作中使用尽量使用简短明确的表达式,要动态设置过滤器并保持 filter() 函数的下推功能,使用变量在 filter() 之外定义过滤器值
下面给出官网的示例:

2,避免窗口时间过小
窗口化(根据时间间隔对数据进行分组)通常用于聚合和缩减数据采样。通过避免较短的窗口持续时间来提高性能。更多的窗口需要更多的计算能力来评估每行应分配给哪个窗口。合理的窗口持续时间取决于查询的总时间范围。
窗口设置为1分钟 ->172590080 纳秒 = 0.17259 秒
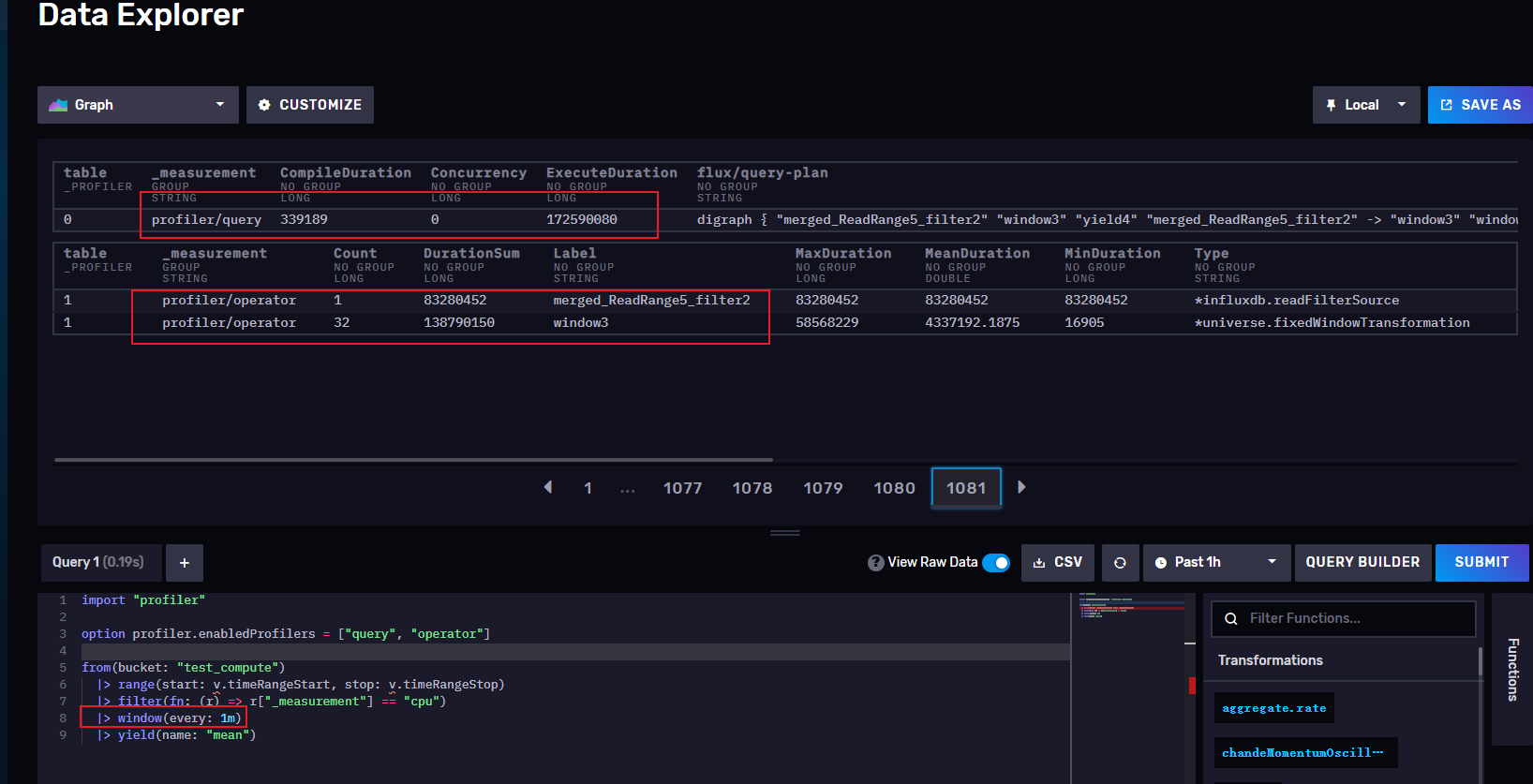
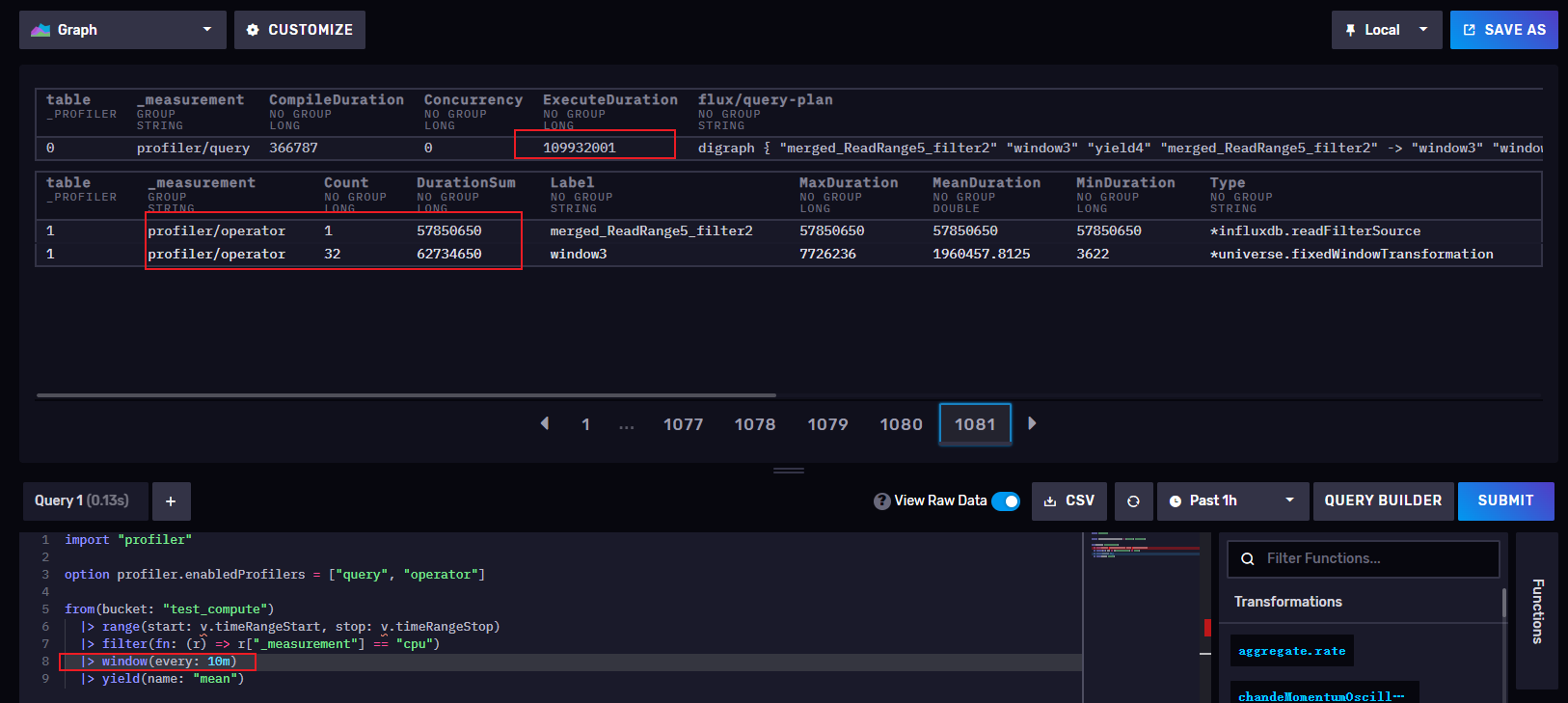
窗口设置为10分钟->109932001 纳秒 = 0.109932 秒
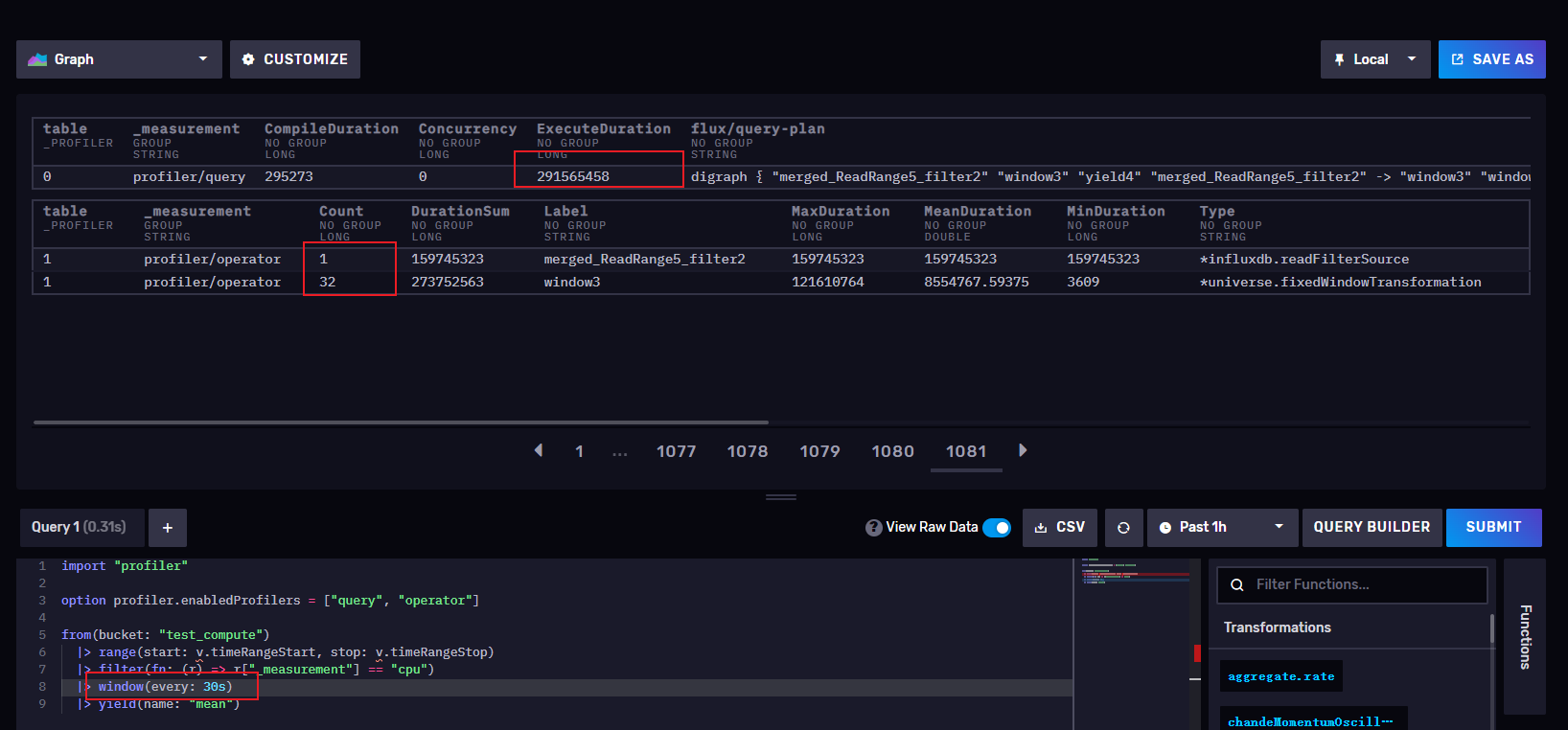
窗口设置为30s->291565458 纳秒 = 0.291565 秒
窗口设置为10s->1009266800 纳秒 = 1.0093 秒
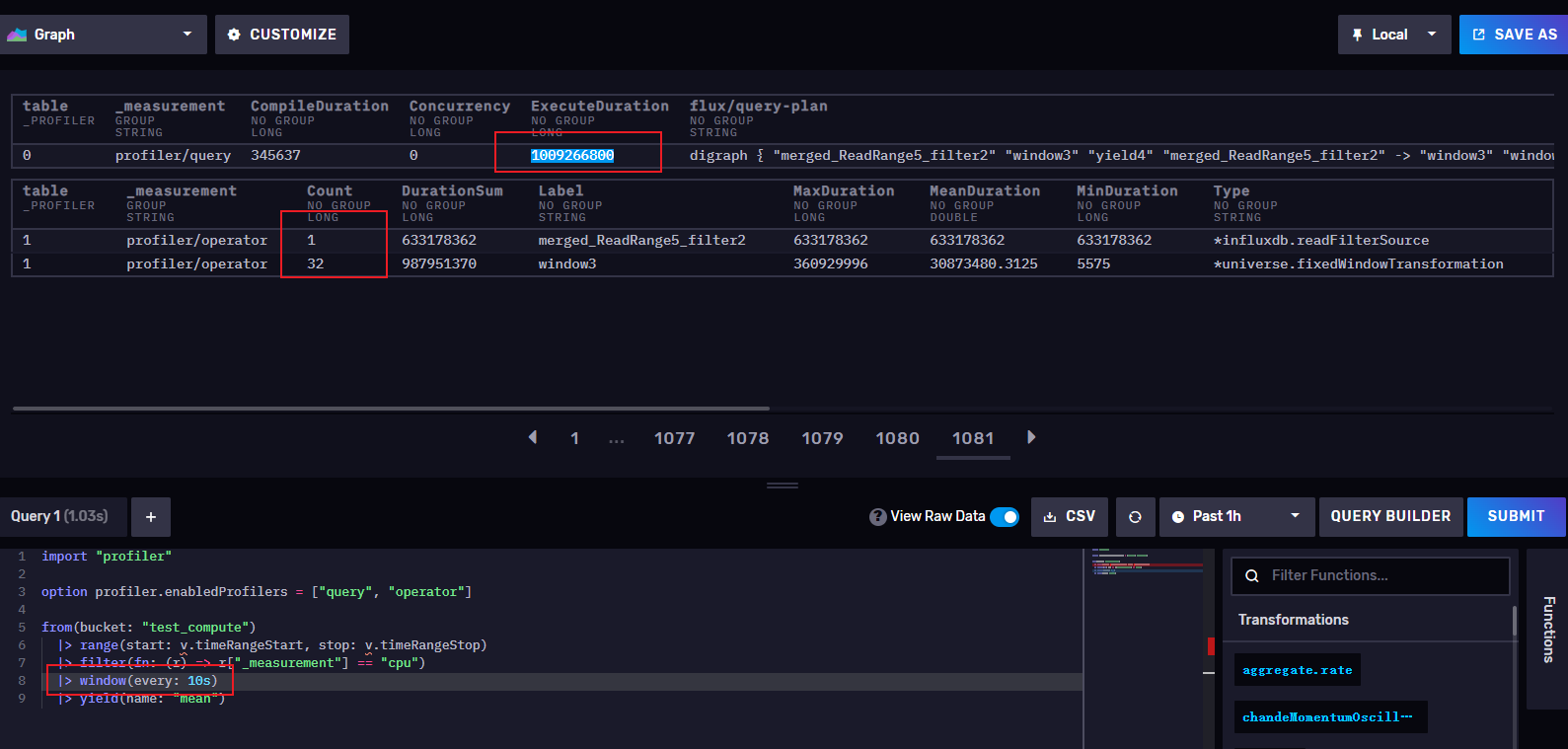
从上面可以看出,窗口越小时,执行时间越长,所以我们再实际工作中不要把window开的过小,窗口过小对应的时间序列就会增多,查询也就越慢,当然,窗口也不是越长越好,要根据实际工作中,结合项目的采集周期合理开窗,我们也可以通过开窗来进行降采样,让每个窗口计算出max()或者min() mean()等再插入另外一个存储桶进行存储
这里再解释下关于窗口函数的两种方式:
window 函数和 aggregateWindow 函数,两者不 同的地方在于,window 函数会将整个表流重新分组。window 开窗后,是按照序列+窗口的 方式对整个表流进行分组。但是 aggregateWindow 函数会保留原来的分组方式,这样一来, 使用 aggregateWindow 函数进行开窗后的表流,仍然是按照序列的方式来分组的。我们平时应使用aggregateWindow()来提高效率
3、避免使用沉重的功能
这里的“沉重”意义理解为Hadoop生态中的MapReduce.要进行分组->聚合->合并->再分组->再聚合,对于大数据量来说,正是因为要产生大量计算才有spark的RDD,广播变量,共享内存等等,然而对于时序数据库来说,这些明显是不可取的。
官方解释:要避免使用 map() reduce() join() union() pivot()等函数,这些都会大大增加cpu或者内存的消耗,以map()为例来说。map会将所有的序列重新遍历一遍
下面我们用pofilter来测试一下
import "profiler"
option profiler.enabledProfilers = ["query", "operator"]
from(bucket: "test_compute")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "cpu")
|> map(fn: (r) => ({r with temp:"213423"}))
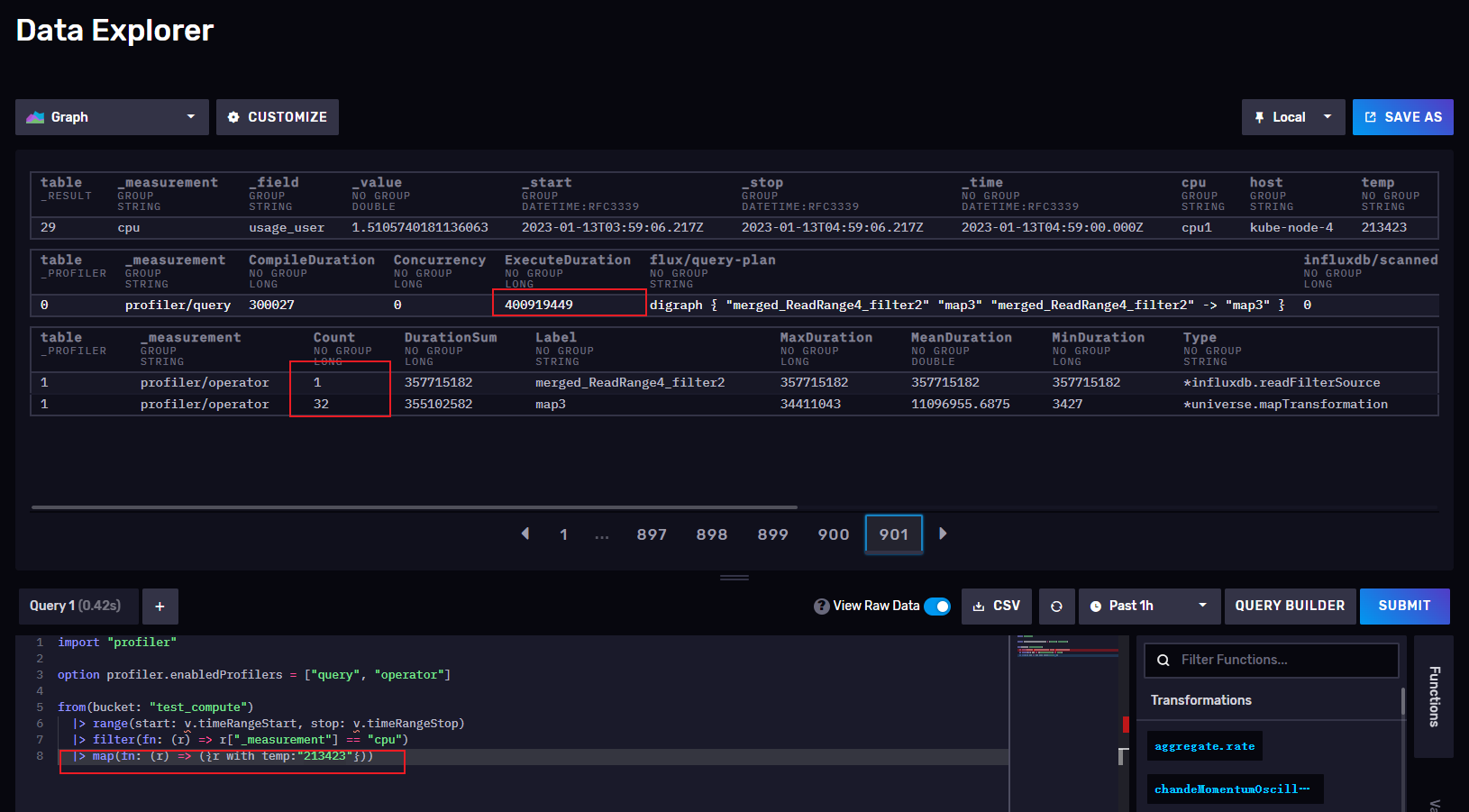
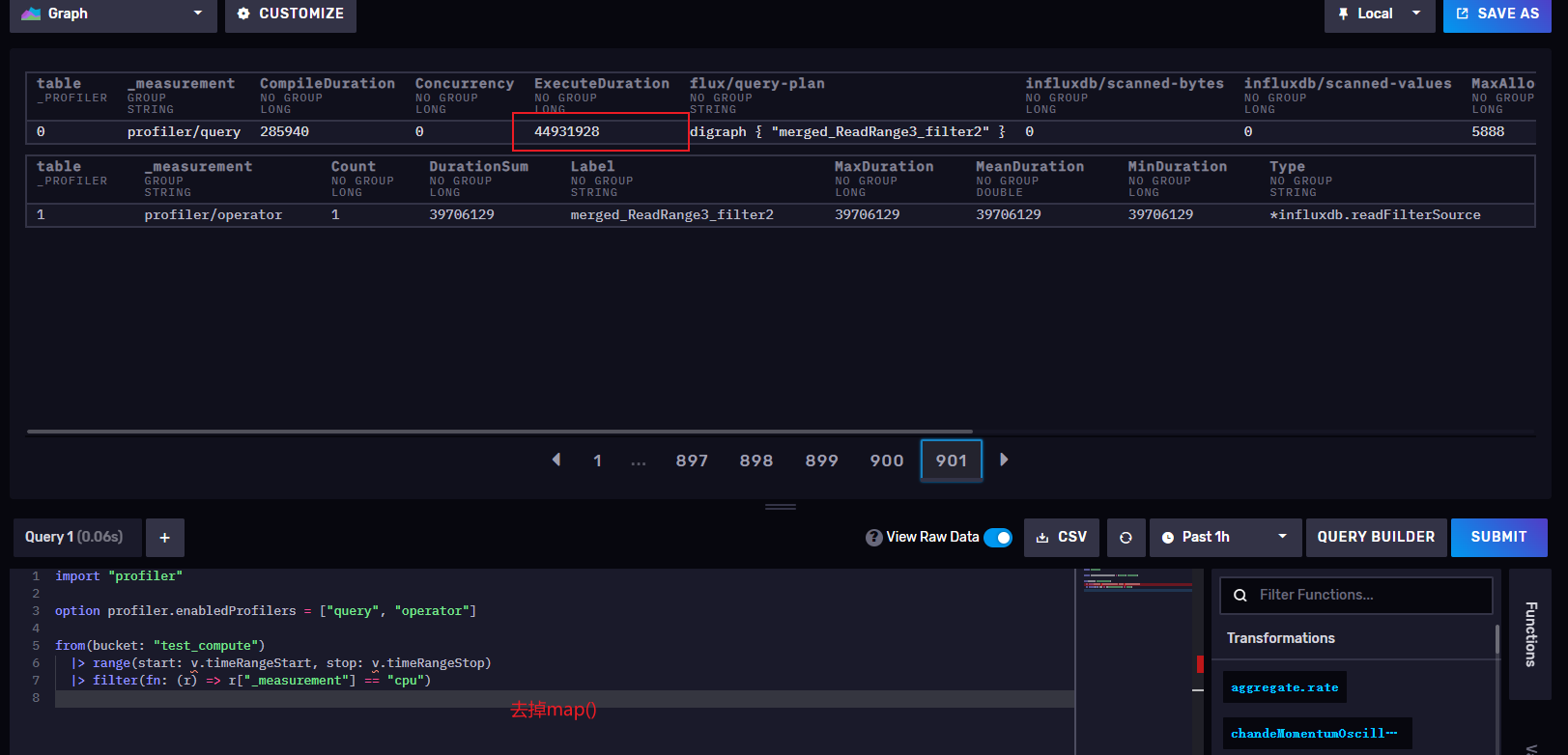
可以看到,我将cpu查询出来后map()再增加一列数据temp:value,query执行要400919449 纳秒 = 0.400919 秒,oprator是两个,去掉map()后只有一个operator,query执行是44931928 纳秒 = 0.044932 秒
我们可以明显的对比来效率,但是官方还是在一直优化(极有可能也是采用分布式的计算,通过共享变量等减小内存或者cpu的开销)
4,尽可能使用 set()而不是 map()
如果你要给数据查一个静态常量,那么 set 比 map 要有很大的性能优势。set(): 如果将列值设置为预定义的静态值,请使用 set() 或 experimental.set()。map():如果使用现有行数据动态设置列值,请使用 map()。
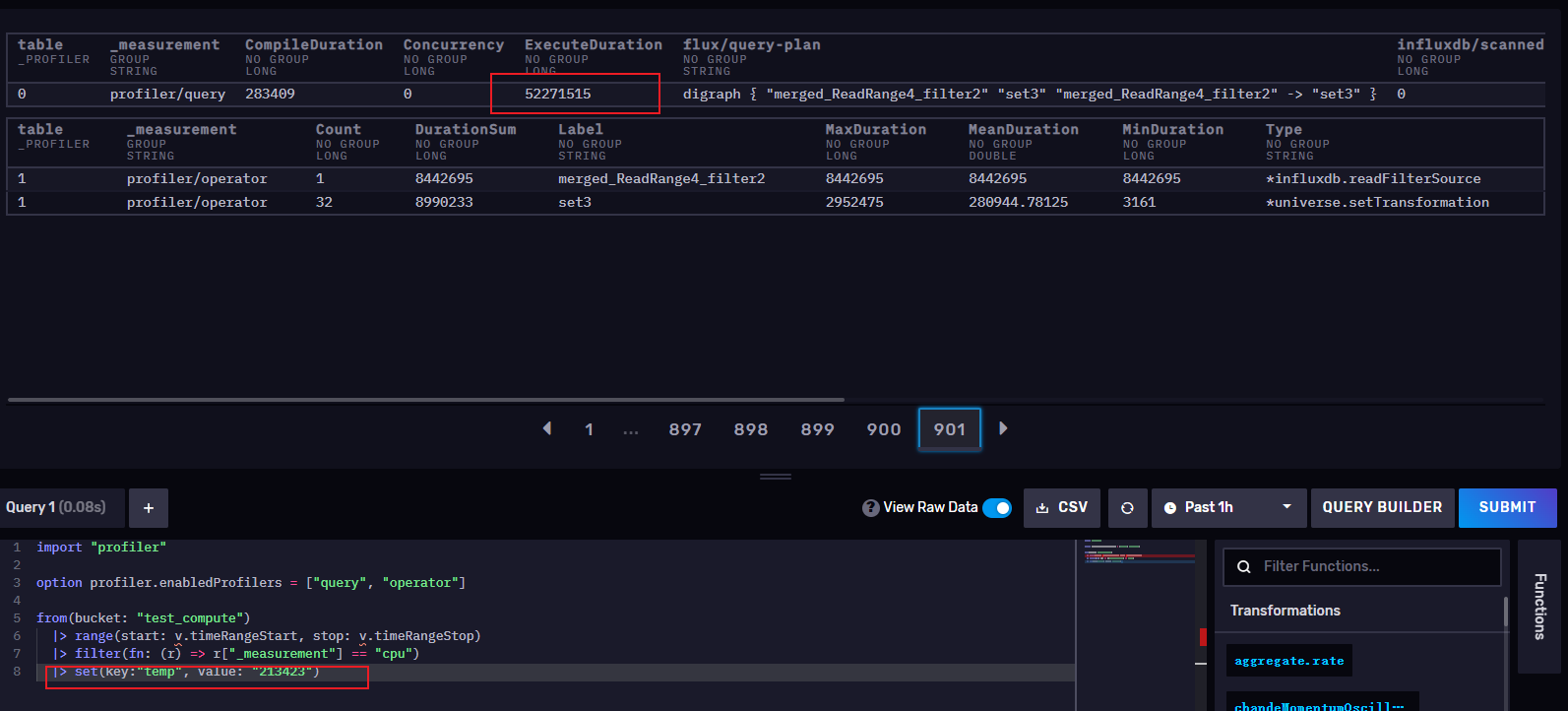
接下来我把上面的Flux脚本修改为set(),发现用时52271515 纳秒 = 0.052272 秒,相对于0.400919s快了0.35s
5,平衡数据的时间范围和数据精度
官网:
To ensure queries are performant, balance the time range and the precision of your data. For example, if you query data stored every second and request six months worth of data, results would include ≈15.5 million points per series. Depending on the number of series returned after filter()(cardinality), this can quickly become many billions of points. Flux must store these points in memory to generate a response. Use pushdowns to optimize how many points are stored in memory.
To query data over large periods of time, create a task to downsample data, and then query the downsampled data instead.
想要保证查询的性能良好,应该平衡好查询的时间范围和数据精度。如果,有一个 measurement 的数据每秒入库一条,你一次请求 6 个月的数据,那么一个序列就能包含 1550 万点数据。如果序列数再多一些,那么数据很可能会变成数十亿点。Flux 必须将这些 数据拉到内存再返回给用户。所以一方面做好谓词下推尽量减少对内存的使用。另外,如果必须要查询很长时间范围的数据,那应该创建一个定时任务来对数据进行降采样,然后 将查询目标从原始数据改为降采样数据。
在窗口函数优化那一节我们也已经说过,关于降采样的问题,这里就不再赘述了,降采样可以处理时间精度的问题,那么我们再来说一下数据精度
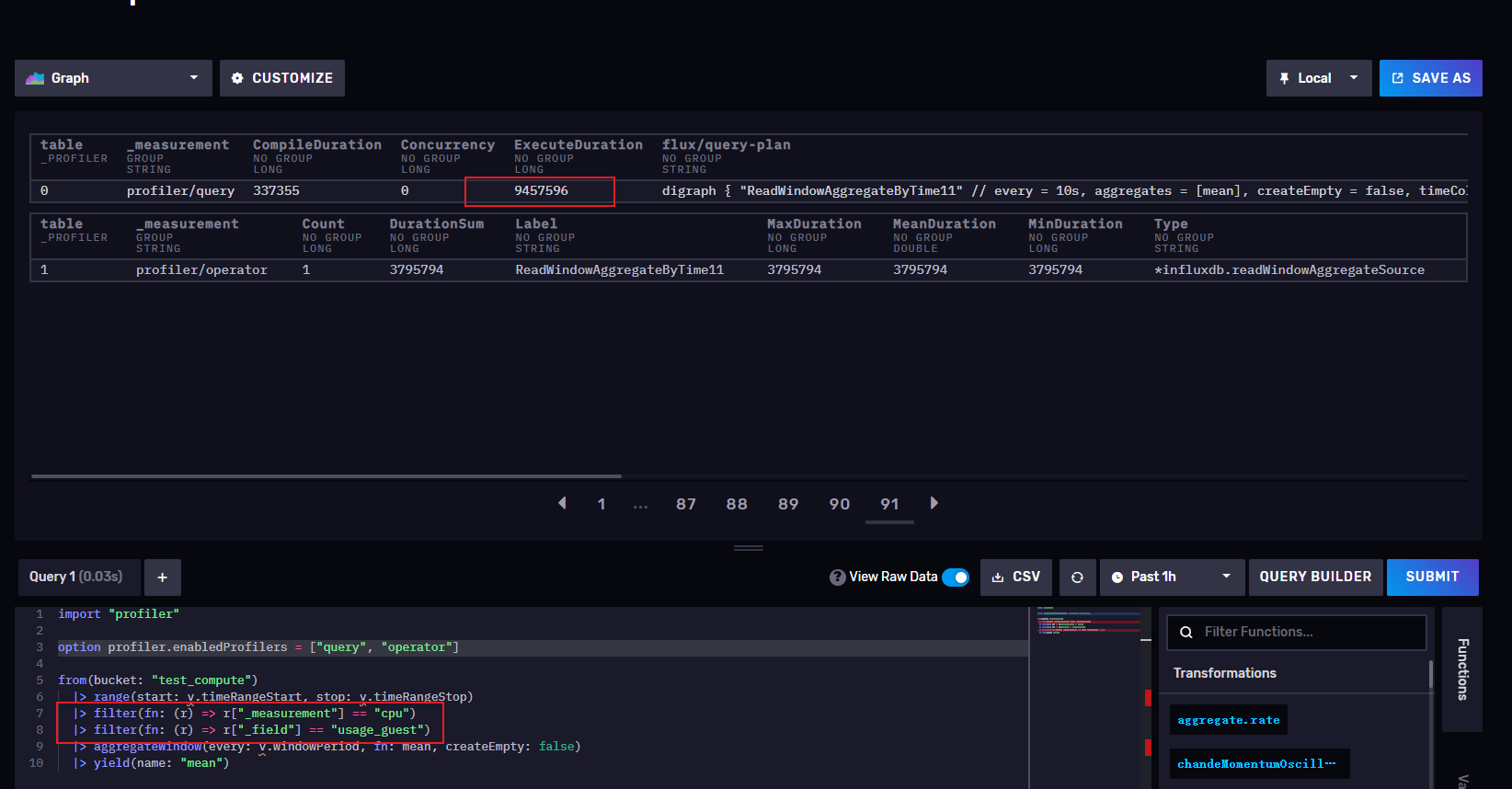
我来区分不通tag查看执行时间
1: 两个filter()->9457596 纳秒 = 0.0094576 秒
2: 三个filter()-380620 纳秒 = 0.00038062 秒
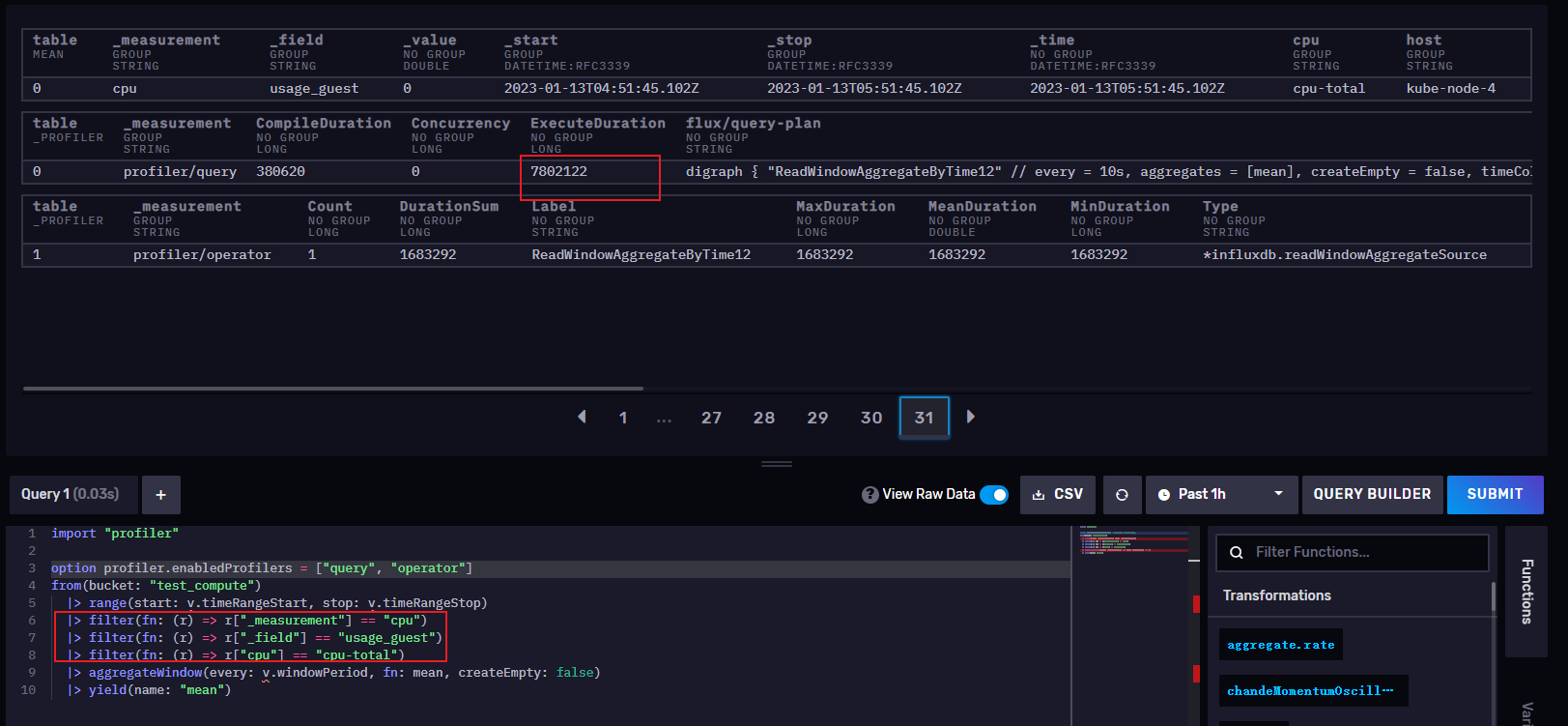
我们可以看到随着filter()不断过滤,查询速度也越来越快
为了更好的理解Influx脚本,我们可以看看下面这站图
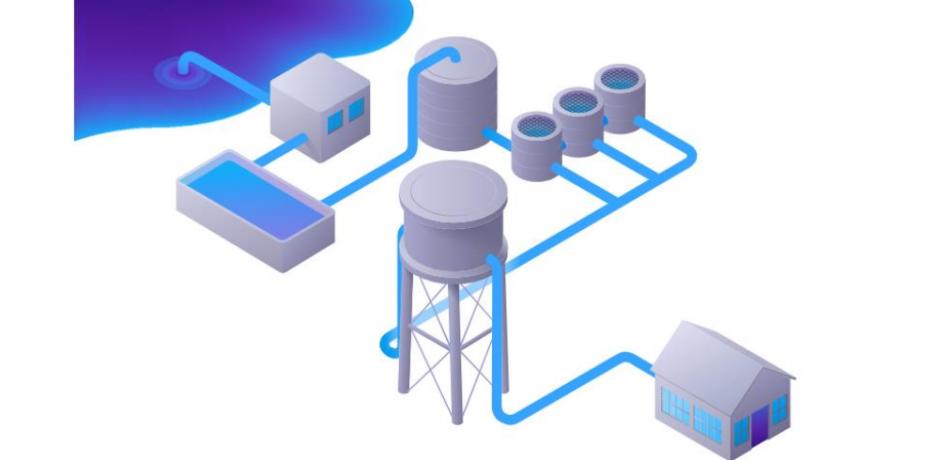
我们从源头把水抽取出来,然后按照我们的用水需求,在管道上进行一系列的处理修改(去除沉积物,净化)等,最终以消耗品的方式输送到我们的目的地,这个就可以解释我们的filter就相当于过滤系统,水流越少,执行的速度就越快,所以我们在工作中尽可能的精确的指定filed
未完待续。。。。。