一文吃透python面向对象基础+进阶
目录
- 基本理论
- 面向过程与面向对象
- 面向过程
- 面向对象
- 基本概念
- 面向对象基本语法
- 定义类
- 创建对象
- 属性
- 属性和变量区别
- 对象属性
- 类属性
- 限制对象属性添加
- 方法
- 实例方法
- 类方法
- 静态方法
- 私有属性
- 只读属性
- 私有方法
- 魔法方法
- 字符串表示
- 可调用
- 索引操作
- 切片操作
- 比较操作
- 布尔判断
- 遍历操作
- 面向对象三大特性
- 封装
- 继承
- 概念
- 单继承和多继承
- `__bases__`
- type和object
- 继承顺序mro
- 继承里的self和cls
- super
- 多态
- 对象生命周期
- 三个阶段
- `__new__`与`__init__`区别
基本理论
面向过程与面向对象
面向过程
面向过程编程更加关注的是“程序的逻辑流程”,是一种“执行者”思维,适合编写小 规模的程序。 面向过程思想思考问题时,我们首先思考“怎么按步骤实现?”并将步骤对应成方法, 一步一步,最终完成。 这个适合简单任务,不需要过多协作的情况下。
优点:将复杂的问题流程化,简单化,程序之间没有复杂的关系
缺点:扩展性和复用性差,维护性差
面向对象
通常利用"类"和"对象"来创建各种模型对真实世界进行描述。
面向过程适合简单、不需要协作的事务。 但是当我们思考比较复杂的问题,比如“如何造车?”,就会有复杂的步骤,是不可能的。那是因为,造车太复杂,需要很多协作才能完成。此时面向对象思想就应运而生了。
面向对象更加关注的是“软件中对象之间的关系”,是一种“设计者”思维,适合编写 大规模的程序。 面向对象(Object)思想更契合人的思维模式。我们首先思考的是“怎么设计这个事物?” 比如思考造车,我们就会先思考“车怎么设计?”,而不是“怎么按步骤造车的问题”。这就是思维方式的转变。
优点:可扩展性高,维护简单
缺点:编程复杂度高
基本概念
类:用来描述具有相同的属性和方法的对象的集合。它定义了该集合中每个对象所共有的属性和方法。对象是类的实例。比如定义一个小狗类,属于所有狗的集合,他们具有相同的属性和方法。
对象:通过类定义的数据结构实例。比如小黄,为一个狗类的具体对象。
属性:类属性和对象属性,用来描述类或对象的变量。
方法:类方法和变量方法,用来描述类或对象功能行为等的方法。
类就像一个模具一样;而对象像是模具做出来的东西;属性相当于对象具有哪些特征,如重量、大小等;方法是对象具有的行为和功能,比如吃、飞行等。
面向对象基本语法
定义类
语法:
class 类名:
pass
使用关键字class来定义一个类,类名使用驼峰规则
下面写一个狗的类,如下:
class Dog:
pass
创建对象
语法:
对象名 = 类名()
如下:
class Dog:
pass
dog1 = Dog()
print(Dog)
print(dog1)
# <class '__main__.Dog'>
# <__main__.Dog object at 0x7f8300093e20>
通过打印出来的dog1的信息可以知道它Dog这个类创建的,也可以通过下面的方法查看:
print(dog1.__class__)
属性
属性和变量区别
1.变量是可以改变的量值,通过引用得到值,属性是描述对象的特征值,跟对象绑定。
2.变量根据不同位置(全局变量,局部变量等)有不同的访问权权限,属性必须通过对象来访问,对象也是通过变量名来引用,对象既然是变量,也有对象的访问权限。
3.变量无宿主,属性有宿主
对象属性
1.初始化对象属性
在python中可以使用__init__方法实现对象的初始化,用来给对象一些属性赋值。此方法第一参数必须是self,代表实例对象本身。
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
p = Person("aaa", 18)
print(p.name)
print(p.age)
2.对象属性操作
class Person:
def __init__(self, name):
self.name = name
p = Person("aaa")
p.name = "cys" # 修改属性
p.age = 20 # 添加属性
print(p.age) # 查看一个属性
p.age = 30 # 修改属性
print(p.age)
print(p.__dict__) # 查看对象的所有属性
del p.age
print(p.age)
# 20
# 30
# {'name': 'cys', 'age': 30}
# AttributeError: 'Person' object has no attribute 'age'
类属性
class Person:
name = "person" # 类中给类添加属性
print(Person.name) # 通过类名.属性查看类属性
p1 = Person()
print(p1.name) # 通过对象查看类属性,如果对象属性有,就使用对象属性,如果对象没有,就会到类属性中找
Person.count = 14 # 增加类属性,不能通过对象增加
print(Person.count)
Person.count = 15 # 修改类属性,不能通过对象修改
print(Person.count)
del Person.name # 删除类属性,不能通过对象删除
print(Person.__dict__)
# person
# person
# 14
# 15
# {'__module__': '__main__', '__dict__': <attribute '__dict__' of 'Person' objects>, '__weakref__': <attribute '__weakref__' of 'Person' objects>, '__doc__': None, 'count': 15}
注意:一般情况下,属性存储在__dict__字典中,有些内置对象没有__dict__这个属性。对象可以直接修改__dict__,但是类的是只读,不可直接修改,可以通过其他方法,如setattr方法修改。
限制对象属性添加
通过以上可以看到,python中对象的属性操作非常灵活,可以任意添加修改,这样造成即使一个类创建出来的对象,还是各不相同。通过__slots__方法可以限制对象可以添加哪些属性:
class Person:
__slots__ = ['name', 'age']
p1 = Person()
p1.name = 'aaa'
print(p1.name)
p1.weight = 100
# AttributeError: 'Person' object has no attribute 'weight'
如上,Person类生成的对象只能有name和age属性,当我们给p1添加weight属性时,报错。
方法
方法有类方法和实例(对象)方法。
实例方法
函数和方法非常类似,但是书写的位置不一样,调用方式也不一样:
# 函数
def eat(food):
print("吃", food)
# 函数直接加括号执行
eat("骨头")
class Dog():
# 属性方法
def eat(self, food): # 第一个必须self参数,代表实例本身
print("吃", food)
print("self:", self)
# 方法必须通对象调用
d1 = Dog()
d1.eat("骨头")
print("d1: ", d1)
# 吃 骨头
# 吃 骨头
# self: <__main__.Dog object at 0x7f975800bee0>
# d1: <__main__.Dog object at 0x7f975800bee0>
实例方法第一个参数必须是self,代表实例本身,可以看到结果d1和self的内存地址相同。在调用实例方法时,并需要传这个参数,解释器或自动把对象传进去。
类方法
使用@classmethod装饰器来定义类方法
class Person:
@classmethod
def walk(cls):
print("走路")
print("cls:", cls)
Person.walk() # 类方法调用
print("Person:", Person)
p1 = Person() # 也可以通过对象调用
p1.walk()
# 走路
# cls: <class '__main__.Person'>
# Person: <class '__main__.Person'>
# 走路
# cls: <class '__main__.Person'>
类方法的第一个参数必须是cls,代表类本身。类方法调用可以直接使用类调用,也可以使用实例对象调用。
静态方法
使用@staticmethod装饰器来定义静态方法
class Person:
@staticmethod
def eat():
print("吃东西")
Person.eat() # 通过类调用
p1 = Person()
p1.eat() # 通过对象调用
静态方法可以不需要任何参数,与类和实例也没有业务上的关系。静态方法可以通过类和实例对象调用。
私有属性
Python并没有真正的私有化支持,但可用下划线得到伪私有。可以有类私有属性和对象私有属性。
私有属性主要是只供一个类或者实例内部使用的变量。这些变量不应当被在类和实例的外部调用。
class Dog:
__leg = 4
def __init__(self, name, weight):
self.name = name
self.__weight = weight
def object_func(self):
print("object_func -- leg:", self.__leg)
print("object_func -- name:", self.name)
print("object_func -- weight:", self.__weight)
@classmethod
def cls_func(cls):
print("cls_func -- leg:", cls.__leg)
d1 = Dog("小黑", 10)
d1.object_func()
Dog.cls_func()
# print(d1.__weight) # AttributeError: 'Dog' object has no attribute '__weight'
# print(Dog.__leg) # AttributeError: type object 'Dog' has no attribute '__leg'
如上示例,在类内部通过cls和self是可以访问私有属性的。但是在类外面,访问报错,说没有这个属性。
其实私有属性在python中只是改了个名字而已,一般是_类名__属性名,还是可以通过这个名字直接访问,但是我们并不提倡这么做,既然是私有,就遵守约定。
class Dog:
__leg = 4
def __init__(self, name, weight):
self.name = name
self.__weight = weight
def object_func(self):
print("object_func -- leg:", self.__leg)
print("object_func -- name:", self.name)
print("object_func -- weight:", self.__weight)
@classmethod
def cls_func(cls):
print("cls_func -- leg:", cls.__leg)
d1 = Dog("小黑", 10)
print(Dog.__dict__)
print(d1.__dict__)
print(Dog._Dog__leg)
print(d1._Dog__weight)
# {'__module__': '__main__', '_Dog__leg': 4, '__init__': <function Dog.__init__ at 0x7f80a81a9e50>, 'object_func': <function Dog.object_func at 0x7f80a82940d0>, 'cls_func': <classmethod object at 0x7f80a8295fd0>, '__dict__': <attribute '__dict__' of 'Dog' objects>, '__weakref__': <attribute '__weakref__' of 'Dog' objects>, '__doc__': None}
# {'name': '小黑', '_Dog__weight': 10}
# 4
# 10
私有属性主要用途是保护这个属性不会被外部直接调用修改,也不能继承(后面会讲解),而是通过内部间接修改这个值,并进行一些数据过滤。
class Dog:
__leg = 4
def __init__(self, name):
self.name = name
self.__age = 1
self.__weight = 10
def set_age(self, age):
if isinstance(age, int) and 0 < age < 100:
self.__age = age
else:
print("年龄有误")
def get_age(self):
return self.__age
def eat(self):
print("吃了一顿饭")
self.__weight += 0.1
d1 = Dog("小黑")
d1.set_age(2)
print(d1.get_age())
d1.set_age(-1)
d1.eat()
print(d1._Dog__weight)
# 2
# 年龄有误
# 吃了一顿饭
# 10.1
如上例子,狗的年龄和体重不能随意修改,我们把年龄和体重设为私有属性,年龄提供两个方法来设置和获取,体重提供一个方法,当狗吃东西时,增加一点体重。
只读属性
python里没有java语言那样可以private修饰直接定义只读属性,但是可以通过其他方法:
1.property
@property装饰器的主要作用是把方法变为可以像属性一样操作
通过私有属性+property可以实现私有属性的功能
class Dog:
def __init__(self, name):
self.name = name
self.__age = 1
@property
def age(self):
return self.__age
d1 = Dog("小黑")
print(d1.age) # 1
d1.age = 10 # AttributeError: can't set attribute
property高级用法:设置一个属性
class Dog:
def __init__(self, name):
self.name = name
self.__age = 1
def get_age(self):
return self.__age
def set_age(self, value):
self.__age = value
def del_age(self):
del self.__age
# 通过property设置一个属性
age = property(get_age, set_age, del_age)
d1 = Dog("小黑")
print(d1.age) # 1
d1.age = 10
del d1.age
也可以通过装饰器的形式
class Dog:
def __init__(self, name):
self.name = name
self.__age = 1
@property
def age(self):
print("I am the 'age' property")
return self.__age
@age.setter
def age(self, value):
self.__age = value
@age.deleter
def age(self):
del self.__age
d1 = Dog("小黑")
print(d1.age)
d1.age = 10
del d1.age
2.setattr
通过__setattr__来限制属性增加。当使用对象.属性这种方式增加或修改属性时,就会调用这个方法,然后把对应的数据存储到__dict__里。
class Person:
def __setattr__(self, key, value):
print("%s:%s"%(key, value))
if key == "age" and key not in self.__dict__.keys():
print("只读属性不可修改")
else:
self.__dict__[key] == value
p1 = Person()
p1.age = 10
print(p1.age)
p1.age = 20
# age:10
# 只读属性不可修改
# AttributeError: 'Person' object has no attribute 'age'
私有方法
与私有属性类似,一般在方法前加双下划线,表示这个方法不能在外部调用。
class Pserson:
__age = 1
def __run(self):
print("run")
p = Pserson()
# p.__run() # AttributeError: 'Pserson' object has no attribute '__run'
print(Pserson.__dict__)
# {'__module__': '__main__', '_Pserson__age': 1, '_Pserson__run': <function Pserson.__run at 0x7fa1900a18b0>, '__dict__': <attribute '__dict__' of 'Pserson' objects>, '__weakref__': <attribute '__weakref__' of 'Pserson' objects>, '__doc__': None}
可以看到,私有方法内部内部名字也修改了,和私有属性类似。
魔法方法
魔法方法是python内置方法,不需要主动调用,存在的目的是为了给python的解释器进行调用,几乎每个魔法方法都有一个对应的内置函数,或者运算符,当我们对这个对象使用这些函数或者运算符时就会调用类中的对应魔法方法。一般是__方法__这种格式。
下面介绍下常用的一些魔法函数
字符串表示
__str__和__repr__
__str__和__repr__都可以用来修改对象的展现形式,比如我们的print,重写方法,可以自定义打印的格式和输出。
区别在于,__str__是面向用户的,而__repr__是面向开发者的。函数触发不相同,__str__是使用print函数或str函数时触发,而__repr__是在终端输出或repr函数时触发。但是两者都存在的时候,__str__方法会覆盖__repr__。
>>> class Person:
def __init__(self, name):
self.name = name
self.__age = 20
def __repr__(self):
return "--repr"
def __str__(self):
return "--str"
>>> p = Person("张三")
>>> p
--repr
>>> print(p)
--str
>>> str(p)
'--str'
>>> repr(p)
'--repr'
再看一个例子
>>> import datetime
>>> d = datetime.datetime.now()
>>> str(d)
'2020-04-04 20:47:46.525245'
>>> repr(d)
'datetime.datetime(2020, 4, 4, 20, 47, 46, 525245)'
可以看出repr()更能显示出对象的类型、值等信息,对象描述清晰的。
在 str() 函数被使用,或是在用 print 函数打印一个对象的时候才被调用的,并且它返回的字符串对终端用户更友好。
可调用
__call__方法使对象可以被调用(callable),就像函数对象一样。
class Person:
pass
p = Person()
p()
# peError: 'Person' object is not callable
下面实现__call__方法:
class Person:
pass
def __call__(self, *args, **kwargs):
print("I am callable!")
p = Person()
p()
# I am callable!
__call__方法使用场景很多,比如实现类装饰器,像flask wtforms的验证器等。
实现类装饰器:
class Counter:
def __init__(self, func):
self.func = func
self.count = 0
def __call__(self, *args, **kwargs):
self.count += 1
self.func(*args, **kwargs)
print(f"count:{self.count}")
@Counter
def walk():
print("走一步")
for i in range(5):
walk()
自定义一个简单的验证器
class MyValidator(object):
def __call__(self, value):
if 0 < value < 200:
print("年龄正确")
else:
print("年龄错误")
v = MyValidator()
v(20)
v(1000)
索引操作
如果想对一个实例对象像字典一样进行索引操作,可以使用一下三个魔法方法:
__setitem__:设置元素
__getitem__:获取元素
__delitem__:删除元素
class MyClass:
def __init__(self):
self.my_index = {}
ef __setitem__(self, key, value):
self.my_index[key] = value
def __getitem__(self, item):
return self.my_index[item]
def __delitem__(self, key):
del self.my_index[key]
c = MyClass()
c["name"] = "aaa"
print(c["name"])
del c["name"]
切片操作
像列表一样可以进行切片,也是使用__setitem__、__getitem__、__delitem__三个方法,分别是索引赋值、索引切片、删除索引元素
class MyClass:
def __init__(self):
self.my_index = [1, 2, 3, 5]
def __str__(self):
return str(self.my_index)
def __setitem__(self, key, value):
print("Set self[key] to value")
self.my_index[key] = value
def __getitem__(self, item):
print("x.__getitem__(y) <==> x[y]")
return self.my_index[item]
def __delitem__(self, key):
print("Delete self[key]")
del self.my_index[key]
c = MyClass()
c[1] = 1
print(c[:2])
del c[1]
print(c)
# Set self[key] to value
# x.__getitem__(y) <==> x[y]
# [1, 1]
# Delete self[key]
# [1, 3, 5]
比较操作
比较操作包括以下:
__lt__ # 小于
__le__ # 小于等于
__eq__ # 等于
__ne__ # 不等于
__gt__ # 大于
__ge__ # 大于等于
通过重写以上方法,可以自定义对象的比较规则:
class Myoperator:
def __init__(self, age):
self.age = age
def __lt__(self, other):
return self.age < other.age
def __le__(self, other):
return self.age <= other.age
def __eq__(self, other):
return self.age == other.age
def __ne__(self, other):
return self.age != other.age
def __gt__(self, other):
return self.age > other.age
def __ge__(self, other):
return self.age >= other.age
c1 = Myoperator(10)
c2 = Myoperator(20)
print(c1 < c2) # True
print(c1 == c2) # False
print(c1 > c2) # False
print(c1 <= c2) # True
注意:如果我们大于和小于或等于和不等于只写了一个,做反向比较时,会自动找到另一个。比如只实现了小于,但是我比较对象用的大于号,解释器会自动找到小于运算符,并调换两个对象作比较。但是对于小于等于这种并不会。
布尔判断
我们经常使用if做布尔判断,通过实现__bool__方法,就可以自定义我们的判断规则:
class MyClass:
def __init__(self, name):
self.name = name
def __bool__(self):
if self.name:
return True
return False
c1 = MyClass("")
if c1:
print("c1 True")
else:
print("c1 False")
c2 = MyClass("aaa")
if c2:
print("c2 True")
else:
print("c2 False")
# c1 False
# c2 True
遍历操作
如何是对象可以想列表一样使用for循环遍历?有两种方法:实现__getiterm__方法或实现为迭代器
1.__getiterm__
class MyLoop:
def __init__(self, stop):
self.stop = stop
self.num = 0
def __getitem__(self, item):
self.num += 1
if self.num > self.stop:
raise StopIteration("遍历结束")
return self.num
my_loop = MyLoop(5)
for i in my_loop:
print(i)
# 1
# 2
# 3
# 4
# 5
当使用for循环遍历对象时,就会取找__getiterm__方法取值,直到遇到异常停止。注意for循环会自动为我们捕捉到StopIteration异常而停止循环。
2.迭代器
其实当我们for循环遍历对象时,会优先找__iter__方法,当找不到时,才会去找__getiterm__方法。使用__iter__方法时还不能完成我们的遍历操作。这就要说到我们的迭代器和可迭代对象区别了。
让我们回忆下:可迭代对象只要实现__iter__方法就可以,迭代器必须实现__iter__方法和__next__方法。要想完成我们的for循环遍历,必须要是迭代器,所以两个方法都要有才行。其中__iter__用来生成一个迭代器,可返回自身,因为自身就是一个迭代器。
class MyLoop:
def __init__(self, stop):
self.stop = stop
self.num = 0
def __iter__(self):
return self
def __next__(self):
self.num += 1
if self.num > self.stop:
raise StopIteration("遍历结束")
return self.num
my_loop = MyLoop(5)
for i in my_loop:
print(i)
from collections import Iterable, Iterable
print(isinstance(my_loop, Iterable)) # True
print(isinstance(my_loop, Iterable)) # True
# 1
# 2
# 3
# 4
# 5
面向对象三大特性
封装
封装就是把一类事物封装到一起实现一些特定的功能,使用者只要在乎如何使用,而不用在乎里面的细节。比如我们的电脑,电脑产商把电脑组装成一个整体,我们只需要直到如何使用,不用直到内部零件细节。
好处:
- 使用方便,省去许多细节取了解
- 保证了数据安全,内部设置私有属性,数据拦截等
- 代码维护简单
继承
概念
程序中的继承 指的是一个类继承了另一个类,被继承的叫父类,继承的叫子类。子类继承父类,子类就拥有了父类的属性和方法。注意这里的拥有并不是资源的复制,而是资源的使用权,还得是非私有的才能继承。
好处:
提高代码的复用性和可扩展性,在定义不同类的时候存在一些相同属性,为了方便使用可以将这些共同属性抽象成一个父类,在定义其他子类时可以继承自该父类,减少代码的重复定义,子类可以使用父类中非私有的成员。
单继承和多继承
分为单继承和多继承
1.单继承
只继承一个父类,如下,狗继承动物类,就会拥有动物的一些属性和行为
class Animal:
pass
class Dog(Animal):
pass
2.多继承
继承多个父类,如下,狗继承脊椎动物和哺乳动物,就会拥有两个父类的属性和方法:
class Vertebrate:
pass
class MammalM:
pass
class Dog(Vertebrate, MammalM):
pass
__bases__
查看继承了哪些父类
class Vertebrate:
name = "脊椎动物"
class MammalM:
name = "哺乳动物"
class Dog(Vertebrate, MammalM):
name = "狗"
print(Dog.__bases__)
print(Vertebrate.__bases__)
# (<class '__main__.Vertebrate'>, <class '__main__.MammalM'>)
# (<class 'object'>,)
Vertebrate我们命名没有指定父类,却有个object父类,在python3中会自动继承这个类。
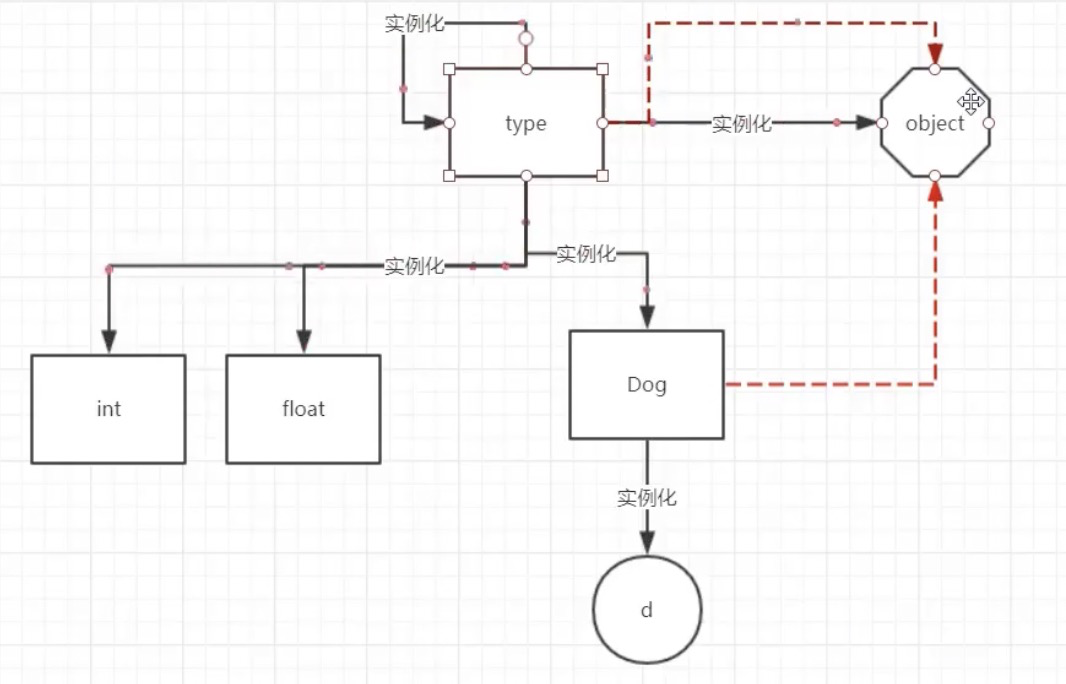
type和object
上面我们直到了python3中所有类都默认继承了object,我们直到python中一切皆对象,类也是对象,查看类对象时哪个类实例化的可以使用__class__。
看下面这个例子
class Dog:
pass
# 查看Dog的父类
print(Dog.__bases__) # (<class 'object'>,)
# 内置类型的父类
print(int.__bases__) # (<class 'object'>,)
print(str.__bases__) # (<class 'object'>,)
print(bool.__bases__) # (<class 'int'>,)
# 查看object的父类
print(object.__bases__) # ()
d = Dog()
# 查看d对象的类
print(d.__class__) # <class '__main__.Dog'>
# 查看Dog类对象的类
print(Dog.__class__) # <class 'type'>
# 内置类型对象的类
print(int.__class__) # <class 'type'>
# type对象的类
print(type.__class__) # <class 'type'>
示意如图下:
继承顺序mro
继承有单继承和多继承,而多继承的情况又很复杂,我们知道子类可以继承父类的变量和方法,但是多继承里面又是如何继承的呢?
1.单继承
# 单继承的资源关系
class C:
name = "c"
class B(C):
name = "b"
class A(B):
name = "a"
print(A.name) # a
我们可以看到,A自己有name属性,就会找到自己的。
当A没有,就找A的父类,及B:
# 单继承的资源关系
class C:
name = "c"
class B(C):
name = "b"
class A(B):
# name = "a"
pass
print(A.name) # b
如果B还没有,再找B的父类,即C:
# 单继承的资源关系
class C:
name = "c"
class B(C):
# name = "b"
pass
class A(B):
# name = "a"
pass
print(A.name) # c
如果c还没有,就会抛出错误:
# 单继承的资源关系
class C:
# name = "c"
pass
class B(C):
# name = "b"
pass
class A(B):
# name = "a"
pass
print(A.name)
# AttributeError: type object 'A' has no attribute 'name'
我们可以使用mro查询继承关系:
# 单继承的资源关系
class C:
name = "c"
class B(C):
name = "b"
class A(B):
name = "a"
print(A.mro())
# [<class '__main__.A'>, <class '__main__.B'>, <class '__main__.C'>, <class 'object'>]
查询的继承关系就是我们在使用变量或方法时,寻找的顺序,其中object是新式类中默认继承的类。
再看下复杂的例子:
多继承的时候
class E:
name = "e"
class D:
name = "d"
class C(E):
name = "c"
class B(D):
name = "b"
class A(B, C):
name = "a"
print(A.mro())
# [<class '__main__.A'>, <class '__main__.B'>, <class '__main__.D'>, <class '__main__.C'>, <class '__main__.E'>, <class 'object'>]
特殊的菱形继承:
class D:
pass
class B(D):
pass
class C(D):
pass
class A(B, C):
pass
print(A.mro())
# [<class '__main__.A'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.D'>, <class 'object'>]
继承顺序算法的历史(了解):
python2.2之前:使用的mro深度优先算法,存在的问题:在有重叠的多继承中,违背重写可用原则。
python2.2:改进了mro算法,在深度优先的基础上,优化了一部分,如果产生重复元素, 会保留最后一个,并且, 更尊重基类出现的先后顺序。但是无法解决有问题的继承。
pyhon2.3 - 2.7:引入了新式类,及所有的类默认继承了object。新式类使用C3算法解决继承问题,注意C3算法并不等于广度优先算法。
Python3.x后:只有新式类了,使用C3算法。
继承里的self和cls
在我们使用写对象和类方法时,或有个默认参数self和cls,代表对象和类本身。但是在有继承的情况下,self和cls分别代表不同的对象和类。
我们先来看下self
class C:
def __init__(self, name):
print("In C -- ", self)
self.name = name
@classmethod
def say(cls):
print("I am ", cls)
class B(C):
def __init__(self, name):
print("In B -- ", self)
self.name = name
@classmethod
def say(cls):
print("I am ", cls)
class A(B):
def __init__(self, name):
print("In A -- ", self)
self.name = name
@classmethod
def say(cls):
print("I am ", cls)
a = A("a")
# 输出
# In A -- <__main__.A object at 0x7f840012d940>
当A有__init__方法时,实例化调用的是A类的方法,self就是A的实例化对象。
class C:
def __init__(self, name):
print("In C -- ", self)
self.name = name
@classmethod
def say(cls):
print("I am ", cls)
class B(C):
def __init__(self, name):
print("In B -- ", self)
self.name = name
@classmethod
def say(cls):
print("I am ", cls)
class A(B):
# def __init__(self, name):
# print("In A -- ", self)
# self.name = name
@classmethod
def say(cls):
print("I am ", cls)
a = A("a")
# 输出
# In B -- <__main__.A object at 0x7f879010d970>
当A没有__init__方法时,会去找B类的__init__方法,此时,虽然在B类里,但是self仍然是A的实例化对象。
同理,如果B类也没有__init__方法时,就会使用C类__init__方法,self仍然是A的实例化对象。
再来看下cls:
class C:
def __init__(self, name):
print("In C -- ", self)
self.name = name
@classmethod
def say(cls):
print("In C -- ", cls)
class B(C):
def __init__(self, name):
print("In B -- ", self)
self.name = name
@classmethod
def say(cls):
print("In B -- ", cls)
class A(B):
def __init__(self, name):
print("In A -- ", self)
self.name = name
@classmethod
def say(cls):
print("In A -- ", cls)
A.say()
# 输出
# In A -- <class '__main__.A'>
使用A调用say方法,cls是A类。
class C:
def __init__(self, name):
print("In C -- ", self)
self.name = name
@classmethod
def say(cls):
print("In C -- ", cls)
class B(C):
def __init__(self, name):
print("In B -- ", self)
self.name = name
# @classmethod
# def say(cls):
# print("In B -- ", cls)
class A(B):
def __init__(self, name):
print("In A -- ", self)
self.name = name
# @classmethod
# def say(cls):
# print("In A -- ", cls)
A.say()
# 输出
# In C -- <class '__main__.A'>
当A和B都没有say方法,则找到了C的say方法,此时,cls还是A类。
总结:不管self和cls写在哪个类里,谁调用就是谁。
super
在继承里的调用,子类没有会自动朝上找父类的,有就不会自动找,如果子类有自己的还想用父类的,就在子类里写上super方法,则沿着mro链找父类的。
super(type[, object-or-type])
第一种用法:
super(type, object)
type表示一个类,object是一个对象。上面的super就是:
- 获取object对象所属的类的mro列表
- 从type类开始,不包含type类,开始往后找当前调用super的方法
- 找到后,就把找到的方法绑定到self对象并返回
如下例子:
class C:
def __init__(self):
print("C")
class B(C):
def __init__(self):
print("B")
class A(B, C):
def __init__(self, name):
print("A")
self.name = name
super(A, self).__init__()
a = A("a")
print(A.mro())
# 输出
# A
# B
# [<class '__main__.A'>, <class '__main__.B'>, <class '__main__.C'>, <class 'object'>]
如果我想从B类后面开始找:
class C:
def __init__(self):
print("C")
class B(C):
def __init__(self):
print("B")
class A(B, C):
def __init__(self, name):
print("A")
self.name = name
super(B, self).__init__()
a = A("a")
print(A.mro())
# 输出
# A
# C
# [<class '__main__.A'>, <class '__main__.B'>, <class '__main__.C'>, <class 'object'>]
一般我们使用时,type都是当前类,object都是self,表示当前类的对象。
注意:在python3里,super(A, self).__int__()写法等同于super().__int__():
class A(B, C):
def __init__(self, name):
print("A")
self.name = name
super().__init__()
第二种用法:
super(type, type2)
type表示一个类,type2是另一个类。上面的super就是:
- 获取type2这个类的mro
- 从mro中type开始,不包含type类,依次寻找方法
- 一旦找到,就返回非绑定的方法
这种用法比较少,了解即可。
多态
通俗的讲,就是同一个类或方法表现出多种状态。静态的多态就是类的不同形态,比如动物,可以是猫和狗,就是两种不同的形态。动态的多态就是同一个方法,不同对象可以表现不同,比如猫和狗都会叫,但是叫的声音不一样。
在python中,是天生具有多态的特点。在python中,有个鸭子类型的概念,即当看到一只鸟走起来像鸭子、游泳起来像鸭子、叫起来也像鸭子,那么这只鸟就可以被称为鸭子。当我们使用时,不用关心这个类实际是什么类,可以直接当成鸭子来使用。
class Dog:
def jiao(self):
print("汪汪汪")
class Cat:
def jiao(self):
print("喵喵喵")
dog = Dog()
cat = Cat()
def test(obj):
obj.jiao()
test(dog)
test(cat)
对象生命周期
三个阶段
1.__new__
用于创建一个对象
class Person:
def __new__(cls, *args, **kwargs):
print("new---")
p = Person()
print("p:", p)
# new---
# p: None
上面自定义了__new__方法,拦截了对象创建,所以p是None。
2.__init__
用于初始化一个对象。
class Person:
def __init__(self):
print("init---")
p = Person()
print("p:", p)
# init---
# p: <__main__.Person object at 0x7fb37002ce20>
当我们使用class()创建一个对象时,就会自动跳动__new__方法,接着调用__init__方法来初始化对象。
3.__del__
用于回收一个对象
class Person:
# def __new__(cls, *args, **kwargs):
# print("new---")
def __init__(self):
print("init---")
def __del__(self):
print("del---")
p = Person()
print("p:", p)
del p
# init---
# p: <__main__.Person object at 0x7ff84002ce20>
# del---
__new__与__init__区别
1.__new__是在实例创建之前被调用的,返回实例对象,是个静态方法,类级别的方法;__init__当实例对象创建完成后被调用的,设置对象属性的初始值,无返回值,是一个实例方法。
2.__new__至少要有一个参数cls,代表当前类,此参数在实例化时由Python解释器自动识别;__init__有一个参数self,就是这个__new__返回的实例。
3.如果__new__创建的是当前类的实例,会自动调用__init__函数,如果是其他类的类名,那么实际创建返回的就是其他类的实例,不会调用当前类的__init__函数,也不会调用其他类的__init__函数。
__new__除非继承不可变类型(如str,int,unicode或tuple),否则不必重写。主要是当你继承一些不可变的class时(比如int, str, tuple), 提供给你一个自定义这些类的实例化过程的途径。还有就是实现自定义的metaclass。