存储与数据库 | 字节青训营笔记
目录
一、存储系统
1、什么是存储系统
2、存储系统的特点
3、RAID技术
RAID出现的背景
RAID 0
RAID 1
RAID 0+1
二、数据库
1、难道数据库和存储系统不一样吗
2、数据库vs经典存储
三、主流产品剖析
1、单机存储
本地文件系统
key-value存储
2、分布式存储系统
分布式文件系统
分布式对象存储
3、单机数据库
关系型数据库
非关系型数据库
4、分布式数据库
解决容量问题
解决弹性问题
解决性价比问题
总结
一、存储系统
1、什么是存储系统
一个提供了读写、控制类接口,能够安全有效的把数据持久化的软件,就可以称为存储系统
2、存储系统的特点
- 作为后端软件的底座,对性能极其敏感
- 存储系统软件架构,容易受硬件影响(只要硬件发生变革,软件的代码可能也会改变)
- 存储系统的代码,既简单(要代码要简单不然性能差),又复杂(要考虑到各种情况,防止出问题,要考虑到各种硬件是否会坏什么的)
3、RAID技术
单机存储系统怎么做到高性能/高性价比/高可靠性?
RAID出现的背景
- 单块大容量磁盘的价格>多块小容量磁盘
- 单块磁盘的写入性能<多块磁盘的并发写入性能
- 单块磁盘的容错能力有限,不够安全
RAID 0
多块磁盘简单组合,数据条代话存储,提高磁盘带宽,没有额外的容错设计。(比如把一块私盘分为两个,存储1000mb的文件分为两个500的分别存到第一快的1位置和第二块的1位置,这样分开存入,速度肯定是增加了)
RAID 1
一块磁盘对应一块而外的磁盘镜像,真实的空间利用率只有百分之50,容错能力强(分两块,一块存数据,另一个存镜像,复制一样的)
RAID 0+1
这种就是结合了上面两种情况,把0的高性能和1的容错率结合,真实存储还是百分之50为了存镜像,但是用了0的分开写,性能快了。
二、数据库
1、难道数据库和存储系统不一样吗
数据库分为 关系型数据库 和 非关系型数据库
关系数据库是存储系统,但是存储之外,又发展出其他能力(结构化数据友好,支持事务,支持复杂的查询语言)
非关系型数据库也是存储系统,但是一般不要求严格的结构化,半结构化数据友好,可能支持事务,可能支持复杂查询语句
2、数据库vs经典存储
数据库支持结构化数据管理

数据库支持事务

数据库支持复杂的查询

三、主流产品剖析
1、单机存储
单机存储系统就是单个计算机节点上的存储软件系统,一般不实际网络交互
本地文件系统
linux的哲学就是一切皆文件,所以文件系统的管理单元就是文件。
key-value存储
世间一切皆key-value,key可以是你的身份证,value是你的内涵
常见的使用方式:put & get
2、分布式存储系统
分布式存储=单机存储的基础上实现了分布式协议,涉及大量网络交互
分布式文件系统
HDFS:堪称大数据时代的基石
当时时代背景,专用的高级硬件很贵,同时数据存量很大,要求超高吞吐,于是就想说要很多海量的便宜的硬件堆起来实现,支持海量存储,吞吐量大,而且因为硬件都是很多便宜的组成,容易坏,所以要求高容错性,极高的性价比
分布式对象存储
Geph:开源的分布式存储系统的万金油
特点:一套系统支持对象接口、快接口、文件接口、但是一切皆对象。数据写入采用主备复制模型,数据布模型采用CRUSH算法(一份数据为了保证可靠性分为很多副本,分布到哪里通过分布算法实现)
3、单机数据库
单机数据库是单个计算机节点上的数据存储系统,事务在单机内执行,也可能通过网络交互实现分布式事务
关系型数据库
Oracle和MySQL
非关系型数据库
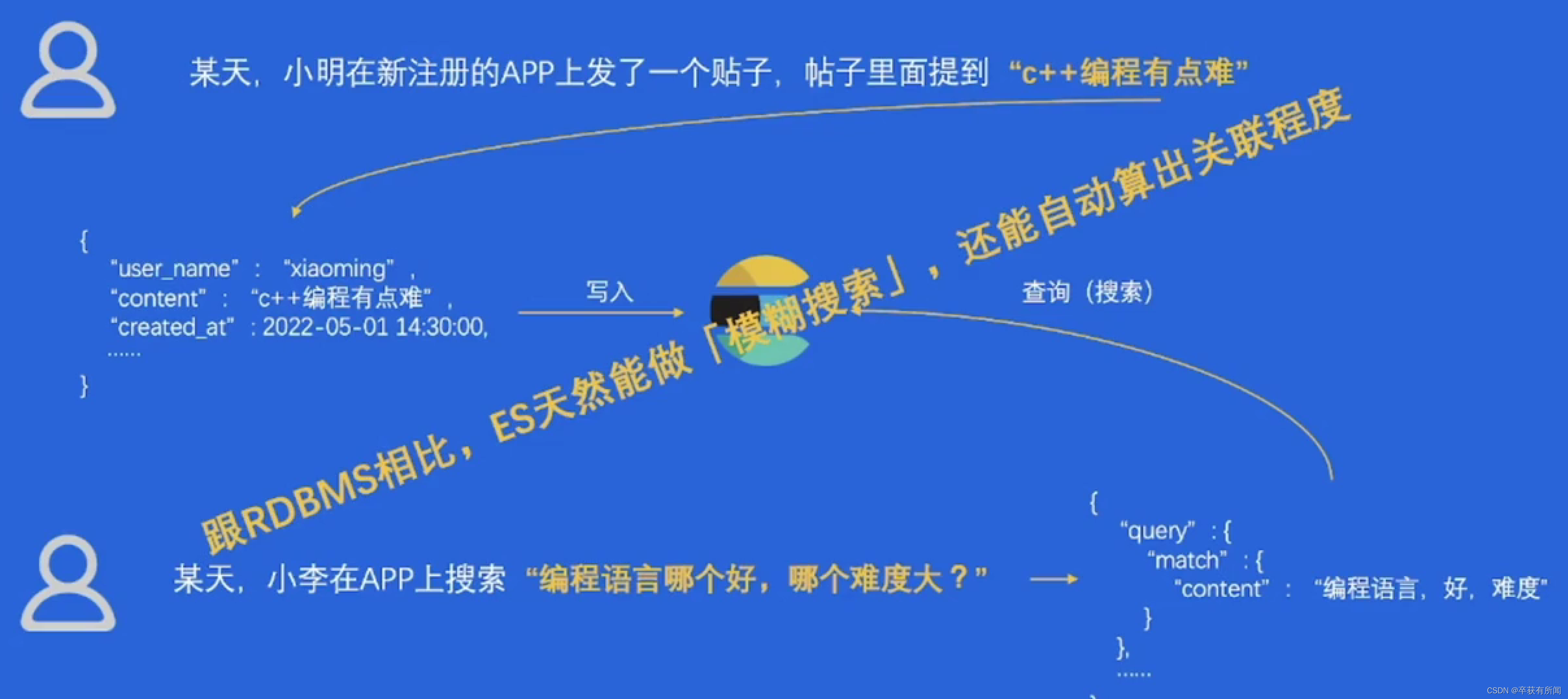
MongoDB、redis、elasticsearch三足鼎立
交互方式各不相同,schema相对灵活,都在想办法支持sql子集和事务
elasticsearch是基于文档来存储,可以序列化为json,支持嵌套,实现了大量搜索数据结构和算法,支持restful api也支持弱sql交互
mongoDB面向文档存储,可以序列化json和bason支持嵌套,4.0后也开始支持事务,也可以通过插件支持弱sql
redis数据结构非常丰富,纯c实现,超高性能,主要基于内存,但支持aof和rdb两种方式来持久化,redis-cli多语言sdk交互
4、分布式数据库
单机数据库遇到了什么问题?这么好了为什么还要卷到分布式架构?
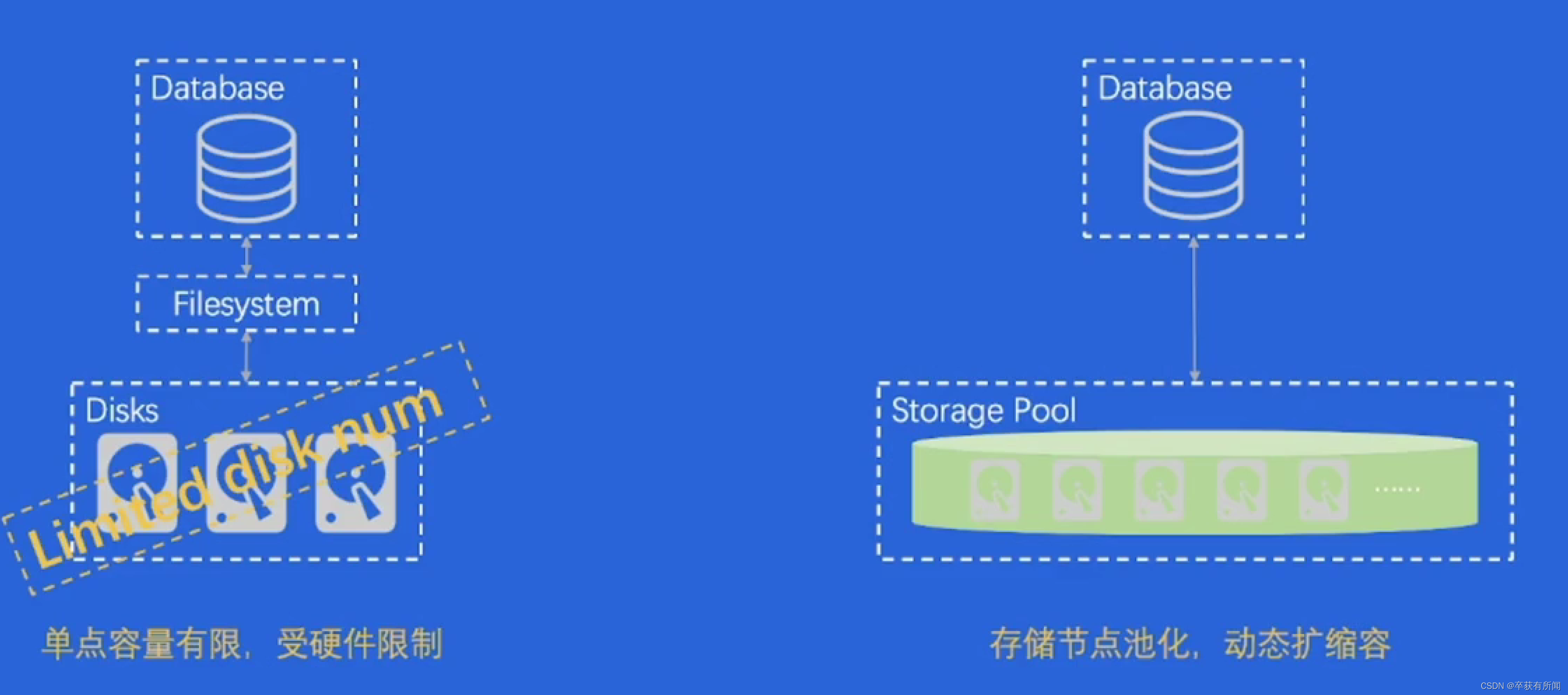
解决容量问题
单点容量有限,受硬件限制,我们把存储节点池化,不够的话就的动态扩容增加节点
解决弹性问题
当用户原本服务的数据库不够用了,不如一个服务突然火爆,那么肯定得换更好的机器来带,更大的内存cpu和数据库,数据库的扩容更换是要很长时间的,然后等一段时间又没人了,系统又要换回小容量数据库cpu这些,换来换去就很慢,为了解决这种弹性问题,也可以用上面这种池化技术。
解决性价比问题
有可能我们只要分配数据库容量增加,并不需要增加cpu和内存,分多了cpu过剩就会导致性价比低,那么我们也可以用这种池化的技术,不用分配cpu可以不变内存可以因为池化动态扩容的,不会因为配置更多的容量而要更好的cpu。
不仅如此,我们还要解决更难的
多写问题、从磁盘弹性改到内存弹性、分布式事务优化
总结
在存储和数据库的领域,硬件反推软件变革十分常见!