【Golang开发面经】得物(两轮技术面)
文章目录
- 写在前面
- 笔试
- 一面
- 你用过gorm?那我直接用sql不也可以吗?为什么用gorm?
- 你用过哪些锁?
- 那map是线程安全的吗?为什么?
- chan呢?
- 对一个关闭的chan读写会怎么样?
- 算法:一道回溯的题目,不太记得了
- 二面
- redis 用过吧?你知道redis有多少种高可靠集群的模型?
- redis 支持事务吗?
- mysql 的隔离等级?
- 最左匹配原则是什么?
- 我能在性别这个字段上面建索引吗?为什么?
- go 里面 context 是怎么用的?
- rabbitmq 是如何保证消息不丢失的?
- 发送方确认模式
- 接收方确认机制
- 9个球,外观一样,但有一个球是重一点,怎么快速找到这个特殊的球?
写在前面
得物一顿面试下来感觉还行吧,挺注重基础的,面试官水平也很高。就是聊的挺开心的。
笔试
略
一面
聊项目。大概20分钟吧,如何优化之类的。。
还有一些我不太记得了。。。太久远了。。。
你用过gorm?那我直接用sql不也可以吗?为什么用gorm?
用 sql 是可以,但是会有sql注入的风险,而gorm是通过占位符的形式来一定程度减少了sql的注入。
你用过哪些锁?
用过读写锁 sync 包下的排斥锁或是读写锁,这两种锁。
一般在出现数据竞争的情况下使用的。
那map是线程安全的吗?为什么?
不是的,map 会发生数据竞争,因为底层结构中 map 是没有锁的支持的。
chan呢?
chan的底层是有锁结构,所以是线程安全的。
对一个关闭的chan读写会怎么样?
对一个关闭的chan进行读:
- 如果chan里面还有值,那么就读出chan里面的东西
- 如果chan里面没有值了,就会读出这个chan类型的零值。
对一个关闭的chan进行写:
- 直接panic
算法:一道回溯的题目,不太记得了
二面
我不太记得了。。。太久远了。。。
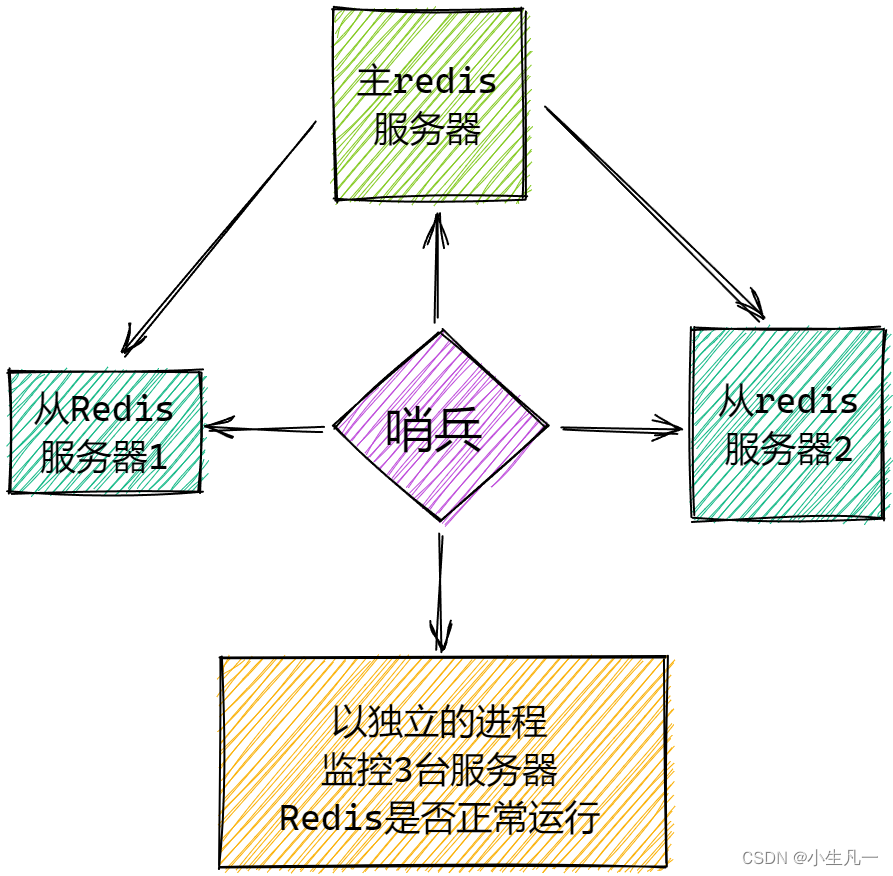
redis 用过吧?你知道redis有多少种高可靠集群的模型?
我目前了解到的是redis的哨兵模式。
哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它独立运行。 其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例。
redis 支持事务吗?
不支持,redis不支持原子性,只是支持最终一致性。
mysql 的隔离等级?
- 未提交读(READ UNCOMMITTED):
READ UNCOMMITTED提供了事务之间最小限度的隔离。除了容易产生虚幻的读操作和不能重复的读操作外,处于这个隔离级的事务可以读到其他事务还没有提交的数据,如果这个事务使用其他事务不提交的变化作为计算的基础,然后那些未提交的变化被它们的父事务撤销,这就导致了大量的数据变化。 - 提交读(READ COMMITTED):READ COMMITTED 隔离级别的安全性比 REPEATABLE READ 隔离级别的安全性要差。处于 READ COMMITTED 级别的事务可以看到其他事务对数据的修改。也就是说,在事务处理期间,如果其他事务修改了相应的表,那么同一个事务的多个 SELECT 语句可能返回不同的结果。
- 可重复读(REPEATABLE READ):在可重复读在这一隔离级别上,事务不会被看成是一个序列。不过,当前正在执行事务的变化仍然不能被外部看到,也就是说,
如果用户在另外一个事务中执行同条 SELECT 语句数次,结果总是相同的。(因为正在执行的事务所产生的数据变化不能被外部看到)。 - 序列化(SERIALIZABLE):如果隔离级别为序列化,则用户之间通过一个接一个顺序地执行当前的事务,
这种隔离级别提供了事务之间最大限度的隔离。
最左匹配原则是什么?
索引的底层是一颗B+树,构建一颗B+树只能根据一个值来构建。此处的索引当然也包括联合索引,当索引类型为联合索引时,数据库会依据联合索引最左的字段来构建B+树,也叫最左匹配原则。
最左匹配原则:最左优先,以最左边的为起点任何连续的索引都能匹配上。 同时遇到范围查询(>、<、between、like)就会停止匹配。
我能在性别这个字段上面建索引吗?为什么?
关于区分度不高的字段,比如性别,比如状态字段,不应该建索引。索引并不是建了就快,唯一性太差的字段不需要创建索引,只有2种取值的字段,建了索引数据库也不一定会用,只会白白增加索引维护的额外开销。因为索引也是需要存储的,所以插入和更新的写入操作,同时需要插入和更新你这个字段的索引的。
我们也可以从索引的选择性这方面去说:索引的选择性是指索引列中不同值的数目和表的记录数的比值。 假如表里面有 1000 条数据,表索引列有 980 个不同的值,这时候索引的选择性就是 980/1000=0.98 。索引的选择性越接近 1,这个索引的效率很高。
性别可以认为是3种,男,女,其他。如果创建索引,查询语句 性别=‘男’的数据,索引的选择性就是3/1000=0.003。索引的选择性值很低,对查询提升不大,所以性别建索引意义不大。
go 里面 context 是怎么用的?
context 一般我们用来传递上下文信息,在go中,理解为goroutine的运行状态、现场,存在上下层goroutine context的传递,上层goroutine会把context传递给下层goroutine。
rabbitmq 是如何保证消息不丢失的?
发送方确认模式
将信道设置成confirm模式(发送方确认模式),则所有在信道上发布的消息都会被指派一个唯一ID。一旦消息被投递到目的队列后,或者消息被写入磁盘后,信道会发送一个确认给生产者(包括消息的ID)。
如果RabbitMQ发生内部错误从而导致消息丢失,会发送一条nack消息。
发送方确认模式是异步的,生产者应用程序在等待确认的同时,可以继续发送消息。
当确认消息到达生产者应用程序,生产者应用的回调方法就会被触发来处理确认消息。
接收方确认机制
消费者接受每一条消息后都必须进行确认,只要有消费者确认了消息,MQ才能安全的把消息从队列中删除。
这里并没有用到超时机制,MQ仅通过Consumer的连接中断来确认是否需要重新发送消息。也就是说,只要连接不中断,RabbitMQ给了Consumer足够长的时间来处理消息。保证了数据的最终一致性。
还有几种情况:
- 如果消费者接受到消息,在确认之前断开了连接或取消订阅,RabbitMQ会认为消息没有被分发,然后重新分发给下一个订阅的消费者。(可能存在消费重复的隐患,需要去重)
- 如果消费者接受到消息却没有确认消息,连接也未断开,则RabbitMQ认为该消费者繁忙。则不会给该消费者分发更多的消息。
9个球,外观一样,但有一个球是重一点,怎么快速找到这个特殊的球?
最快两次就好了,分三组,第一组和第二组对比,如果相等,那么第三组抽两个出来就选出来了,如果不相等,就在重的那组抽两个出来对比就好了。如果抽出来的这两个一样重,那么就是第三个了。如果倾向另一边,那么就是一边的重了。
没有算法,很奇怪,因为每次面试都要手撕代码,这次没有反而觉得缺了点什么。。