libtorch c++ 搭建分类网络进行训练和预测
目录
1. vgg.h
2. vgg.cpp
3. 预训练权重
3.1 保存pytorch版的预训练权重
3.2 训练
3.2.1 打印权重参数信息
3.2.2 权重初始化
3.2.3 测试预训练权重是否可用
3.2.4 训练函数
3.2.5 主函数
4. 测试
4.1 主函数
4.2 predic函数
1. vgg.h
这里以vgg分类网络为例,vgg网络简单:多层卷积提取特征,最大池化下采样,全连接层进行分类,最后接一个sotmax归一化输出。
#ifndef VGG_H
#define VGG_H
#include<torch/script.h>
#include<torch/torch.h>
#include<vector>
// 二维卷积参数配置
// 注意:关键字inline必须与函数定义放在一起才能使函数成为内联函数,仅仅将inline放在函数声明前面不起任何作用。
inline torch::nn::Conv2dOptions conv_options(int64_t in_planes, int64_t out_planes, int64_t kerner_size,
int64_t stride = 1, int64_t padding = 0, bool with_bias = false) {
torch::nn::Conv2dOptions conv_options = torch::nn::Conv2dOptions(in_planes, out_planes, kerner_size);
conv_options.stride(stride);
conv_options.padding(padding);
conv_options.bias(with_bias);
return conv_options;
}
// 最大池化参数配置
inline torch::nn::MaxPool2dOptions maxpool_options(int kernel_size, int stride){
torch::nn::MaxPool2dOptions maxpool_options(kernel_size);
maxpool_options.stride(stride);
return maxpool_options;
}
// 工具函数:生成多个卷积层,作为特征提取层
// 参数cfg: 中间特征层的通道数,batch_norm:是否使用bn
torch::nn::Sequential make_features(std::vector<int> &cfg, bool batch_norm);
// 创建VGG类,必须继承Module类
// vgg网络:卷积层+pooling层+全连接层
class VGGImpl: public torch::nn::Module
{
public:
VGGImpl(std::vector<int>& cfg, int num_classes = 1000, bool batch_norm = false); // 1个构造函数,初始化各个层操作的参数
torch::Tensor forward(torch::Tensor x); // 1个forward函数
private:
torch::nn::Sequential features_{nullptr}; // 卷积层
torch::nn::AdaptiveAvgPool2d avgpool{nullptr}; // pooling
torch::nn::Sequential classifier; // 全连接层
};
TORCH_MODULE(VGG);
#endif // VGG_H
2. vgg.cpp
#include "vgg.h"
// 工具函数:生成多个卷积层,作为特征提取层
// 参数cfg: 中间特征层的通道数,batch_norm:是否使用bn
torch::nn::Sequential make_features(std::vector<int> &cfg, bool batch_norm){
torch::nn::Sequential features;
int in_channels = 3;
for(auto v : cfg){ // v是通道数
if(v==-1){ // 遇到-1,则接一个池化层
features->push_back(torch::nn::MaxPool2d(maxpool_options(2,2)));
}
else{
// conv2 + bn + relu
auto conv2d = torch::nn::Conv2d(conv_options(in_channels,v,3,1,1)); // k=3,s=1,p=1
features->push_back(conv2d);
if(batch_norm){
features->push_back(torch::nn::BatchNorm2d(torch::nn::BatchNorm2dOptions(v))); // or torch::nn::BatchNorm2d(v)
}
features->push_back(torch::nn::ReLU(torch::nn::ReLUOptions(true))); // relu层
in_channels = v;
}
}
return features;
}
// 初始化私有成员: features_,avgpool,classifier
VGGImpl::VGGImpl(std::vector<int> &cfg, int num_classes, bool batch_norm){
features_ = make_features(cfg,batch_norm); // 1.初始化卷积层(包含了池化层)
avgpool = torch::nn::AdaptiveAvgPool2d(torch::nn::AdaptiveAvgPool2dOptions(7)); // 2.初始化池化层
classifier->push_back(torch::nn::Linear(torch::nn::LinearOptions(512 * 7 * 7, 4096))); // 3.初始化全连接层
classifier->push_back(torch::nn::ReLU(torch::nn::ReLUOptions(true)));
classifier->push_back(torch::nn::Dropout());
classifier->push_back(torch::nn::Linear(torch::nn::LinearOptions(4096, 4096)));
classifier->push_back(torch::nn::ReLU(torch::nn::ReLUOptions(true)));
classifier->push_back(torch::nn::Dropout());
classifier->push_back(torch::nn::Linear(torch::nn::LinearOptions(4096, num_classes))); // 两个linear+relu+dropout, 再加一个linear.
features_ = register_module("features",features_); // module必须注册
classifier = register_module("classifier",classifier);
}
torch::Tensor VGGImpl::forward(torch::Tensor x){
x = features_->forward(x); // 1,先卷积(包含了池化层),注册的module需要通过forward使用
x = avgpool(x); // 2,再池化,直接使用
x = torch::flatten(x,1); // 3,二维变一维
x = classifier->forward(x); // 4,再接全连接层
return torch::log_softmax(x, 1); // 5,最后softmax
}
3. 预训练权重
使用预训练权重训练模型,可以更快的收敛。为了使c++训练模型时能够使用pytorch版的预训练权重,c++代码搭建的vgg必须和pytorch一致。感兴趣的可以看下官方的pytorch代码torchvision.models.vgg16_bn
3.1 保存pytorch版的预训练权重
注意要使用jit.trace函数。
import torch
from torchvision.models import vgg16, vgg16_bn
# 在c++中搭建一个和pytorch下完全一致的vgg16bn。如果不一致的话其实不影响正常的模型训练和预测,
# 但是影响初始化状态,模型加载从ImageNet数据集训练好的权重以后,训练收敛的速度和收敛后的精度都会好很多。
model = vgg16_bn(pretrained=True)
model = model.to(torch.device("cpu"))
model.eval()
var = torch.ones((1, 3, 224, 224))
# 保存pytorch模型的权重不能直接用torch.save保存模型,这样存下来的模型不能被c++加载。我们利用部署时常用的torch.jit.script模型来保存。
traced_script_module = torch.jit.trace(model, var)
traced_script_module.save("vgg16bn.pt")
# 这样,模型的卷积层,归一化层,线性层的权重就保存到.pt文件中了。
3.2 训练
基于VGG类,再打包一次得到Classifier类。
classification.h
#ifndef CLASSIFICATION_H
#define CLASSIFICATION_H
#include<vgg.h>
#include<dataSet.h>
#include<opencv2/opencv.hpp>
class Classifier
{
private:
torch::Device device = torch::Device(torch::kCPU); // 默认使用cpu
VGG vgg = VGG{nullptr}; // 自定义网络对象
public:
Classifier(int gpu_id = 0); // 构造函数,初始化device私用成员
void Initialize(int num_classes, std::string pretrained_path); // 加载预训练权重
void Train(int epochs, int batch_size, float learning_rate, std::string train_val_dir, std::string image_type, std::string save_path);
int Predict(cv::Mat &image); // preprocess + infer + postprocess
void LoadWeight(std::string weight); // 加载权重
};
#endif // CLASSIFICATION_H
3.2.1 打印权重参数信息
先看看权重参数的特点。
# pytorch
import torch
from torchvision.models import vgg16, vgg16_bn
model = vgg16_bn(pretrained=True)
for k, v in model.named_parameters():
print(k)
// c++
std::vector<int> cfg_dd = {64, 64, -1, 128, 128, -1, 256, 256, 256, -1, 512, 512, 512, -1, 512, 512, 512, -1};
auto vgg_dd = VGG(cfg_dd,1000,true); // 直接实例化VGG即可
auto dictdd = vgg_dd->named_parameters();
for (auto n = dictdd.begin(); n != dictdd.end(); n++) // 打印出模型每一层(有权重的层,不包括类似激活函数层)的名称
{
std::cout<<(*n).key()<<std::endl;
}左边是pytorch打印的信息,右边是c++打印的信息,可以发现c++的少了部分bias 权重,这是因为有些卷积没有设置bias(可以设置)。初始化的时候,根据权重参数名称初始化右边对应的值。

3.2.2 权重初始化
利用pytorch版的预训练权重(前面有保存下来),初始化c++网络权重参数。
classification.cpp
// 使用预训练权重,初始化自定义的模型权重
void Classifier::Initialize(int _num_classes, std::string _pretrained_path){
std::vector<int> cfg_d = {64, 64, -1, 128, 128, -1, 256, 256, 256, -1, 512, 512, 512, -1, 512, 512, 512, -1};
auto net_pretrained = VGG(cfg_d,1000,true); // 注意这里是1000个类别,实例化预训练网络,为了取出权重
vgg = VGG(cfg_d,_num_classes,true); // 注意这里的类别个数
torch::load(net_pretrained, _pretrained_path); // 预训练的网络载入预训练的权重。
torch::OrderedDict<std::string, at::Tensor> pretrained_dict = net_pretrained->named_parameters();
torch::OrderedDict<std::string, at::Tensor> model_dict = vgg->named_parameters();
// 将训练的权重值提取出来,其中后面的分类层参数值丢弃不用。
for (auto n = pretrained_dict.begin(); n != pretrained_dict.end(); n++)
{
if (strstr((*n).key().data(), "classifier")) { // 不使用分类层的权重
continue;
}
model_dict[(*n).key()] = (*n).value();
}
torch::autograd::GradMode::set_enabled(false); // make parameters copying possible
auto new_params = model_dict; // implement this
auto params = vgg->named_parameters(true /*recurse*/);
auto buffers = vgg->named_buffers(true /*recurse*/);
for (auto& val : new_params) { // 功能:将屏蔽分类层后的新权重,复制到自定义的vgg网络模型权重中。
auto name = val.key();
auto* t = params.find(name); // 查看自定义网络中是否有该权重参数名
if (t != nullptr) {
t->copy_(val.value()); // 有,则将预训练得到的val复制到自定义网络参数中。
}
else {
t = buffers.find(name); // 没有,则看看buffer里面有没有,都没有则跳过。
if (t != nullptr) {
t->copy_(val.value());
}
}
}
torch::autograd::GradMode::set_enabled(true);
try
{
vgg->to(device);
}
catch (const std::exception&e)
{
std::cout << e.what() << std::endl;
}
return;
}3.2.3 测试预训练权重是否可用
#include<Classification.h>
int main(int argc, char *argv[])
{
//2,加载预训练权重,测试权重是否可用。
std::vector<int> cfg_16bn = { 64, 64, -1, 128, 128, -1, 256, 256, 256, -1, 512, 512, 512, -1, 512, 512, 512, -1 };
auto vgg16bn = VGG(cfg_16bn, 1000, true);
torch::load(vgg16bn, "E:\\code\\c++\\LibtorchTutorials-main\\vgg16bn.pt");
vgg16bn->to(torch::Device(torch::kCUDA));
}最后一句报错:PyTorch is not linked with support for cuda devices
解决办法:属性->链接器->命令行:
libtorch 1.5: -INCLUDE:THCudaCharTensor_zero
libtorch 1.6/1.7/1.9/1.9.1/1.10/1.1:-INCLUDE:?warp_size@cuda@at@@YAHXZ
libtorch 1.8.1: -INCLUDE:?wait@Future@ivalue@c10@@QEAAXXZ
或者:-INCLUDE:?mutate@OptOutMutator@cuda@fuser@jit@torch@@UEAAPEAVStatement@2345@PEAVForLoop@kir@2345@@Z3.2.4 训练函数
这里有个骚操作,前8个epoch保留前面的特征提取层参数不变(即使用预训练权重值),只更新分类层参数。
void Classifier::Train(int num_epochs, int batch_size, float learning_rate, std::string train_val_dir, std::string image_type, std::string save_path){
std::string path_train = train_val_dir+ "\\train"; // 数据路径
std::string path_val = train_val_dir + "\\val";
auto custom_dataset_train = dataSetClc(path_train, image_type).map(torch::data::transforms::Stack<>()); // dataset
auto custom_dataset_val = dataSetClc(path_val, image_type).map(torch::data::transforms::Stack<>());
auto data_loader_train = torch::data::make_data_loader<torch::data::samplers::RandomSampler>(std::move(custom_dataset_train), batch_size); // dataloader
auto data_loader_val = torch::data::make_data_loader<torch::data::samplers::RandomSampler>(std::move(custom_dataset_val), batch_size);
float loss_train = 0; float loss_val = 0; // 累加当前epoch内所有的loss,求平均loss
float acc_train = 0.0; float acc_val = 0.0; float best_acc = 0.0; // 累加准去率,和最佳准确率
for (size_t epoch = 1; epoch <= num_epochs; ++epoch) { // epoch
size_t batch_index_train = 0; // 记录当前是第几个batch
size_t batch_index_val = 0;
if (epoch == int(num_epochs / 2)) { learning_rate /= 10; } // 每两个epoch下降一次学习率
torch::optim::Adam optimizer(vgg->parameters(), learning_rate); // Learning Rate
if (epoch < int(num_epochs / 8)) // 前8个epoch只更新分类层参数
{
for (auto mm : vgg->named_parameters())
{
if (strstr(mm.key().data(), "classifier")) // 只更新分类层的参数
{
mm.value().set_requires_grad(true);
}
else
{
mm.value().set_requires_grad(false);
}
}
}
else { // 后面epoch次更新全部参数
for (auto mm : vgg->named_parameters())
{
mm.value().set_requires_grad(true);
}
}
// Iterate data loader to yield batches from the dataset
for (auto& batch : *data_loader_train) {
auto data = batch.data; // b,c,h,w
auto target = batch.target.squeeze(); // b,1
data = data.to(torch::kF32).to(device).div(255.0); // data: kf32,cuda,/255
target = target.to(torch::kInt64).to(device); // target: kint64, cuda
optimizer.zero_grad();
// Execute the model
torch::Tensor prediction = vgg->forward(data);
//cout << prediction << endl;
auto acc = prediction.argmax(1).eq(target).sum();
acc_train += acc.template item<float>() / batch_size;
// Compute loss value
torch::Tensor loss = torch::nll_loss(prediction, target);
// Compute gradients
loss.backward();
// Update the parameters
optimizer.step();
loss_train += loss.item<float>(); // 累加loss
batch_index_train++;
std::cout << "Epoch: " << epoch << " |Train Loss: " << loss.item<float>() << " |Train Acc:" << acc_train / batch_index_train << "\r";
}
std::cout << std::endl;
//validation part
vgg->eval();
for (auto& batch : *data_loader_val) {
auto data = batch.data;
auto target = batch.target.squeeze();
data = data.to(torch::kF32).to(device).div(255.0);
target = target.to(torch::kInt64).to(device);
torch::Tensor prediction = vgg->forward(data);
// Compute loss value
torch::Tensor loss = torch::nll_loss(prediction, target);
auto acc = prediction.argmax(1).eq(target).sum(); // val准确率计算方法
acc_val += acc.template item<float>() / batch_size;
loss_val += loss.item<float>(); // 累加loss
batch_index_val++;
std::cout << "Epoch: " << epoch << " |Val Loss: " << loss_val / batch_index_val << " |Valid Acc:" << acc_val / batch_index_val << "\r";
}
std::cout << std::endl;
if (acc_val > best_acc) {
torch::save(vgg, save_path);
best_acc = acc_val;
}
loss_train = 0; loss_val = 0; acc_train = 0; acc_val = 0; batch_index_train = 0; batch_index_val = 0;
}
}其中 dataset-dataSetClc的定义与上一篇博客一样都是图像分类数据集。
3.2.5 主函数
#include<Classification.h>
int main(int argc, char *argv[])
{
//2,使用预训练权重,进行推理
std::string vgg_weight_path = "E:\\code\\c++\\LibtorchTutorials-main\\vgg16bn.pt";
std::string train_val_dir = "F:\\zxq\\data\\hymenoptera_data";
Classifier classifier(0); // gpu id: 0
classifier.Initialize(2, vgg_weight_path); // 使用预训练权重初始化权重,
classifier.Train(300, 4, 0.0003, train_val_dir, ".jpg", "classifer.pt");
}验证集的准确率是0.91。
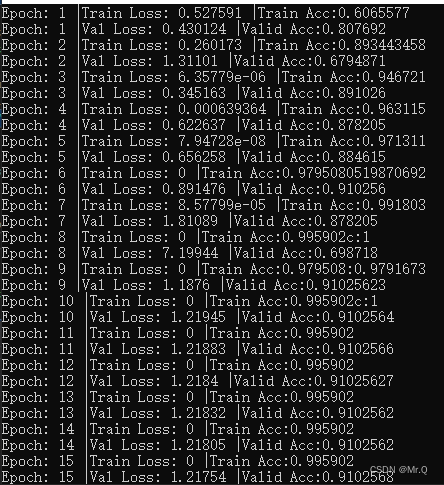
换成猫狗大战数据集(分出4000张训练),训练和测试集loss收敛的都很快。
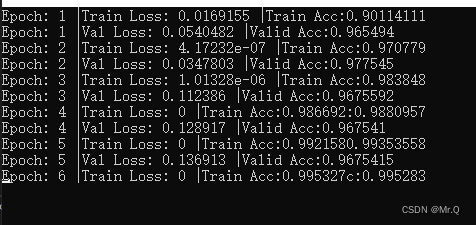
4. 测试
测试的时候发现一个问题,在2080ti训练的模型,在3080显卡下预测会报错:
Microsoft C++ 异常: c10::Error,位于内存位置 0x000000301E6F3BF0 处。
可以在高端显卡训练,低端显卡部署。
4.1 主函数
// 3, infer
Classifier classifier(1); // gpu id: 0
classifier.Initialize(2, "E:\\code\\c++\\LibtorchTutorials-main\\vgg16bn.pt");
classifier.LoadWeight("E:\\code\\c++\\LibtorchLearning\\classifer.pt");
std::string train_val_dir = "F:\\zxq\\data\\custom\\dog";
cv::Mat image = cv::imread(train_val_dir+"\\dog.2344.jpg");
int cls_id = classifier.Predict(image); // preprocess + forward
std::cout << "cls_id: " << cls_id << std::endl; 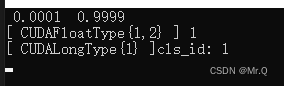
换成cat图片。

4.2 predic函数
int Classifier::Predict(cv::Mat& image){
// preprocess: resize, to_tensor, cuda, kf32, /255
cv::resize(image, image, cv::Size(448, 448));
torch::Tensor img_tensor = torch::from_blob(image.data, { image.rows, image.cols, 3 }, torch::kByte).permute({ 2, 0, 1 }); // c,h,w
img_tensor = img_tensor.to(device).unsqueeze(0).to(torch::kF32).div(255.0);
auto prediction = vgg->forward(img_tensor); // raw output
prediction = torch::softmax(prediction,1);
auto class_id = prediction.argmax(1);
std::cout<<prediction<<class_id;
int ans = int(class_id.item().toInt());
float prob = prediction[0][ans].item().toFloat();
return ans;
}
void Classifier::LoadWeight(std::string weight){
torch::load(vgg,weight); // 载入训练好的权重
vgg->eval();
return;
}参考:LibtorchTutorials/lesson5-TrainingVGG at main · AllentDan/LibtorchTutorials · GitHub