最优传输及其在公平中的应用
源于经济学的最佳运输被开发为如何最好地分配资源的工具。最佳运输理论本身的起源可以追溯到 1781 年,当时加斯帕德·蒙格研究了最有效的移动地球方法,为拿破仑的军队建造防御工事。总体而言,最优运输是一个问题,即如何将所有资源(例如铁)从一组起点(铁矿)移动到一组终点(铁工厂),同时最小化资源的总距离必须旅行。在数学上,我们希望找到一个函数,该函数将每个起点映射到一个目的地,同时最小化起点与其对应目的地之间的总距离。尽管它的描述无伤大雅,但在这个问题的原始表述上取得了进展,
解决方案的第一次真正飞跃发生在 1940 年代,当时一位名叫 Leonid Kantorovich 的苏联数学家将问题的公式调整为现代版本,即现在称为 Monge-Kantorovich 公式。这里的新奇之处在于允许来自同一矿山的一些铁进入不同的工厂。例如,一个矿山的 60% 的铁可以运往一家工厂,而该矿山剩余的 40% 的铁可以运往另一家工厂。从数学上讲,这不再是一个函数,因为同一个原点现在映射到可能的许多目的地。相反,这称为 耦合 始发地分布和目的地分布之间的关系,如下图所示;从蓝色分布(产地)中挑选一个矿并沿着该图垂直移动显示了该铁被发送到的工厂(目的地)的分布。
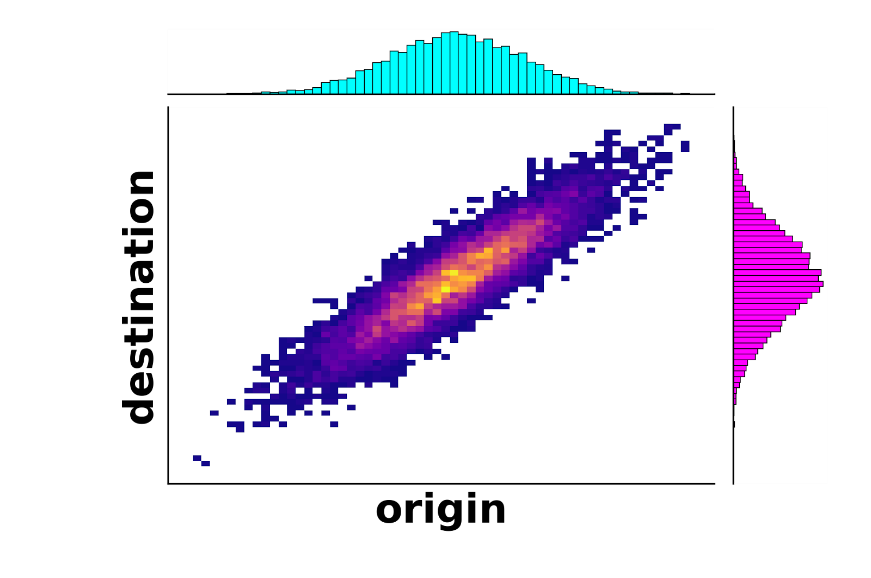
作为这一新发展的一部分,Kantorivich 引入了一个重要的概念,称为 Wasserstein 距离。与地图上两点之间的距离类似,Wasserstein 距离(也称为推土机距离,受其原始上下文启发)测量两个分布之间的距离,例如本例中的蓝色和洋红色分布。例如,如果所有的铁矿都离所有的铁厂都很远,那么矿场分布(位置)和工厂分布之间的 Wasserstein 距离就会很大。即使有了这些新的改进,仍然不清楚是否真的存在运输资源的最佳方式,更不用说那种方式了。最后,在 1990 年代,由于数学分析和优化的改进导致问题的部分解决方案,该理论开始迅速发展。也是在这个时候和进入 21 世纪,最优传输开始蔓延到其他领域,如粒子物理学、流体动力学,甚至统计和机器学习。
现代最优运输
随着新发展理论的爆炸式增长,优化运输已成为 许多新的统计 和 人工智能算法的中心 近两年出现。在几乎每一种统计算法中,数据都被显式或隐式地建模为具有一些潜在的概率分布。例如,如果您正在收集不同国家/地区的个人收入数据,则该人口收入的每个国家/地区都有一个概率分布。如果我们想根据人口的收入分布来比较两个国家,那么我们需要一种方法来衡量这两个分布之间的差距。这正是优化传输(尤其是 Wasserstein 距离)在数据科学中变得如此有用的原因。然而,Wasserstein 距离并不是衡量两个概率分布相距多远的唯一指标。实际上,两种选择——L-2 距离和 Kullback-Leibler (KL) 散度——由于它们与物理学和信息论的联系,在历史上更为常见。Wasserstein 距离相对于这些替代方案的主要优势在于它同时需要 计算距离时会考虑值 及其概率,而 L-2 距离和 KL 散度只考虑概率。下图显示了一个关于三个虚构国家收入的人工数据集的示例。
在这种情况下,由于分布不重叠,蓝色和品红色分布之间的 L-2 距离(或 KL 散度)将与蓝色和绿色分布之间的 L-2 距离大致相同。另一方面,蓝色和品红色分布之间的 Wasserstein 距离将远小于蓝色和绿色分布之间的 Wasserstein 距离,因为值存在显着差异(水平分离)。Wasserstein 距离的这一特性使其非常适合量化分布之间的差异,特别是数据集之间的差异。
以最优传输强制公平
随着每天收集大量数据以及机器学习在许多行业中变得越来越普遍,数据科学家必须越来越小心,不要让他们的分析和算法使数据中现有的偏见和偏见永久化。例如,如果住房抵押贷款批准的数据集包含有关申请人种族的信息,但由于使用的方法或无意识的偏见,少数族裔在收集过程中受到歧视,那么基于该数据训练的模型将在一定程度上反映潜在的偏见。可以利用最佳传输来帮助 减轻这种偏见 并 提高公平性 有两种方式。第一种也是最简单的方法是使用 Wasserstein 距离来确定数据集中是否存在潜在偏差。例如,我们可以估计批准给女性的贷款额分布和批准给男性的贷款额分布之间的 Wasserstein 距离,如果 Wasserstein 距离非常大,即具有统计学意义,那么我们可能会怀疑存在潜在偏差。这种检验两组之间是否存在差异的想法在统计学中称为双样本假设检验。
或者,当底层数据集本身存在偏差时,甚至可以使用最优传输来强制模型中的公平性。从实际的角度来看,这非常有用,因为许多真实的数据集会表现出一定程度的偏差,并且收集无偏差的数据可能非常昂贵、耗时或不可行。因此,使用我们现有的数据更为实际,无论它可能多么不完美,并尝试确保我们的模型减轻这种偏差。这是通过强制执行称为 强人口统计奇偶 性的约束来实现的在我们的模型中,这迫使模型预测在统计上独立于任何敏感属性。一种方法是将模型预测的分布映射到不依赖于敏感属性的调整预测的分布。但是,调整预测也会改变模型的性能和准确性,因此在模型性能和模型对敏感属性的依赖程度(即公平程度)之间存在权衡。
通过尽可能少地更改预测以确保最佳模型性能,同时仍保证新预测独立于敏感属性,最佳传输开始发挥作用。这种调整后的模型预测的新分布被称为 Wasserstein 重心,在过去十年中一直是许多研究的主题。Wasserstein 重心类似于概率分布的平均值,因为它最小化了从自身到所有其他分布的总距离。下图显示了三个分布(绿色、蓝色和洋红色)以及它们的 Wasserstein 重心(红色)。
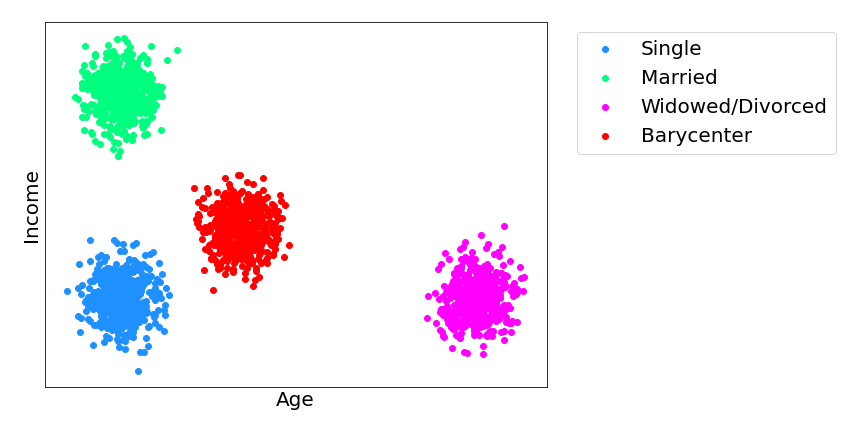
在上面的示例中,假设我们基于包含单个敏感属性(例如婚姻状况)的数据集构建了一个模型来预测一个人的年龄和收入,该属性可以取三个可能的值:单身(蓝色)、已婚(绿色)和丧偶/离婚(洋红色)。散点图显示了每个不同值的模型预测分布。但是,我们想要调整这些,以便新模型的预测对一个人的婚姻状况是盲目的。我们可以使用最佳传输将这些分布中的每一个映射到红色的重心。因为所有值都映射到相同的分布,我们不能再根据收入和年龄来判断一个人的婚姻状况,反之亦然。重心尽可能地保持模型的保真度。
数据和机器学习模型的日益普及在企业和政府决策中使用,导致了新的社会和道德问题,以确保其公平应用。由于收集方式的性质,许多数据集包含某种偏差,因此在它们上训练的模型不会加剧这种偏差或任何历史歧视,这一点很重要。优化运输只是解决近年来势头强劲的这一问题的一种方法。如今,有快速有效的方法来计算最佳运输地图和距离,使这种方法适用于现代大型数据集。随着我们越来越依赖基于数据的模型和洞察力,公平已经并将继续成为数据科学的核心问题,而最佳传输将在实现这一目标中发挥关键作用。