北理工操作系统实验合集
文章目录
- 进程控制API
- Linux
- getpid/getppid
- fork/vfork
- exit/_exit
- exec函数族
- wait/waitpid
- pause/sleep
- Windows
- Windows创建进程
- 进程间通信API(IPC-API)
- Linux
- 共享内存区
- 信号量
- Windows
- 实验一:Linux内核编译
- 实验二:生产者消费者进程
- 共享内存案例
- 一个基本的例子
- Linux版本
- Windows版本
进程控制API
Linux
- 创建:fork/vfork
- 终止:exit/_exit
- 获取进程标识符:getpid/getppid(获取parent的pid)
- 调用程序:exec
- 进程等待:wait/waitpid
- 暂停:pause/sleep
getpid/getppid
主进程是程序本身,又称作父进程。父进程可以创建进程,称作子进程。每一个进程都有一个id,通过函数可以查询当前id和父进程id,为什么没有子进程id?这是因为子进程可以创建多个,目前返回值还没有实现一次返回多个的机制。
#include <unistd.h>
pid_t getpid(void);
pid_t getppid(void); //父进程
fork/vfork
#include <sys/types.h>
#include <unistd.h>
pid_t fork (void);
fork是双返回值的,在子进程中返回0(不是子进程pid),父进程中返回子进程的pid(不是父进程pid)。
父子进程实际上是写在一份代码中的,通过if else区分父子进程,可以实现一份代码两个作用。fork是单调用双返回函数,父进程的返回值是子进程PID,子进程返回值为0,这样就既能做到通信,又能实现区分。要想判断当前进程是父进程还是子进程,检验一下PID就行。
先来明确一些fork过程中的pid都是些什么:
#include<unistd.h>
#include<stdio.h>
#include<sys/types.h>
int main(void)
{
printf("main pid=%d\n",getpid());
pid_t pid;
if((pid=fork())<0)
{
printf("error\n");
exit(0);
}
else if(pid==0)
{
printf("child forkpid=%d getpid=%d\n",pid,getpid());
}
else
{
printf("father forkpid=%d getpid=%d\n",pid,getpid());
}
}
可以看到主进程pid为23389,子进程pid为23390。父进程的fork返回值为23390,即子进程pid,子进程fork返回值为0,表示当前进程为子进程。

给一个复杂一点的代码如下:
#include <sys/types.h>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
int glob = 3;//全局变量
int main(void)
{
pid_t pid; //pid_t类型
int loc = 3; //局部变量
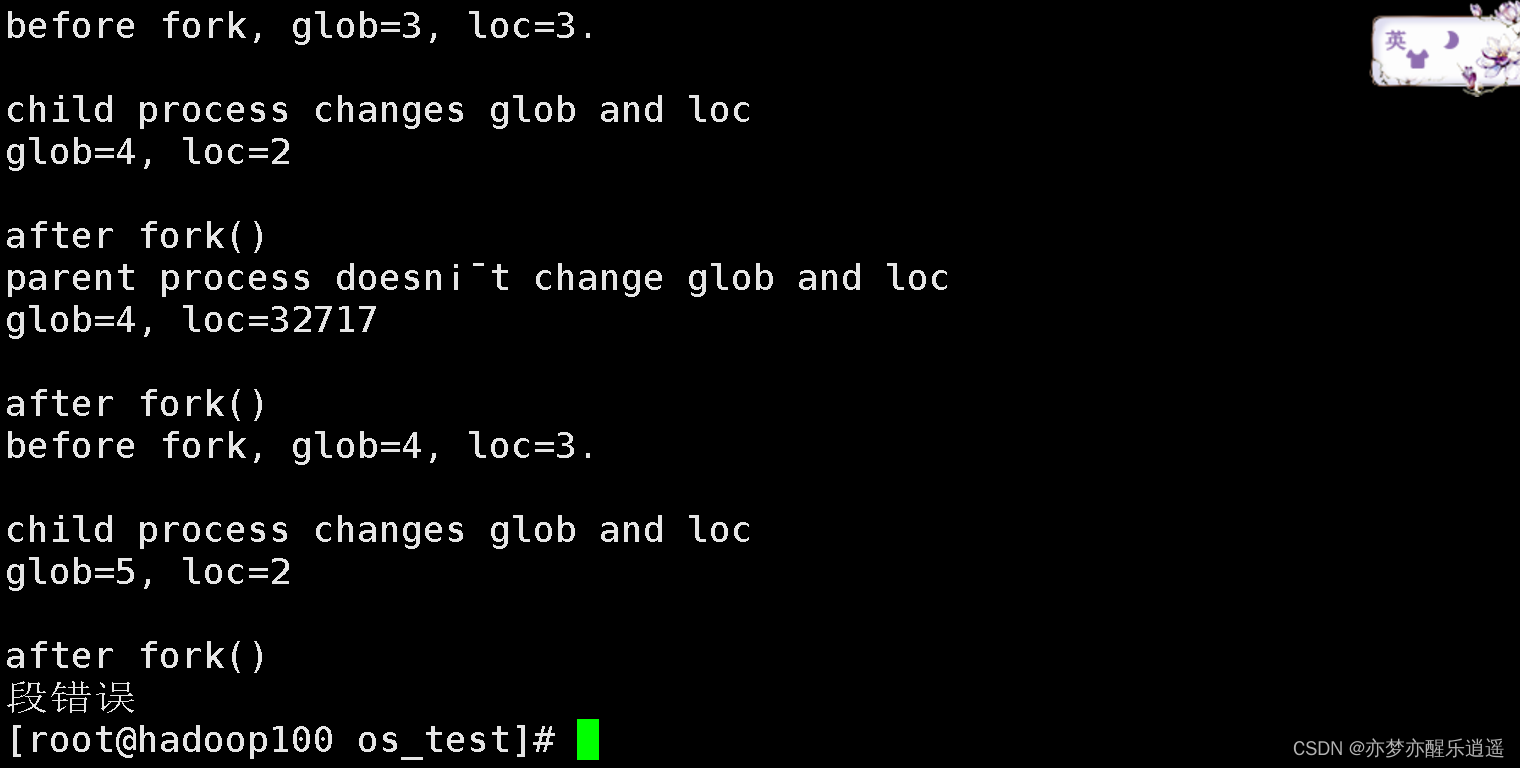
printf("before fork, glob=%d, loc=%d.\n\n", glob, loc);
if((pid=fork())<0) //fork,赋值pid,检验是否成功
{
printf("fork() failed.\n");
exit(0);
}
else if(pid==0) //子进程代码段
{
glob++;
loc--;
printf("child process changes glob and loc\n");
printf("glob=%d, loc=%d\n", glob, loc);
}
else //父进程代码段
{
printf("parent process doesn’t change glob and loc\n");
printf("glob=%d, loc=%d\n", glob, loc);
}
printf("\nafter fork()\n");
//return 0;
exit(0);
}
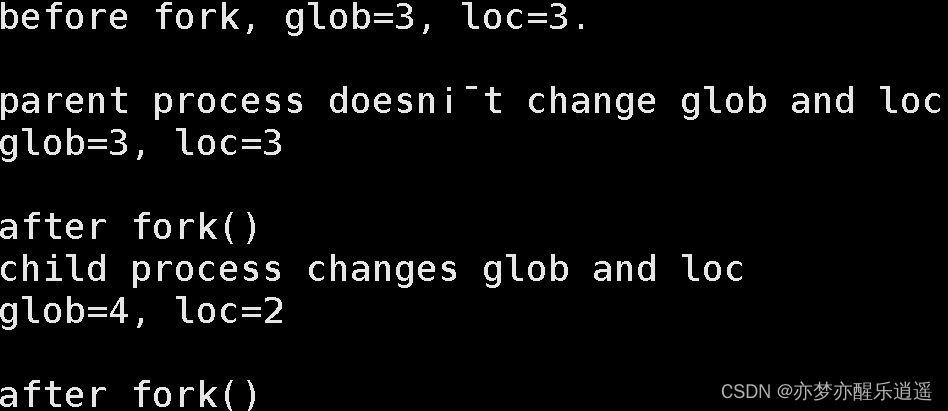
由此可见,fork的执行机制:将fork后的代码复制一份出来,重复创建两个进程,一个为父(pid>0),一个为子(pid=0),进程都拥有全部资源,且资源隔离。
探讨一下代码复制机制。我在fork前和fork后都加了printf,发现fork前代码只执行一次,fork后代码执行两次,说明fork只复制后面的代码,前面的仅是资源共享,代码不共享。
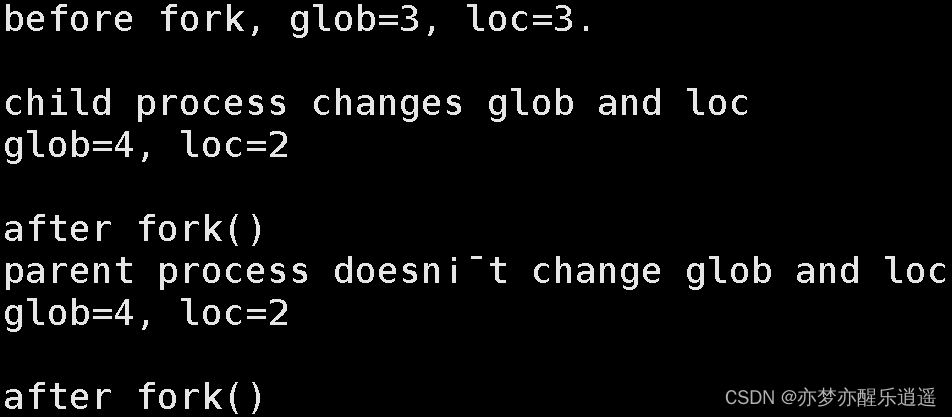
而vfork则是两个进程资源共享,而且会阻塞父进程,先把子进程执行完,再回来执行父进程。所以可以说vfork是串行,fork是并行。
#include <sys/types.h>
#include <stdio.h>
pid_t vfork(void);
把fork改vfork后,代码结果如下:
exit/_exit

exit先在用户态下,把IO关闭,清空缓冲,之后切到核心态进行系统调用去终止进程。
_exit直接跳过用户态处理,强制终止进程。
exit和return在单进程程序中都可以作为main函数结尾,但是如果在多进程情况下(前面的代码),将最后的exit替换成return,在使用vfork的情况下会报错,具体原因是因为,return影响进程栈,exit是直接退出,如果是vfork,栈是共享的,子进程先return把栈关闭了,那主进程再return,就会出错,甚至栈内的数的调用也会出bug。
参考
如果把上面的代码变成vfork+return,就会报错,意料之中:
首先是,主进程的loc会出问题,其次是竟然又会再执行一次主进程,还会出现段错误,总之问题很多。
exec函数族
exec()函数族。这是一系列函数。

进程调用函数运行一个外部的可执行程序。调用后,原进程代码段、数据段与堆栈段被新程序所替代,新程序从它的main( )开始执行。进程号保持不变,因为是被替代了,而不是新建了进程。此时,原程序exec后面的代码不会被执行(各个内存段都被替代了,自然不会保留源程序,唯一留下的,就是pid)。
给出两个调用例子(execl函数):
#include<unistd.h>
#include<stdio.h>
int main(void)
{
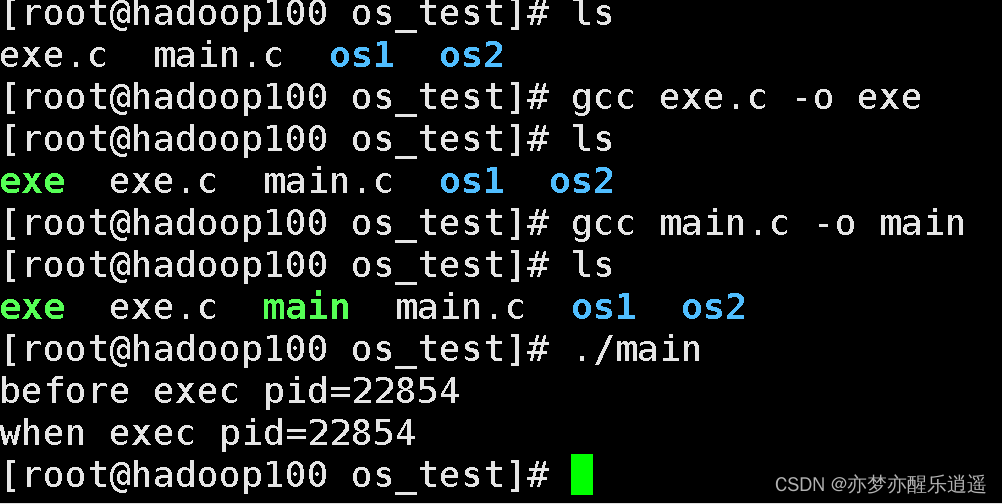
printf("when exec pid=%d\n",getpid());
}
#include<unistd.h>
#include<stdio.h>
int main(void)
{
printf("before exec pid=%d\n",getpid());
execl("./exe",0);
printf("after exec pid=%d\n",getpid());//这一行不执行
}
看下面的执行结果,用main去调用exe,pid是不变的,但是exec后面的代码没有执行(after那句)
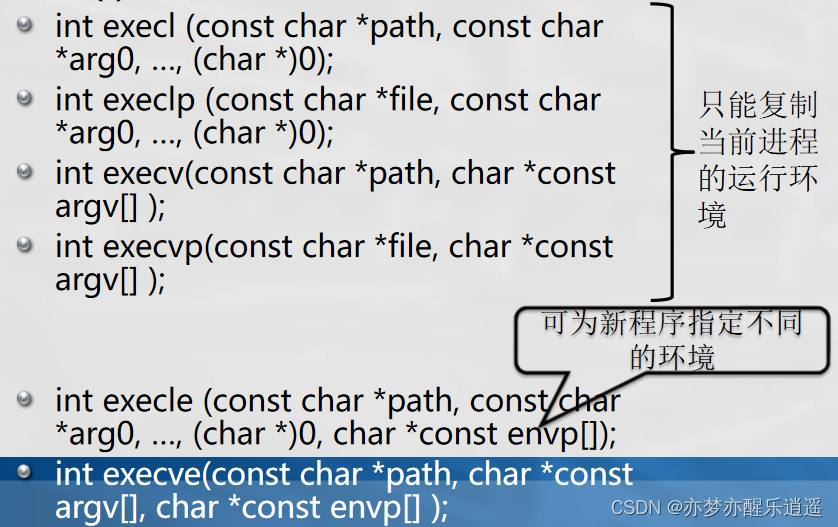
exec族具有统一的特征,那具体内部之间还有什么区别呢?
第一个区别在于是否要加路径,或者说路径是否在path中。一般来说,要么用相对路径,要么就用已经加了环境变量的,保证程序鲁棒性。

第二个区别是,命令行参数是采用可变参数+NULL结尾的方式指定,还是以char* argv[]的方式传入(不需要用NULL表明参数列表结束)。

第三个区别在于,是否可以指定新环境,新环境以argv形式传入。
wait/waitpid
wait等待任意一个子进程终止,返回值为子进程pid,同时子进程终止码由一个int指针从参数中返回。
#include <sys/types.h>
#include <sys/wait.h>
pid_t wait(int *statloc);
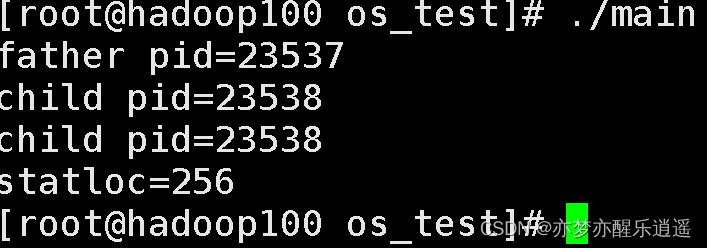
下面程序展示了返回值和statloc,但是这个statloc比较奇特,如果把exit(1)对应256的statloc,exit(2)对应512的statloc。即exit中数*256。通常都是wait(0),不用这个statloc。
#include<unistd.h>
#include<stdio.h>
#include<sys/types.h>
#include<wait.h> //wait
int main(void)
{
pid_t pid;
if((pid=fork())<0)
{
printf("error\n");
}
else if(pid==0) //子进程
{
printf("child pid=%d\n",getpid());
exit(1);
}
else //父进程
{
printf("father pid=%d\n",getpid());
int statloc;
printf("child pid=%d\n",wait(&statloc));
printf("statloc=%d\n",statloc);
exit(0);
}
}
exit(2)
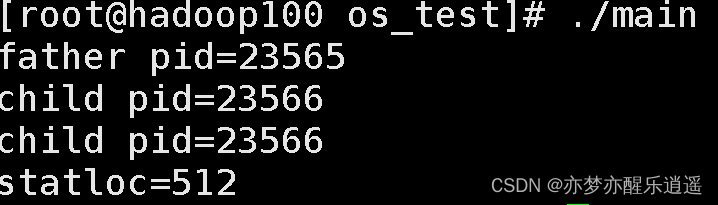
waitpid,通过pid参数实现更灵活的控制,选择性等待某个子进程,至于子进程pid从何而来,你的fork是有返回值的,保存即可。
#include <sys/types.h>
#include <sys/wait.h>
pid_t waitpid(pid_t, int *statloc, int options);
- 父进程可以使用pid指定等待的子进程,pid > 0:pid完全匹配,pid = 0:匹配与当前进程是同一个进程组的任何终止子进程;pid = -1:匹配任何终止的子进程;pid < -1:匹配任何进程组标识等于pid绝对值的任何终止子进程
- 可在option中设置WNOHANG,如果没有任何子进程终止,则立即返回0,如不使用option,参数为0。
- wait(statloc) = waitpid(-1, statloc, 0)
pause/sleep
pause基本不用,sleep粗略,秒单位,usleep特地使用unsigned long参数,就是为了支持毫秒睡眠。
下面给出简单的sleep代码,子进程先输出5次,主进程wait后也输出5次。wait放在循环内外都无所谓,因为子进程只会exit一次,exit后wait函数如果检测不到子进程,也不会阻塞。
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h> /* 简单的进程同步: 父进程等待子进程输出后再输出*/
main()
{
int p;
while((p=fork())==-1);
if(p==0)
{/*子进程块*/
int i;
for(i=0;i<5;i++)
{
printf("I am child.\n");
sleep(1);
}
exit(0);
}
else
{/*父进程块*/
int i;
//wait(0);
for(i=0;i<5;i++)
{
wait(0); //等待子进程结束
printf("I am parent.\n");
sleep(1);
}
}
}

Windows
Windows创建进程
CreateProcess。
主要参数是可执行文件,命令行参数,以及一个句柄引用。创建出来的进程句柄会以引用的方式返回到参数里。

进程间通信API(IPC-API)
IPC:InterProcess Communication
Linux

Unix和Linux的标准很混乱,我们主要使用XSI IPC里面的Posix标准,重点在于共享内存区和信号量API。
共享内存区
linux控制台中使用icps命令查看。
两个或者更多进程可以共享一个内存区,一个进程也可以使用多个共享内存区。
程序中用这三个接口:
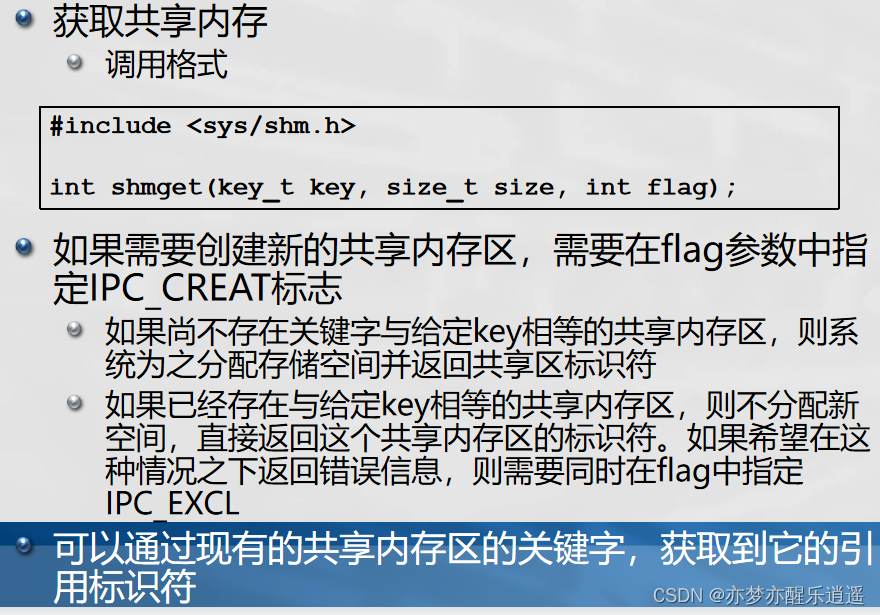
- 共享内存获取shmget
- 共享内存区的附加与解除shmat/shmdt
- 共享内存区控制shmctl



信号量
信号量:semaphore
IPC中,信号量不是像伪代码那种单个声明,而是以信号量集的形式声明,通过函数指定信号量进行操作,信号量集中可以有一个或者多个信号量。
- 信号量集的获取semget
- 信号量集的操作semop
- 信号量集的控制semctl
Windows
TODO
实验一:Linux内核编译
实验二:生产者消费者进程
- 一个大小为3的缓冲区,初始为空
- 2个生产者
- 随机等待一段时间,往缓冲区添加数据,
- 若缓冲区已满,等待消费者取走数据后再添加
- 重复6次
- 3个消费者
- 随机等待一段时间,从缓冲区读取数据
- 若缓冲区为空,等待生产者添加数据后再读取
- 重复4次
- 说明:
- 显示每次添加和读取数据的时间及缓冲区里的数据
- 生产者和消费者用进程模拟
- Linux和Windows都做
共享内存案例
一个基本的例子
共享内存例子
这个代码写的挺好,拿来可以直接跑,从宏观上来说,这是一个testset程序,使用while循环不断询问。对于代码,我有一些思考:
key和id看起来都可以用来索引一个共享内存区,但是平时更多地使用的是id。我猜,用key指定是要进行搜索的,而id就类似于索引一样,是字典关系,效率高。因此,有id还是用id,没有id才用key去获取id。
int shmid = shmget ( ( key_t ) 1234, sizeof ( struct shared_use_st ), 0666 | IPC_CREAT );
在两个进程中,都使用了同一个shmget写法,参数都一模一样。所以在不同进程之间,要想访问同一个共享内存区,就需要指定相同的key。shmflag一般是IPC_CREAT(0666作用未知),在第一个shmget中,key对应的内存区不存在,所以就新建一个。第二个shmget中,key对应的内存去存在,所以就直接获取对应的id。
总的来说,用key获取id,用的时候用id。
不过有一种特殊情况,就是key=IPC_PRIVATE,即key==0,此时共享内存区是私密的,不允许外部进程使用(无法通过key获取id),但是子进程可以使用,因为有现成的id。
说完shmget,再说一下shmat/shmdt。
在已知shmid的前提下,可以通过shmat获取共享内存的首地址,其指针是void*型的,一般会进行强转。另外两个参数一般都是0。
shared_memory = shmat ( shmid, NULL, 0 );
shmdt的参数是前面的shared_memory,代表本进程解除与共享内存的绑定。
shmdt ( shared_memory )
至于shmctl,一般是不进行配置的。
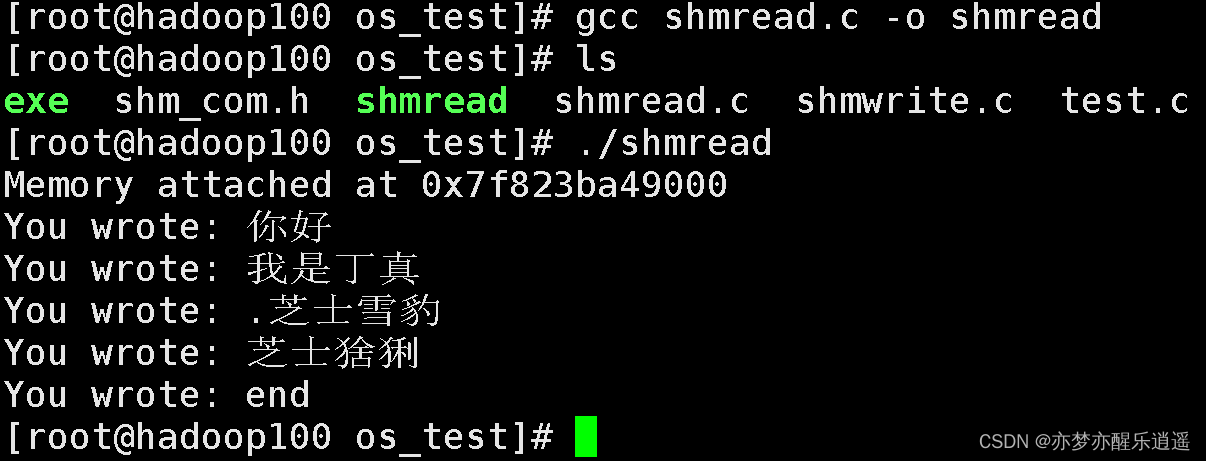
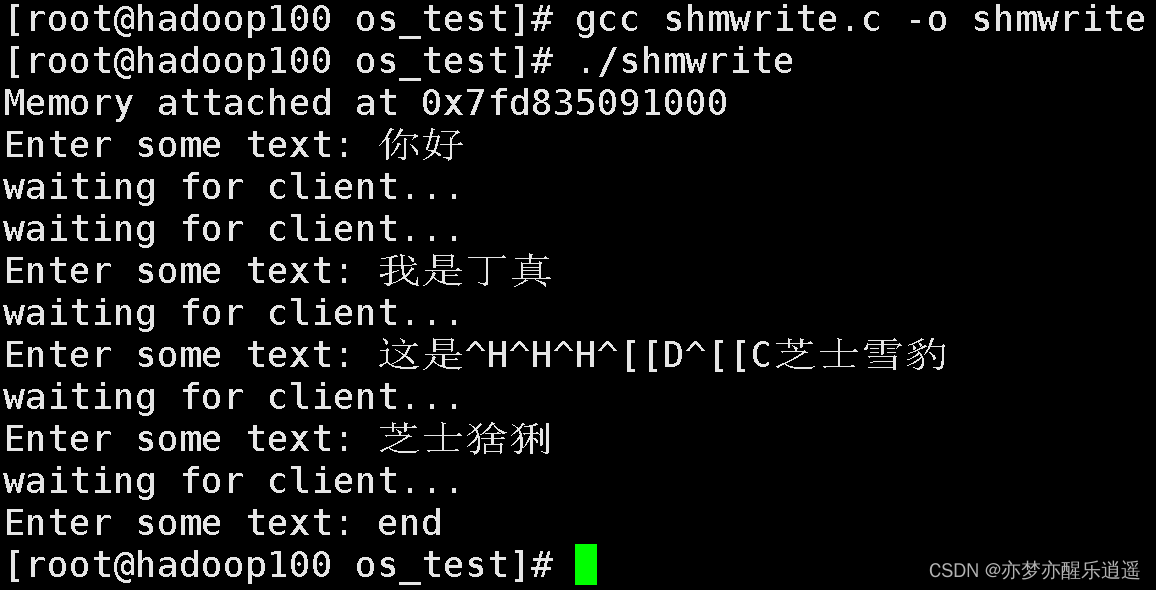
最后,新手可能疑惑,如何运行两个进程呢?其实就是开两个终端,一个运行shmwrite,一个运行shmread,当你在shmwrite终端向共享内存写一个串,shmwrite就会检测到,并且输出: