图注意力网络GATs - 《Graph Attention Networks》论文详解
目录
- 前言
- 正文
- 图注意力机制层(Graph Attentional Layer)
- 层的输入
- 注意力系数
- 归一化注意力系数
- 通过邻居节点更新自身节点
- 层的输出
- 附作者简介
前言
之前在推荐排序上开发的一个算法,取得了不错的效果。其中就用到了图神经网络模块,该模块的一部分思想源于GraphSage和GATs,因此对GATs的算法及代码理解还是比较深的,上一篇博文介绍了GraphSage:《GraphSage -《Inductive Representation Learning on Large Graphs》论文详解》,本文对GATs算法部分进行剖析。
GATs的核心思想就是 加权聚合周围邻居的信息。其原理与GraphSage的Mean aggregator基本一致,只是作者增加了一些Tricks。
正文
图注意力机制层(Graph Attentional Layer)
层的输入
层的输入是节点特征的集合:
h
=
{
h
⃗
1
,
h
⃗
2
,
…
,
h
⃗
N
}
,
h
⃗
i
∈
R
F
\bold{h}=\{\vec{h}_1,\vec{h}_2,\ldots,\vec{h}_N\},\vec{h}_i\in\mathbb{R}^F
h={h1,h2,…,hN},hi∈RF 其中,
N
N
N 是节点个数,
F
F
F 是每个节点输入的特征维度。
注意力系数
注意力系数是每两个直接邻居节点之间的权重,包括节点本身的注意力系数。(作者表示,使用直接邻居而不是整个图的两个节点之间求注意力系数,相当于注入了结构信息。)
e
i
j
=
a
(
W
h
⃗
i
,
W
h
⃗
j
)
=
L
R
e
L
U
(
a
⃗
T
[
W
h
⃗
i
∥
W
h
⃗
j
]
)
\begin{align} e_{ij}=a\Big(\bold{W}\vec{h}_i\,, \bold{W}\vec{h}_j\Big) =LReLU\Big( \vec{a}^T [ \bold{W}\vec{h}_i \| \bold{W}\vec{h}_j ] \Big) \end{align}
eij=a(Whi,Whj)=LReLU(aT[Whi∥Whj]) 其中,
a
→
T
∈
R
2
F
′
\overrightarrow{a}^T\in\mathbb{R}^{2F'}
aT∈R2F′,为全连接层
a
a
a 的参数;
W
∈
R
F
′
×
F
\bold{W}\in\mathbb{R}^{F'\times F}
W∈RF′×F 是对节点特征的一个线性变换的参数,目的是为了增强表达能力;
∥
\|
∥ 是concat操作;(1)式的结果生成的注意力系数
e
i
j
∈
R
e_{ij}\in\mathbb{R}
eij∈R,图示如下:

e
i
j
e_{ij}
eij 表示节点
j
j
j 的特征对节点
i
i
i 的重要性。
归一化注意力系数
为了使系数在不同节点之间易于比较,对注意力系数进行归一化。
α
i
j
=
s
o
f
t
m
a
x
j
(
e
i
j
)
=
e
x
p
(
e
i
j
)
∑
k
∈
N
i
e
x
p
(
e
i
k
)
\begin{align} \alpha_{ij}=softmax_j(e_{ij})={\frac {exp(e_{ij})} {\sum_{k\in\mathcal{N_i}} exp(e_{ik})}} \end{align}
αij=softmaxj(eij)=∑k∈Niexp(eik)exp(eij) 其中,
N
i
\mathcal{N}_{i}
Ni 是节点
i
i
i 的直接邻居节点集合。(2)式表示对节点
i
i
i 的直接邻居节点之间进行归一化。
综合(1)式可得归一化注意力系数的表达式为:
α
i
j
=
e
x
p
(
L
R
e
L
U
(
a
⃗
T
[
W
h
⃗
i
∥
W
h
⃗
j
]
)
)
∑
k
∈
N
i
e
x
p
(
L
R
e
L
U
(
a
⃗
T
[
W
h
⃗
i
∥
W
h
⃗
k
]
)
)
\begin{align} \alpha_{ij}={\frac {exp(LReLU\Big( \vec{a}^T [ \bold{W}\vec{h}_i \| \bold{W}\vec{h}_j ] \Big))} {\sum_{k\in\mathcal{N_i}} exp(LReLU\Big( \vec{a}^T [ \bold{W}\vec{h}_i \| \bold{W}\vec{h}_k ] \Big))}} \end{align}
αij=∑k∈Niexp(LReLU(aT[Whi∥Whk]))exp(LReLU(aT[Whi∥Whj]))
通过邻居节点更新自身节点
这里使用过注意力机制,对邻居进行加权求和,然后聚合到自己身上,其原理与GraphSage基本一致,只是作者做了一些trick。
-
加权求和
h ⃗ i ′ = σ ( ∑ j ∈ N i α i j W h ⃗ j ) \begin{align} \vec{h}_i'=\sigma\Big( \sum_{j\in\mathcal{N}_i} \alpha_{ij} \bold{W} \vec{h}_j \Big) \end{align} hi′=σ(j∈Ni∑αijWhj) 从上式可以看到,Attention的K,Q,V均来自输入节点,因此GATs的Attention是Self-Attention。 -
Multi-head Attention
使用 Multi-head 可以稳定 Self-Attention 的学习过程,然后将每个 head 的输出进行concat。
h ⃗ i ′ = ∥ k = 1 K σ ( ∑ j ∈ N i α i j k W k h ⃗ j ) \begin{align} \vec{h}_i^{\prime}=\|_{k=1}^K \sigma\left(\sum_{j \in \mathcal{N}_i} \alpha_{i j}^k \mathbf{W}^k \vec{h}_j\right) \end{align} hi′=∥k=1Kσ⎝ ⎛j∈Ni∑αijkWkhj⎠ ⎞ 其中, ∥ \| ∥ 是concat操作, α i j k \alpha_{i j}^k αijk 由第 k k k 个注意机制计算的归一化注意力系数;由于是concat,因此 h ⃗ i ′ ∈ R K F ′ \vec{h}_i^{\prime}\in\mathbb{R}^{KF^{\prime}} hi′∈RKF′ 。
在Transformer的Multi-Head Attention中,对拼接起来的Attention结果,使用一个线性变换再变化原来的维度。
作者认为在在网络的最终(预测)层concat多头注意力结果不合理,因此作者对多头进行了平均:
h ⃗ i ′ = σ ( 1 K ∑ k = 1 K ∑ j ∈ N i α i j k W k h ⃗ j ) \begin{align} \vec{h}_i^{\prime}= \sigma\left({\frac 1 K}\sum_{k=1}^{K}\sum_{j \in \mathcal{N}_i} \alpha_{i j}^k \mathbf{W}^k \vec{h}_j\right) \end{align} hi′=σ⎝ ⎛K1k=1∑Kj∈Ni∑αijkWkhj⎠ ⎞ 生成注意力系数及Multi-head Attention的解释如下图:
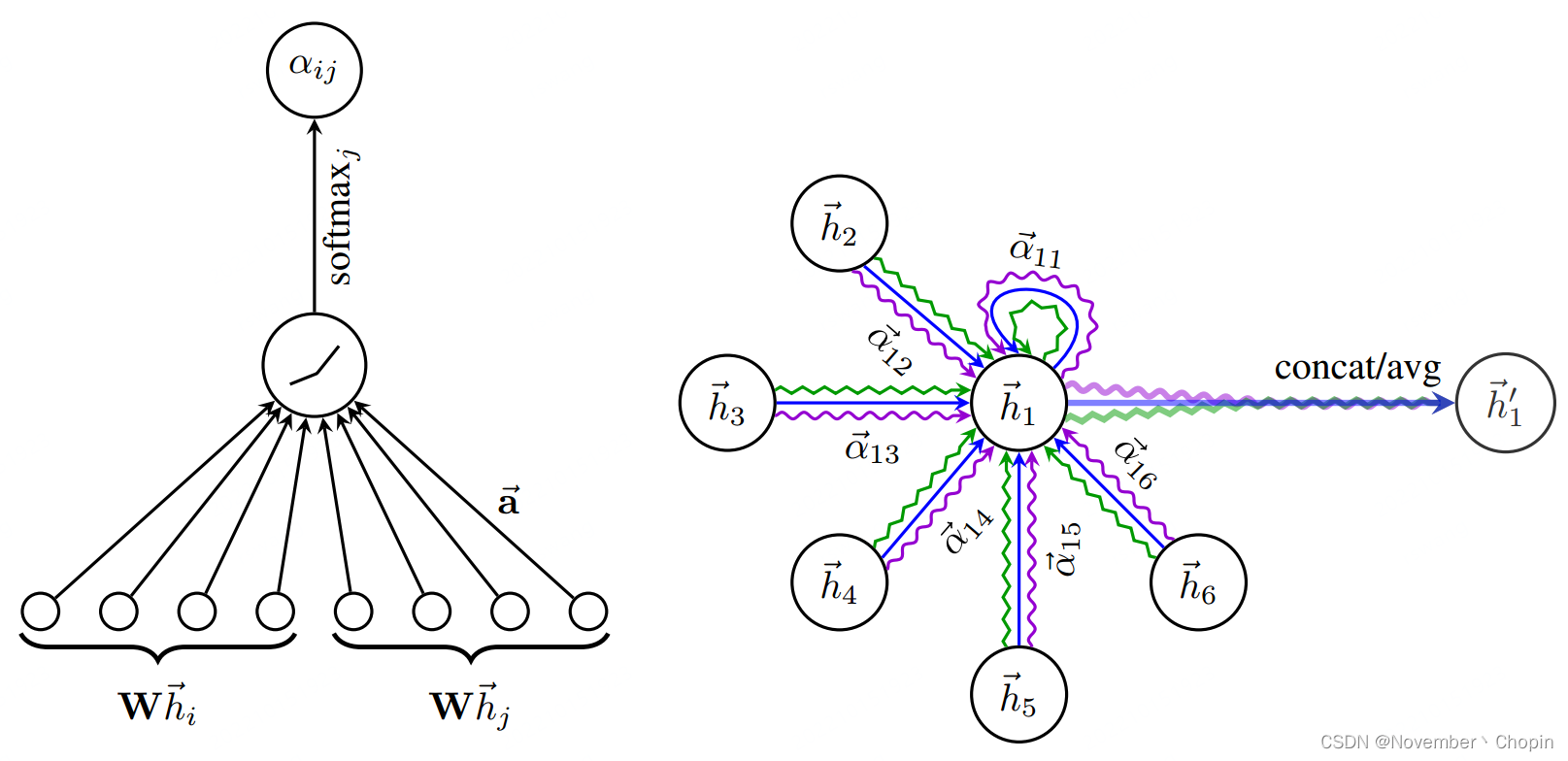
右图中不同颜色表示不同的head,一共有三个head。
层的输出
输出节点也是节点特征的集合:
h
′
=
{
h
→
1
′
,
h
→
2
′
,
…
,
h
→
N
′
}
,
h
→
i
′
∈
R
F
′
\bold{h}'=\{\overrightarrow{h}_1',\overrightarrow{h}_2',\ldots,\overrightarrow{h}_N'\},\overrightarrow{h}_i'\in\mathbb{R}^{F'}
h′={h1′,h2′,…,hN′},hi′∈RF′
F
′
F'
F′ 是每个节点输出的特征维度。
附作者简介
Petar Velickovic: 佩塔尔·维利奇科维奇,DeepMind的研究员,剑桥大学的附属讲师,剑桥大学克莱尔霍尔的副研究员,研究涉及几何深度学习,由于Petar的突出贡献,被公认为几何深度学习计划中的ELLIS学者。Petar 拥有剑桥大学(三一学院)的计算机科学博士学位。
Guillem Cucurull: 吉列姆·库库尔,Blue Prism研究工程师,从事机器学习和计算机视觉方面的工作。
Arantxa Casanova:蒙特利尔综合理工大学/蒙特利尔学习算法研究所博士生。目前在FAIR, Meta AI工作。
Adriana Romero:Meta AI的研究科学家,也是麦吉尔大学的兼职教授。研究重点是开发能够从多模态数据中学习的算法,推理概念关系,并利用主动和自适应数据采集策略。
Pietro Lio:剑桥大学计算机科学与技术系的正教授、人工智能小组的成员、剑桥人工智能医学中心的成员。研究兴趣集中在开发人工智能和计算生物学模型,以了解疾病的复杂性并解决个性化和精准医学问题。目前的重点是图神经网络建模。Pietro Lio拥有剑桥大学的硕士学位,复杂系统和非线性动力学博士学位(意大利佛罗伦萨大学信息学院工程系)和(理论)遗传学博士学位(意大利帕维亚大学)。
Yoshua Bengio:大牛!