【论文简述】High-Resolution Optical Flow from 1D Attention and Correlation(ICCV 2021)
一、论文简述
1. 第一作者:Haofei Xu
2. 发表年份:2021
3. 发表期刊:ICCV
4. 关键词:光流、代价体、自注意力、高分辨率、GRU
5. 探索动机:小分辨率对于网络性能有影响,并且现实场景中大多为高分辨率的图像,算法没有跟上需求。
对相关体的解释:An essential component in deep learning based optical flow frameworks is cost volume, which is usually computed by the dot product operation (also known as correlation) between two feature vectors. It stores the matching costs between each pixel in the source image and its potential correspondence candidates in the target image. By explicitly constructing a cost volume layer that encodes the search space, the network learns to better reason about the relative pixel displacements, as demonstrated by the superior performance of FlowNetC than FlowNetS that without such a layer.
- FlowNetC和PWC-Net的劣势:The original cost volume in FlowNetC is constructed in a single scale and it has difficulty in modeling large displacements due to the quadratic complexities with respect to the search window. PWC-Net migrates this problem by constructing multiple partial cost volumes in a coarse-to-fine warping framework. However, coarse-tofine methods tend to miss small objects since they might not be visible in the highly-downsampled coarse scales, and thus have little chance to be correctly estimated. Moreover, warping might introduce artifacts in occlusion regions, which may potentially hinder the network to learn correct correspondences.
- RAFT的劣势:RAFT maintains a single-resolution feature map and gradually estimates the flow updates in an iterative manner, eliminating several limitations of previous coarse-to-fine frameworks. One key component in RAFT is a 4D cost volume (H ×W ×H ×W ) that is obtained by computing the correlations of all pairs. Thanks to such a large cost volume, RAFT achieves striking performance on established benchmarks. Nevertheless, the 4D cost volume requirement makes it difficult to scale to very high-resolution inputs due to the quadratic complexity with respect to the image resolution. Although one can partially alleviate this problem by processing on downsampled images, some fine-grained details, which might be critical for some scenarios (e.g., ball sports and self-driving cars), will be inevitably lost in such a process. Furthermore, with the popularity of consumerlevel high-definition cameras, it is much easier than before to get access to high-resolution videos, which accordingly raises the demand to be able to process such high-resolution videos with high efficiency.
6. 工作目标:受到Transformers启发,是否可以实现高效且在高分辨率上运行的结构?
7. 核心思想:
We explore an innovative cost volume construction method which is fundamentally different from all existing methods.We show that cost volumes constructed using 1D correlations, despite somewhat counter-intuitive, can achieve striking flow estimation accuracy comparable to the state of the art.
8. 实验结果:可以在高分辨率上运行。
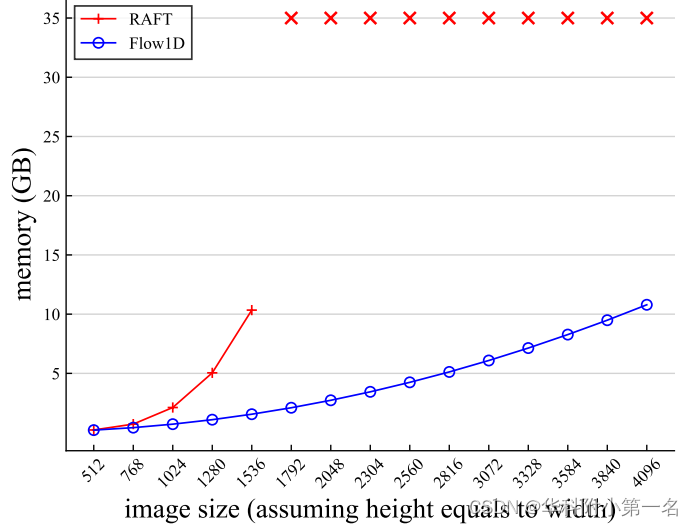
We reduce the complexity of all-pair correlation from O(H×W×H×W) to O(H×W×(H+W)), enabling our method to scale to very high-resolution inputs with significant less computation. For example, our method consumes 6× less memory than RAFT on 1080p(1080×1920) videos. We also show flow results on realworld 4K(2160×3840) resolution images and our method can handle images more than 8K(4320×7680) resolution on a GPU with 32GB memory. Meanwhile, the evaluation on Sintel and KITTI shows that the accuracy of our method is only slightly worse than RAFT but outperforms other methods such as FlowNet2 and PWC-Net.
9.论文&代码下载:
https://openaccess.thecvf.com/content/ICCV2021/papers/Xu_High-Resolution_Optical_Flow_From_1D_Attention_and_Correlation_ICCV_2021_paper.pdf
https://github.com/haofeixu/flow1d
二、实现方法
1. 光流分解
光流本质上是一个二维搜索问题,但由于搜索窗口的二次复杂度,直接在二维图像空间上搜索非常大的位移,计算上难以实现。例如,搜索范围[−50,50]的潜在搜索空间可达104像素。对于高分辨率图像来说,这个问题更加明显。
为了在高分辨率图像上实现光流估计,作者观察到2D搜索空间可以在两个1D方向上近似。如下所示,为了实现蓝色点与红色点的二维对应建模效果,可以先将红色点的信息传播到与蓝色点在同一行的绿色点。然后沿着水平方向进行一维搜索,可以捕获红点的信息。
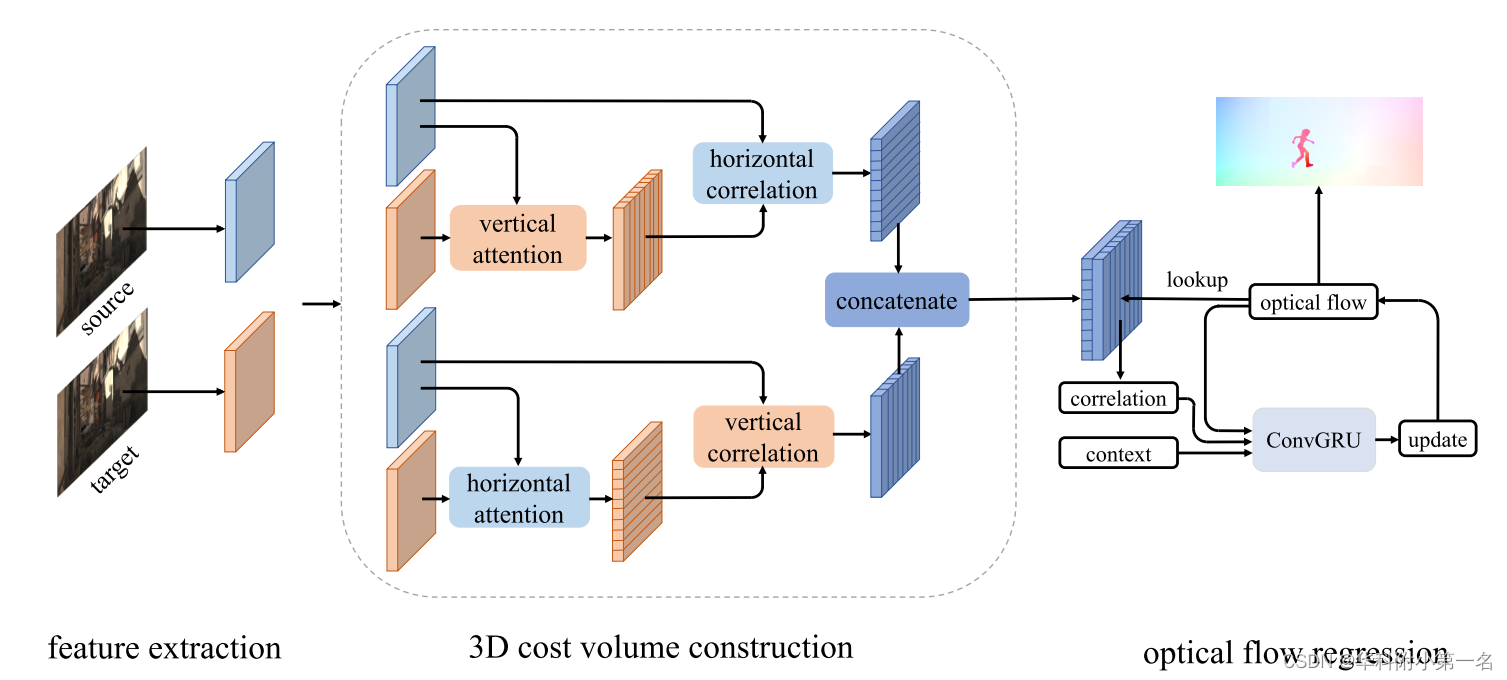
基于此,提出了在正交方向上对二维光流进行分解,得到1D注意力和1D相关,以实现对高分辨率图像的大位移搜索。对于蓝点的对应点(红点),首先执行在垂直方向上的1D注意力,计算同一列中的像素的加权和,红点的信息传播到与蓝点在同一行的绿点。然后在水平方向上进行简单的1D相关就可以达到二维搜索效果。由此产生水平的3D代价体。通过交换注意力和相关的方向,可以获得垂直的3D代价体,两个代价体连接起来用于光流回归。
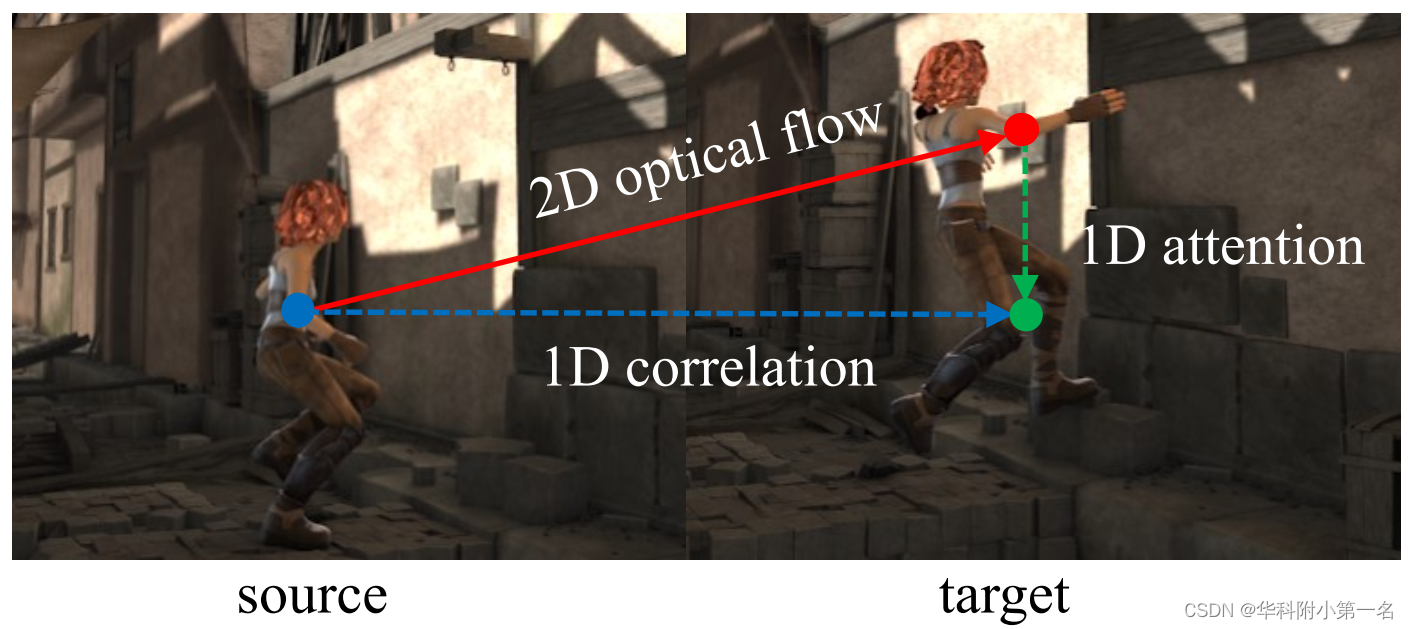
接下来,详细介绍1D垂直注意力和1D水平相关的代价体结构。
2. 1D注意力
源特征和目标特征F1, F2∈H×W×D,目标是生成一个新的特征Fˆ2,其中每个特征向量都知道F2中位于同一列点的特征。这样,就可以沿着水平方向进行简单的1D搜索,达到2D对应建模的效果。具体地说,将Fˆ2定义为F2列特征的线性组合:
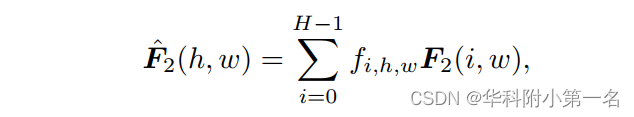
其中h = 0,1,···,H -1,w = 0,1,···,W−1,Fˆ2(h, w)为位置(h, w)的输出特征向量,fi,h,w为组合权值。因此关键在于如何找到fi,h,w,可以适当地聚合列的信息,以帮助后续的1D搜索。受Transformers在建模长距离依赖关系的启发,使用注意力机制的组合系数。
然而,与最初计算所有对相似性的注意力不同,只在轴方向执行1D注意力。如下图所示,注意力运算的目标是将红点(蓝点对应)的信息传播到与蓝点在同一行的绿点上。为了实现这一点,一种可行的方案是在源特征和目标特征的同一列之间应用1D交叉注意力操作,使目标特征聚合依赖于源特征。但是,源图像中的同一列可能不包含相应的像素(蓝色点),导致很难学习正确的聚合。为了解决这一问题,在计算交叉注意力之前,我们首先在源特征的水平方向上进行1D自注意力操作,将源图像上对应点的信息传播到整行。
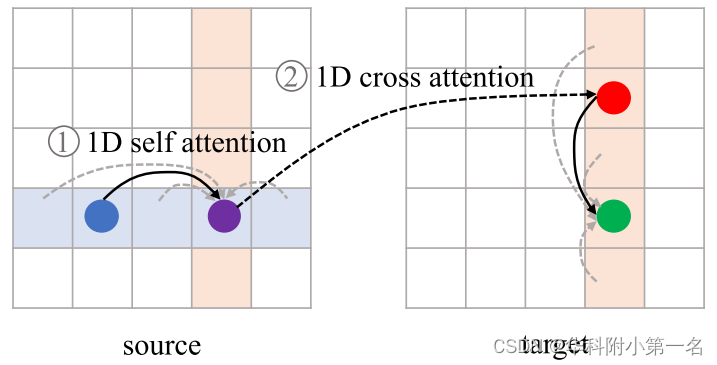
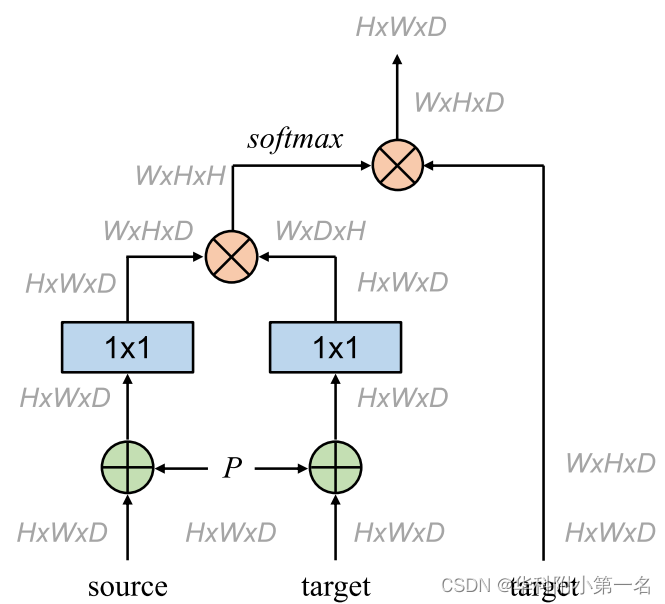
1D垂直交叉注意力的计算图如下图,输入为自注意力源特征和最初的目标特征。在注意力计算中引入位置信息P∈H×W×D,其中P为固定的二维位置编码。
- 1. 使用两个1×1卷积将F1+P和F2+P投影为嵌入空间的F~1和F~2;
- 2. 将F~1、F~2分别重塑为W×H×D、W×D×H;
- 3. 对最后两个维度进行矩阵相乘,得到垂直方向上的注意力矩阵W×H×H;
- 4. 对最后一维用softmax函数归一化,得到注意矩阵A∈W×H×H;
- 5. 通过在最后两个维度上将A与的重塑目标特征(W×H×D)计算矩阵相乘,得到注意力特征Fˆ2;
- 6. 将W×H×D矩阵重塑为H×W×D,得到最终的特征Fˆ2。
经过1D交叉注意力操作后,Fˆ2中的每个位置都编码了同一列中的位置信息。该过程可以类似地应用于1D水平自注意力计算,通过将目标特征替换为源特征并在宽度维度上进行矩阵乘法。
3. 1D相关
利用垂直聚合的特征Fˆ2,沿着水平方向进行简单的一维搜索,构造3D代价体C∈H×W×(2R+1),用R表示沿水平方向的搜索半径:
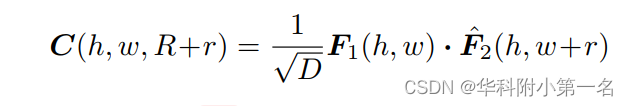
式中·表示点积,r∈{−R,−R+1··,0,···,R−1,R},1/√1D是避免点积后值过大的归一化因子。在实现中,通过在宽度维度上对F1和Fˆ2进行矩阵乘法预先计算了大小为H×W×W的3D代价体。然后以搜索半径R对三维代价体进行查找,就可以得到上式的等效形式。
虽然只执行1D相关,但由于注意力操作,该方法可以建模2D对应关系。具体而言,代价体构建方法的理论搜索范围为(2R+1)(H+W)−(2R+1)2。将Eq(1)代入Eq(2)即可证明:

其中fi,h,w+r是由1D注意力操作定义,i=0,1,···H−1,r=−R,−R+1,···,0 ,···,R−1,R。位置(h, w)的搜索范围h到图像高度,w到最大搜索半径r,所以垂直注意力和水平相关的理论搜索范围为H(2R+1),同样可得水平注意力和垂直相关的代价体C=H×W×(2R+1),其中
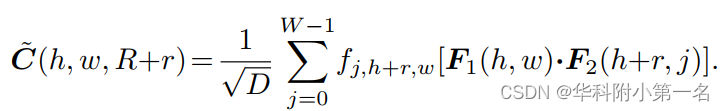
在这种情况下,理论搜索范围为W(2R+1)。将这两个代价体连接起来得到形状为H×W×2(2R + 1)的代价体,理论搜索范围为(2R+1)(H+W)−(2R+1)2,其中(2R+1)2是这两个代价体的重叠面积。
相比之下,以往基于局部窗口的方法通常构造形状为H×W×(2R+1)2的代价体,搜索范围为(2R+1)2。因此,该方法具有更大的理论搜索范围,同时保持更小的代价体。
4. 光流回归框架
用RAFT框架。对于源图像和目标图像I1和I2,首先使用共享的卷积主干提取8×下采样特征,然后利用这些特征分别构建了具有垂直注意力、水平相关和水平注意力、垂直相关的3D代价体。然后将这两个代价体连接起来进行光流迭代更新。在每次迭代中,通过当前光流估计查找3D代价体,生成一组相关值。延续RAFT,通过另一个网络从源图像中提取上下文特征。相关,估计的光流和上下文特征,输入至ConvGRU产生光流更新,加入到当前光流估计中。
查找操作是指用当前光流估计索引预先计算的代价体。具体来说,如果当前光流估计为f=(fx, fy),则像素位置(h, w)的查找中心变为(h+fy, w+fx)。在R的搜索范围内对三维代价体进行水平和垂直索引,得到两个三维代价体(H × W × (2R + 1)),并将它们连接进行光流回归。
4. 实验
4.1. 数据集
FlyingThings、Sintel、KITTI-2015、HD1K
4.2. 实现
通过PyTorch实现,使用AdamW作为优化器。训练策略延续RAFT。查找中的搜索范围R设置为32,对应原始图像分辨率中的256像素。
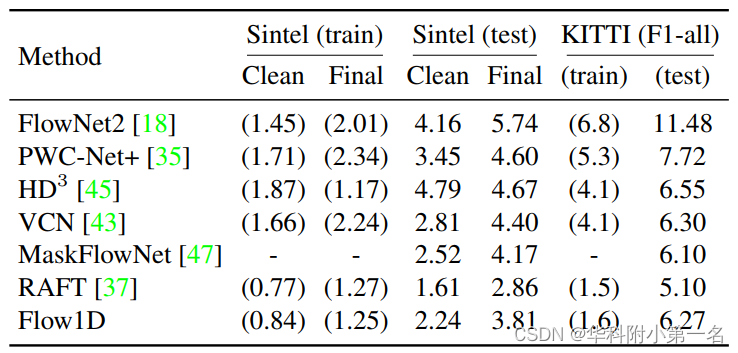
4.3. 基准结果
4.4. 消融实验
换代价体:精度不如RAFT及原因:In terms of accuracy, our method is higher than FlowNet2 and PWC-Net, especially on KITTI dataset, but is inferior to RAFT. Exhaustively constructing a large 4D cost volume is indeed advantageous to obtain highly accurate flow in RAFT, while our 3D cost volume may have the risk of missing relevant pixels. Although most pixels are able to find the right correspondences, there are few noises in the attention maps that cause missing pixels. It’s possible that a better design of the attention matrix computation will further improve the performance.
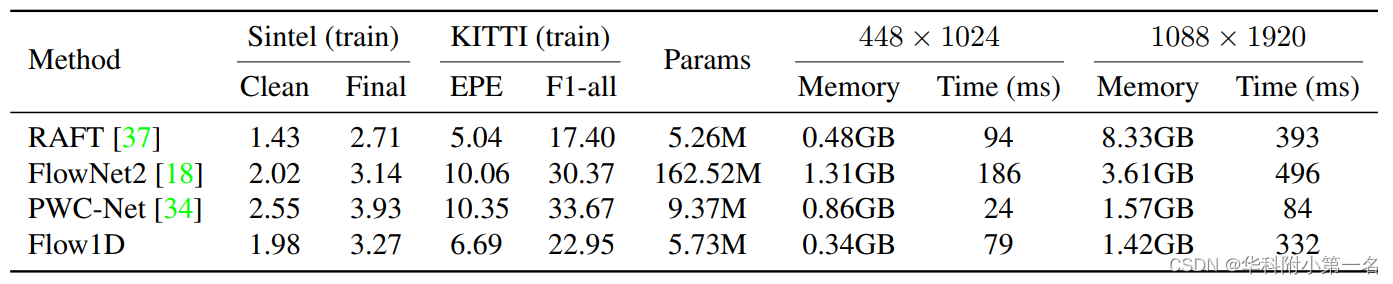
4.5. 内存
输入尺寸为H的特征图×W×D,在RAFT中构建一个4D体的计算复杂度为O((HW)2D),该方法两个3D代价体为O(HW(H+W)D)。下图中测量了不同输入分辨率下的实际内存消耗,该方法能够扩展到超过8K分辨率(4320 × 7680,内存消耗为21.81GB)的图像,而RAFT即使在具有32GB内存的高端GPU上也会快速出现内存不足的问题。