视觉目标检测大模型套件detrex-调研
A.写在前面
与NLP大模型相比,CV大模型目前还没有一套较为系统的整合方式。个人认为这主要是:
1.CV大模型的各个下游任务之间的差异性较大导致的。
2.可能也与目前CV领域大模型的数量较少有关。
3.对于CV任务,其落地场景一般对内存和计算速度的要求较高,可能目前仍偏向于使用普通量级模型。
偶然发现这个套件detrex,该套件只针对视觉中的目标检测任务组织,细节非常丰富,值得借鉴。
B.detrex介绍
1.概述
项目地址:GitHub - IDEA-Research/detrex: IDEA Open Source Toolbox for Transformer Based Object Detection Algorithms
detrex是一个开源工具箱,提供了SOTA的基于transformer的检测算法。
建立在Detectron2之上,其模块设计部分借鉴了MMDetection和DETR。
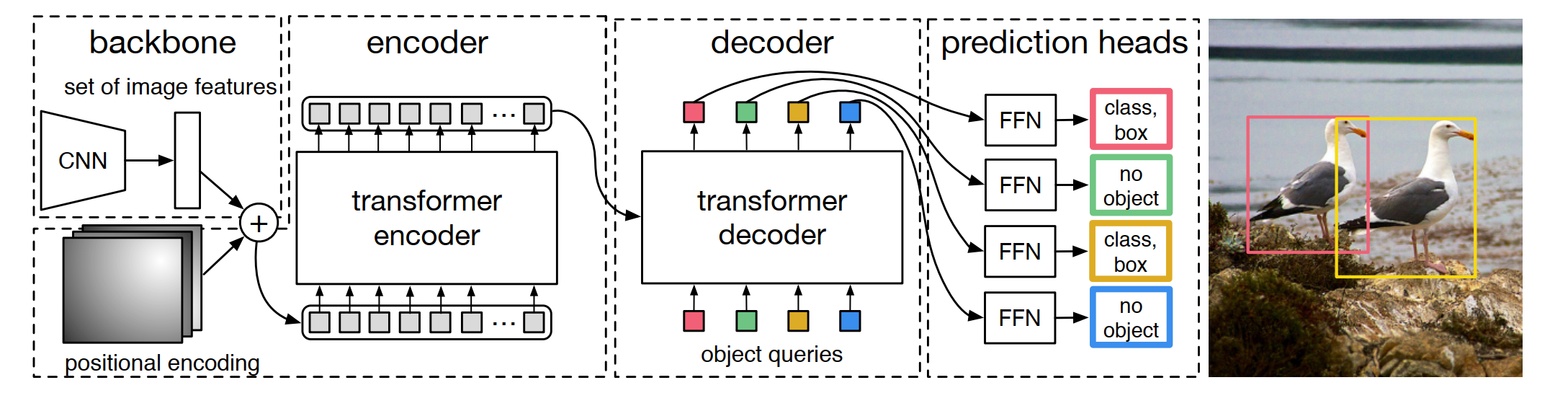
2. 主要特点
(1). 模块化设计。detrex将基于Transformer的目标检测框架分解为各种组件,帮助用户轻松构建自己的定制模型。后面我们看一下它的目录,detrex将基于Transformer的DETR类的目标检测模型拆分并同类方法重新组合,构建了清晰框架。
(2). SOTA模型。detrex提供了一系列基于Transformer的检测算法,包括DINO,它以63.3mAP达到DETR类模型的SOTA!
(3). 易于使用。底特律的设计重量轻,使用方便:
a. LazyConfig System可实现更灵活的语法和更清晰的配置文件。
b. 根据detectron2 lazyconfig_train_net.py修改的轻量级训练引擎。
3.目录结构
- Tutorials
- Installation
- Getting Started with detrex
- Config System
- Convert Pretrained Models
- Download Pretrained Backbone Weights
- Using Pretrained Backbones
- Practical Tools and Scripts
- Model Zoo
- Frequently Asked Questions
- API Documentation
- detrex.config
- get_config()
- try_get_key()
- detrex.data
- DatasetMapper
- detrex.layers
- BaseTransformerLayer
- ConditionalCrossAttention
- ConditionalSelfAttention
- ConvNormAct
- FFN
- GenerateDNQueries
- LayerNorm
- MLP
- MultiheadAttention
- PositionEmbeddingLearned
- PositionEmbeddingSine
- TransformerLayerSequence
- apply_box_noise()
- apply_label_noise()
- box_cxcywh_to_xyxy()
- box_iou()
- box_xyxy_to_cxcywh()
- generalized_box_iou()
- get_sine_pos_embed()
- masks_to_boxes()
- detrex.modeling
- backbone
- neck
- matcher
- losses
- detrex.utils
- get_world_size()
- interpolate()
- inverse_sigmoid()
- is_dist_avail_and_initialized()
- Change Log
- v0.1.0
我将其中的 API Documentation 重点展开,看下detrex的组织形式大概就能了解该套件的特性和使用形式。简单说其实就是将以DETR这类模型为基础的目标检测模型中的相似部分抽离出来,并评估规划为配置文件(detrex.config)、数据相关(detrex.data)、检测模型常用层(detrex.layers)、常规模型构建部分(detrex.modeling)和额外工具(detrex.utils)几个部分,放置于相应模块中。
C.顺便白嫖一波论文集
整理地址:https://github.com/IDEA-Research/awesome-detection-transformer