Milvus 2.1 版本更新 - 简单可信赖、性能持续提升
-
文档更新于 2.1.4 版本发布之际,很高兴和大家分享 Milvus 的新变化和产品的成长。
-
Zilliz 合伙人兼技术总监 栾小凡
继年初发布 Milvus 2.0 版本之后,在数百位 Milvus 社区贡献者六个月的共同努力下,我们在早些时候发布了 Milvus 2.1 版本,经过两个月的数次迭代,版本趋于稳定,被国内外头部厂商信任和选择使用。
在此次大版本更新中,最为重要的两个关键词莫过于:易用性和性能。
为了能够打通算法工程师笔记本到海量向量召回生产场景的“最后一公里”,在这个令人激动的版本中,我们除了在程序性能、可扩展性、安全性、可观测性方面做出了诸多改进之外,还增加了以下新特性:字符串数据类型、Kafka 消息队列、Embedded 方式运行 Milvus。
性能提升:3.2 倍只是开始
相较于传统 KNN 检索,Milvus 此前提供的 ANN 检索方式虽然已经带来了质的飞跃。但是,当用户面向亿级大规模向量数据的召回场景时,吞吐量和延迟依旧存在很大的挑战。
在 Milvus 2.1 中,我们主要进行了五个方面的功能改进和性能提升。
更高效的路由协议:5ms 检索延迟
在 Milvus 2.1 中,我们设计了全新的路由协议,并在检索链路中去除了对消息队列的依赖,让小数据集场景下的检索延迟得到了大幅降低。结果显示,当前版本的 Milvus 在百万数据规模的测试中,延迟能够达到 5ms 左右,足以满足搜索、推荐等在线关键链路对于延迟的苛刻要求。
更高性能的并发模型:3.2 倍性能提升
在 Milvus 2.1 中,我们对并发模型也进行了调整。在当前版本中,我们引入了新的代价评估模型和并发调度器。实现了两个关键能力:并发控制和小查询合并。
前者保障了我们既不会存在大量并发请求争抢 CPU 和缓存资源的情况,也不会因为并发太少而导致 CPU 无法被完全利用;后者则是通过在调度器层面智能地合并请求参数一致的小 nq 查询,能够解决在查询 nq 较小、并发又非常高的场景下 Milvus 的性能压力。在这个场景下,业务不需要修改任何一行代码就能够获得 3.2 倍的性能提升。
完整的性能测试报告目前已经在官网公开:《Milvus 2.1 Benchmark Test Report》。
安全高效的内存多副本机制
在 Milvus 2.1 中,我们引入了内存多副本机制。除了能够提升系统在小数据规模下的扩展性和可用性之外,还能够解决读 QPS 较高场景下的性能压力。
这个新机制类似传统数据库中的只读副本功能,能够通过加机器来简单实现系统的横向扩展。特别适合众多向量检索应用场景中的推荐系统应用场景,满足常规推荐系统在小数据集场景下提供远超单机性能限制的 QPS 的需求。
在接下来的版本演进中,我们将基于多副本机制进一步实现 Hedged Read 机制,让系统能够在“故障恢复场景”下避开有问题的副本,快速访问数据和功能正常的副本,充分利用内存冗余提升系统的可用性。
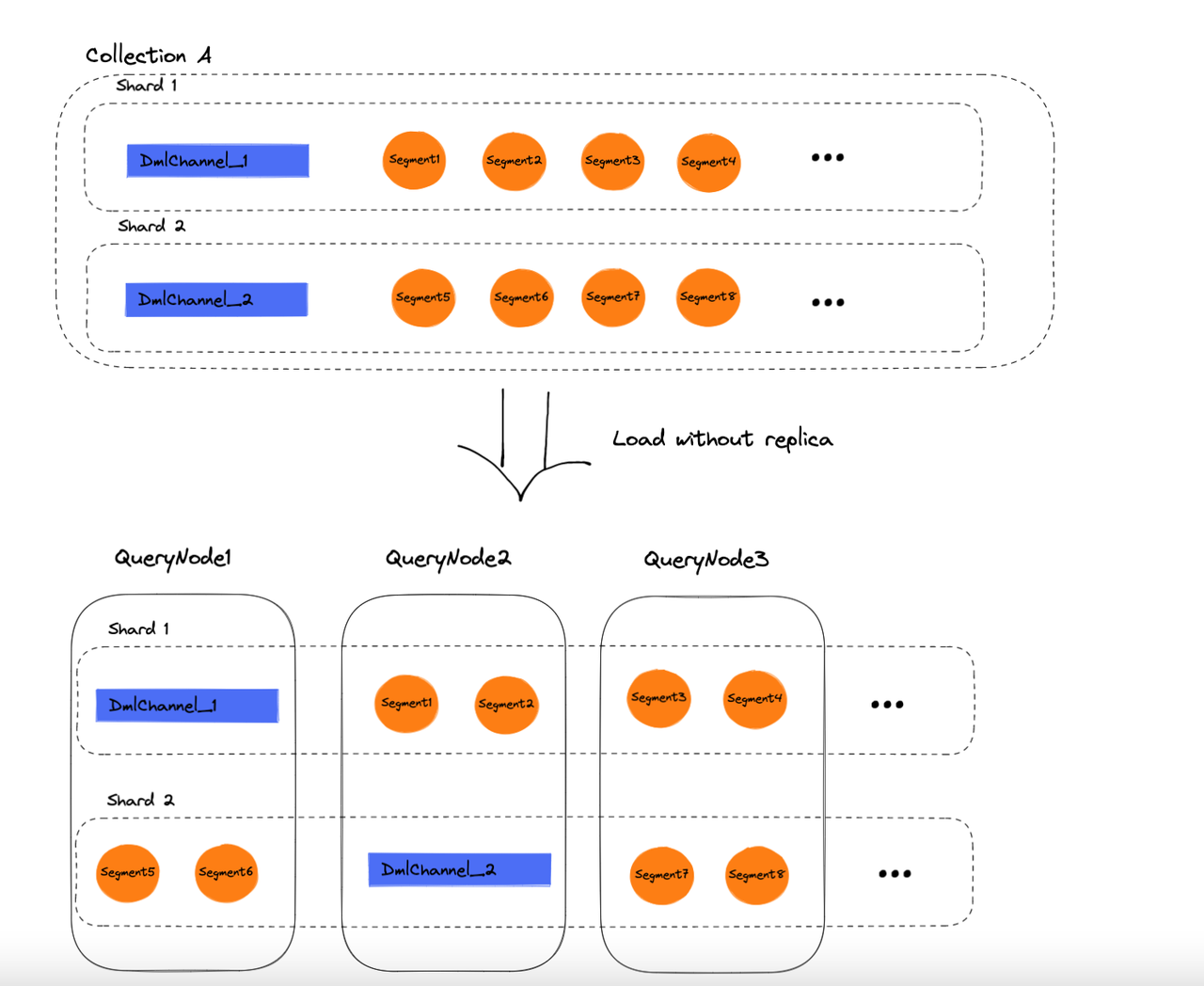
高性能的数据加载实现
Milvus 2.1 中,最后一个性能提升的改动来自于对数据加载的优化。在当前版本的 Milvus 中,我们引入了 Zstandard (zstd),对 Binlog 进行实时数据压缩,大幅减少了数据加载过程中的网络开销,以及对象存储和消息队列中数据所占用的空间。
除此之外,通过引入 Golang 协程池技术,Milvus 实现了在控制内存资源最大使用量的情况下,并发加载 Segment,同样大幅降低了故障恢复时间,以及加载数据所需要的时间。
重磅功能:字符串类型支持与标量索引
向量数据库场景中最常见的用户需求之一是属性过滤,例如“寻找价格在 200~300 元区间与某个用户喜好相似的商品”、“找到带有向量数据库这个关键词并和云原生话题相关的文章”。
在新版本的 Milvus 中,我们支持了变长字符串的数据类型,用户可以将字符串类型用做主键,并作为结果进行输出。当然,也可以基于字符串类型实现比较过滤和前缀匹配。
为了解决以往数据过滤慢的问题,新版本中还增加了针对标量数据的倒排索引实现。
我们基于 Succinct MARISA-trie 实现了字符串类型的倒排索引,能够以极低的内存消耗将全部数据加载进内存,快速进行字符串的比较过滤和前缀匹配操作。相比较 Python 字典的实现,我们仅需要十分之一的内存消耗,就能够完成全部数据的加载并提供查询能力。
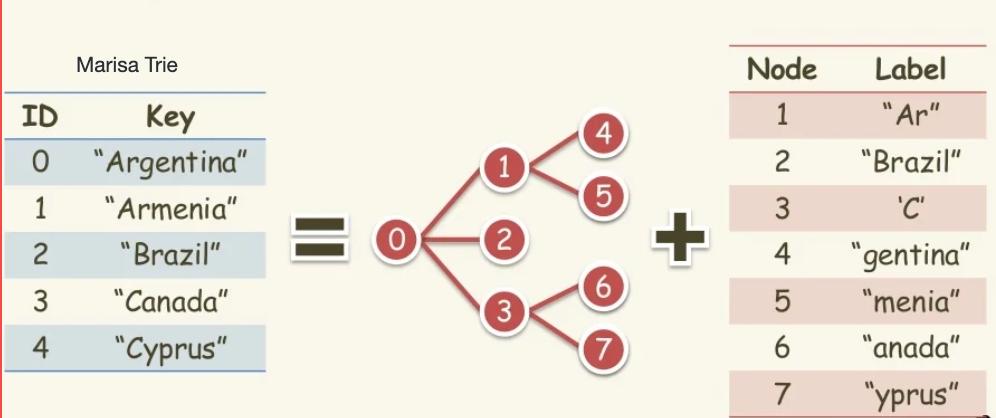
在未来的版本中,Milvus 将会持续投入标量查询相关的功能建设,支持更多标量索引类型以及查询算子,提供基于磁盘存储的标量查询能力,持续降低标量数据的存储和使用成本。
易用性提升:让系统更好用
Milvus 支持使用 Kafka 作为消息队列
让 Milvus 使用 Apache Kafka 作为流式存储组件,一直以来是 Milvus 社区中用户呼声最高的功能之一。
得益于 Milvus 2.x 版本中更好的抽象封装,以及来自 Confluent 公司贡献的 Go Kafka SDK,在 Milvus 2.1 版本中,我们提供了一个新的功能:用户可以自行选择配置使用 Pulsar 或者 Kafka 作为流式存储组件。
生产级别的 Java SDK 正式发布
经过测试团队的严密测试,Milvus Java SDK 正式发布。Java SDK 具备了与 Python SDK 完全一致的能力,并且拥有更好的并发性能。在接下来的产品规划中,我们将和社区的同学们一同完善 Java SDK 的文档及使用案例。
晚些时候,Go SDK 和 RESTful SDK 也将进入生产级别的版本发布,敬请期待!
可观测性和可维护性提升
Milvus 2.1 增加了重要的性能监控指标,如:向量插入计数、检索延迟记录、检索吞吐量记录、节点内存开销、CPU 资源开销。
此外,在新版本中,我们对于日志输出也进行了大幅优化,现在用户能够通过调整日志级别,减少日志打印量,更加方便直观地观测系统的运行状况。
Embedded Milvus
Milvus 的出现极大地简化了海量大规模数据检索场景下检索服务的部署。然而,不论是使用 Docker 还是 K8s ,对于想要在更小规模数据上完成算法验证的数据科学家来说,系统部署的过程依旧比较复杂。
随着 Embedded Milvus 的引入,我们现在可以使用 pip 来完成 Milvus 的安装,如同使用 PyRocksDB 和 PySQLite 一样。Embedded Milvus 支持单机和集群版 Milvus 的所有功能,让用户能够在无需修改任何代码的情况下,轻松地从笔记本电脑切换到分布式生产环境,大大减少算法工程师使用 Milvus 进行原型验证的成本。
心动不如行动:体验开箱即用的向量检索
除了以上内容之外,我们在稳定性和可扩展性上也做出了很大的提升,期待您的使用!
如果您在使用过程中遇到了问题,或者有好的建议,欢迎与我们联系!
文章补充资料
-
Milvus 2.1 版本 Release Notes
-
Milvus 安装文档
如果你觉得我们分享的内容还不错,请不要吝啬给我们一些鼓励:点赞、喜欢或者分享给你的小伙伴!
活动信息、技术分享和招聘速递请关注:你好👋,数据探索者
如果你对我们的项目感兴趣请关注:
用于存储向量并创建索引的数据库 Milvus
用于构建模型推理流水线的框架 Towhee