python学习笔记---进程和线程【廖雪峰】
进程和线程
现在,多核CPU已经非常普及了,但是,即使过去的单核CPU,也可以执行多任务。由于CPU执行代码都是顺序执行的,那么,单核CPU是怎么执行多任务的呢?
答案就是操作系统轮流让各个任务交替执行,任务1执行0.01秒,切换到任务2,任务2执行0.01秒,再切换到任务3,执行0.01秒……这样反复执行下去。表面上看,每个任务都是交替执行的,但是,由于CPU的执行速度实在是太快了,我们感觉就像所有任务都在同时执行一样。
真正的并行执行多任务只能在多核CPU上实现,但是,由于任务数量远远多于CPU的核心数量,所以,操作系统也会自动把很多任务轮流调度到每个核心上执行。
对于操作系统来说,一个任务就是一个进程(Process),比如打开一个浏览器就是启动一个浏览器进程,打开一个记事本就启动了一个记事本进程,打开两个记事本就启动了两个记事本进程,打开一个Word就启动了一个Word进程。
有些进程还不止同时干一件事,比如Word,它可以同时进行打字、拼写检查、打印等事情。在一个进程内部,要同时干多件事,就需要同时运行多个“子任务”,我们把进程内的这些“子任务”称为线程(Thread)。
由于每个进程至少要干一件事,所以,一个进程至少有一个线程。当然,像Word这种复杂的进程可以有多个线程,多个线程可以同时执行,多线程的执行方式和多进程是一样的,也是由操作系统在多个线程之间快速切换,让每个线程都短暂地交替运行,看起来就像同时执行一样。当然,真正地同时执行多线程需要多核CPU才可能实现。
多任务的实现有3种方式:
- 多进程模式;
- 多线程模式;
- 多进程+多线程模式。
线程是最小的执行单元,而进程由至少一个线程组成。如何调度进程和线程,完全由操作系统决定,程序自己不能决定什么时候执行,执行多长时间。
多进程和多线程的程序涉及到同步、数据共享等问题
多进程
Unix/Linux操作系统提供了一个fork()系统调用,它非常特殊。普通的函数调用,调用一次,返回一次,但是**fork()调用一次,返回两次**,因为操作系统自动把当前进程(称为父进程)复制了一份(称为子进程),然后,分别在父进程和子进程内返回。
子进程永远返回0,而父进程返回子进程的ID。这样做的理由是,一个父进程可以fork出很多子进程,所以,父进程要记下每个子进程的ID,而子进程只需要调用getppid()就可以拿到父进程的ID。
Python的os模块封装了常见的系统调用,其中就包括fork,可以在Python程序中轻松创建子进程:
import os
print('Process (%s) start...' % os.getpid())
# Only works on Unix/Linux/Mac:
pid = os.fork()
if pid == 0:
print('I am child process (%s) and my parent is %s.' % (os.getpid(), os.getppid()))
else:
print('I (%s) just created a child process (%s).' % (os.getpid(), pid))
运行结果如下:
Process (876) start...
I (876) just created a child process (877).
I am child process (877) and my parent is 876.
由于Windows没有fork调用,上面的代码在Windows上无法运行。
有了fork调用,一个进程在接到新任务时就可以复制出一个子进程来处理新任务,常见的Apache服务器就是由父进程监听端口,每当有新的http请求时,就fork出子进程来处理新的http请求。
multiprocessing
由于Windows没有fork调用,在Windows上使用multiprocessing模块编写多进程的程序。
multiprocessing模块提供了一个Process类来代表一个进程对象,下面的例子演示了启动一个子进程并等待其结束:
from multiprocessing import Process
import os
# 子进程要执行的代码
def run_proc(name):
print('Run child process %s (%s)...' % (name, os.getpid()))
if __name__=='__main__':
print('Parent process %s.' % os.getpid())
p = Process(target=run_proc, args=('test',)) # 创建子进程时,只需要传入一个执行函数和函数的参数
print('Child process will start.')
p.start() # 用`start()`方法启动
p.join() # 可以等待子进程结束后再继续往下运行,通常用于进程间的同步
print('Child process end.')
执行结果如下:
Parent process 928.
Child process will start.
Run child process test (929)...
Process end.
创建子进程时,只需要传入一个执行函数和函数的参数,创建一个Process实例,用start()方法启动,这样创建进程比fork()还要简单。
join()方法可以等待子进程结束后再继续往下运行,通常用于进程间的同步。
Pool
如果要**启动大量的子进程**,可以用进程池的方式批量创建子进程:
from multiprocessing import Pool
import os, time, random
def long_time_task(name):
print('Run task %s (%s)...' % (name, os.getpid()))
start = time.time()
time.sleep(random.random() * 3)
end = time.time()
print('Task %s runs %0.2f seconds.' % (name, (end - start)))
if __name__=='__main__':
print('Parent process %s.' % os.getpid())
p = Pool(7) # 同时执行4个进程
for i in range(4):
p.apply_async(long_time_task, args=(i,))
print('Waiting for all subprocesses done...')
'''
对Pool对象调用join()方法会等待所有子进程执行完毕,所以调用join()之前必须先调用close(),调用close()之后就不能继续添加新的Process了
'''
p.close()
p.join()
print('All subprocesses done.')
执行结果如下:
Parent process 669.
Waiting for all subprocesses done...
Run task 0 (671)...
Run task 1 (672)...
Run task 2 (673)...
Run task 3 (674)...
Task 2 runs 0.14 seconds.
Run task 4 (673)...
Task 1 runs 0.27 seconds.
Task 3 runs 0.86 seconds.
Task 0 runs 1.41 seconds.
Task 4 runs 1.91 seconds.
All subprocesses done.
代码解读:
对Pool对象调用join()方法会等待所有子进程执行完毕,调用join()之前必须先调用close(),调用close()之后就不能继续添加新的Process了。
请注意输出的结果,task 0,1,2,3是立刻执行的,而task 4要等待前面某个task完成后才执行,这是因为Pool的默认大小在我的电脑上是4,因此,最多同时执行4个进程。这是Pool有意设计的限制,并不是操作系统的限制。如果改成:p = Pool(5)就可以同时跑5个进程。
由于Pool的默认大小是CPU的核数,如果你不幸拥有8核CPU,你要提交至少9个子进程才能看到上面的等待效果。
子进程【subprocess模块之Popen】
很多时候,子进程并不是自身,而是一个外部进程。我们创建了子进程后,还需要控制子进程的输入和输出。
subprocess模块可以让我们非常方便地启动一个子进程,然后控制其输入和输出。
[]:
进程间通信
Process之间肯定是需要通信的,操作系统提供了很多机制来实现进程间的通信。Python的multiprocessing模块包装了底层的机制,提供了Queue、Pipes等多种方式来交换数据。
以Queue为例,在父进程中创建两个子进程,一个往Queue里写数据,一个从Queue里读数据:
from multiprocessing import Process, Queue
import os, time, random
# 写数据进程执行的代码:
def write(q):
print('Process to write: %s' % os.getpid())
for value in ['A', 'B', 'C']:
print('Put %s to queue...' % value)
q.put(value)
time.sleep(random.random())
# 读数据进程执行的代码:
def read(q):
print('Process to read: %s' % os.getpid())
while True:
value = q.get(True)
print('Get %s from queue.' % value)
if __name__=='__main__':
# 父进程创建Queue,并传给各个子进程:
q = Queue()
pw = Process(target=write, args=(q,))
pr = Process(target=read, args=(q,))
# 启动子进程pw,写入:
pw.start()
# 启动子进程pr,读取:
pr.start()
# 等待pw结束:
pw.join()
# pr进程里是死循环,无法等待其结束,只能强行终止:
pr.terminate()
Process to write: 50563
Put A to queue...
Process to read: 50564
Get A from queue.
Put B to queue...
Get B from queue.
Put C to queue...
Get C from queue.
在Unix/Linux下,multiprocessing模块封装了fork()调用,使我们不需要关注fork()的细节。由于Windows没有fork调用,因此,multiprocessing需要“模拟”出fork的效果,父进程所有Python对象都必须通过pickle序列化再传到子进程去,所以,如果multiprocessing在Windows下调用失败了,要先考虑是不是pickle失败了。
多线程
多任务可以由多进程完成,也可以由一个进程内的多线程完成。
我们前面提到了进程是由若干线程组成的,一个进程至少有一个线程。
由于线程是操作系统直接支持的执行单元,因此,高级语言通常都内置多线程的支持,Python也不例外,并且,Python的线程是真正的Posix Thread,而不是模拟出来的线程。
Python的标准库提供了两个模块:_thread和threading,_thread是低级模块,threading是高级模块,对_thread进行了封装。绝大多数情况下,我们只需要使用threading这个高级模块。
启动一个线程就是把一个函数传入并创建Thread实例,然后调用start()开始执行:
import time, threading
# 新线程执行的代码:
def loop():
print('thread %s is running...' % threading.current_thread().name)
n = 0
while n < 5:
n = n + 1
print('thread %s >>> %s' % (threading.current_thread().name, n))
time.sleep(1)
print('thread %s ended.' % threading.current_thread().name)
print('thread %s is running...' % threading.current_thread().name)
t = threading.Thread(target=loop, name='LoopThread')
t.start()
t.join() # 等待t结束:
print('thread %s ended.' % threading.current_thread().name)
thread MainThread is running...
thread LoopThread is running...
thread LoopThread >>> 1
thread LoopThread >>> 2
thread LoopThread >>> 3
thread LoopThread >>> 4
thread LoopThread >>> 5
thread LoopThread ended.
thread MainThread ended.
由于任何进程默认就会启动一个线程,我们把该线程称为主线程MainThread,主线程又可以启动新的线程,Python的threading模块有个current_thread()函数,它永远返回当前线程的实例。主线程实例的名字叫MainThread,子线程的名字在创建时指定,我们用LoopThread命名子线程。名字仅仅在打印时用来显示,完全没有其他意义,如果不起名字Python就自动给线程命名为Thread-1,Thread-2……
Lock
多线程和多进程最大的不同在于,多进程中,同一个变量,各自有一份拷贝存在于每个进程中,互不影响,而多线程中,所有全局变量都由所有线程共享,所以,任何一个变量都可以被任何一个线程修改,因此,线程之间共享数据最大的危险在于多个线程同时改一个变量,把内容给改乱了。
先存后取,理论上结果应该为0,但是,由于线程的调度是由操作系统决定的,当t1、t2交替执行时,只要循环次数足够多,balance的结果就不一定是0了

所以我们就需要对由于同步而可能出现的操作进行**上锁操作**。创建一个锁就是通过==threading.Lock()==来实现
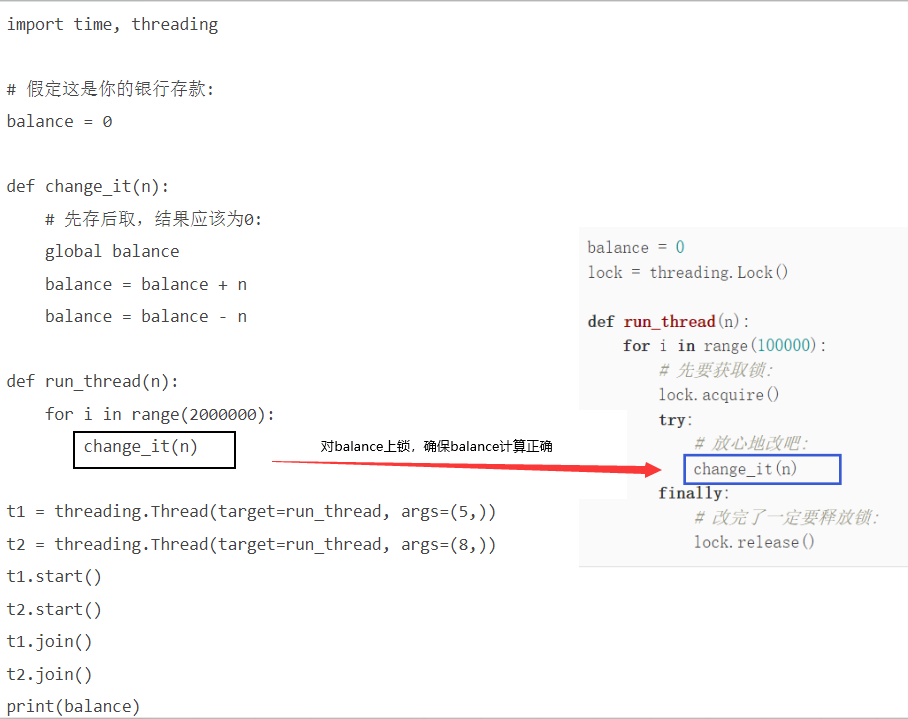
获得锁的线程用完后一定要释放锁,否则那些苦苦等待锁的线程将永远等待下去,成为死线程。所以我们用try...finally来确保锁一定会被释放。
锁的好处就是确保了某段关键代码只能由一个线程从头到尾完整地执行,坏处当然也很多,首先是阻止了多线程并发执行,包含锁的某段代码实际上只能以单线程模式执行,效率就大大地下降了。其次,由于可以存在多个锁,不同的线程持有不同的锁,并试图获取对方持有的锁时,可能会造成死锁,导致多个线程全部挂起,既不能执行,也无法结束,只能靠操作系统强制终止。
多核CPU
启动与CPU核心数量相同的N个线程,在4核CPU上可以监控到CPU占用率仅有102%,也就是仅使用了一核。
但是用C、C++或Java来改写相同的死循环,直接可以把全部核心跑满,4核就跑到400%,8核就跑到800%,为什么Python不行呢?
因为Python的线程虽然是真正的线程,但解释器执行代码时,有一个GIL锁:Global Interpreter Lock,任何Python线程执行前,必须先获得GIL锁,然后,每执行100条字节码,解释器就自动释放GIL锁,让别的线程有机会执行。这个GIL全局锁实际上把所有线程的执行代码都给上了锁,所以,多线程在Python中只能交替执行,即使100个线程跑在100核CPU上,也只能用到1个核。
GIL是Python解释器设计的历史遗留问题,通常我们用的解释器是官方实现的CPython,要真正利用多核,除非重写一个不带GIL的解释器。
所以,在Python中,可以使用多线程,但不要指望能有效利用多核。如果一定要通过多线程利用多核,那只能通过C扩展来实现,不过这样就失去了Python简单易用的特点。
不过,也不用过于担心,Python虽然不能利用多线程实现多核任务,但可以通过多进程实现多核任务。多个Python进程有各自独立的GIL锁,互不影响。
ThreadLocal
一个
ThreadLocal变量虽然是全局变量,但每个线程都只能读写自己线程的独立副本,互不干扰。ThreadLocal解决了参数在一个线程中各个函数之间互相传递的问题。ThreadLocal vs 局部变量
局部变量的作用域是在函数体内,同一线程下的多个函数使用需要对局部变量进行传参。
LocalThread的作用是在同一进程中的所有线程可以使用各自该变量的副本,同时单独线程内的各函数对独属于本线程的变量副本实现共享,各函数间不需要传参即可使用。【同一进程内互相独立、进程内的不同线程之间共享】
在多线程环境下,每个线程都有自己的数据。一个线程使用自己的局部变量比使用全局变量好,因为==局部变量只有线程自己能看见,不会影响其他线程==,而全局变量的修改必须加锁。
但是局部变量也有问题,就是在函数调用的时候,传递起来很麻烦:
def process_student(name):
std = Student(name)
# std是局部变量,但是每个函数都要用它,因此必须传进去:
do_task_1(std)
do_task_2(std)
def do_task_1(std):
do_subtask_1(std)
do_subtask_2(std)
def do_task_2(std):
do_subtask_2(std)
do_subtask_2(std)
每个函数一层一层调用都这么传参数那还得了?用全局变量?也不行,因为每个线程处理不同的Student对象,不能共享。
利用ThreadLocal
import threading
# 创建全局ThreadLocal对象:
local_school = threading.local()
def process_student():
# 获取当前线程关联的student:
std = local_school.student
print('Hello, %s (in %s)' % (std, threading.current_thread().name))
def process_thread(name):
# 绑定ThreadLocal的student:
local_school.student = name # 可以理解为全局变量local_school是一个dict
process_student()
t1 = threading.Thread(target= process_thread, args=('Alice',), name='Thread-A')
t2 = threading.Thread(target= process_thread, args=('Bob',), name='Thread-B')
t1.start()
t2.start()
t1.join()
t2.join()
执行结果:
Hello, Alice (in Thread-A)
Hello, Bob (in Thread-B)
全局变量local_school就是一个ThreadLocal对象,每个Thread对它都可以读写student属性,但互不影响。你可以把local_school看成全局变量,但每个属性如local_school.student都是线程的局部变量,可以任意读写而互不干扰,也不用管理锁的问题,ThreadLocal内部会处理。
可以理解为全局变量local_school是一个dict,不但可以用local_school.student,还可以绑定其他变量,如local_school.teacher等等。
ThreadLocal最常用的地方就是为每个线程绑定一个数据库连接,HTTP请求,用户身份信息等,这样一个线程的所有调用到的处理函数都可以非常方便地访问这些资源。
进程 vs. 线程
两种方式的优缺点
首先,要实现多任务,通常我们会设计Master-Worker模式,Master负责分配任务,Worker负责执行任务,因此,多任务环境下,通常是一个Master,多个Worker。
如果用多进程实现Master-Worker,主进程就是Master,其他进程就是Worker。
如果用多线程实现Master-Worker,主线程就是Master,其他线程就是Worker。
| 优点 | 缺点 | |
|---|---|---|
| 多进程模式 | 最大的优点就是稳定性高,因为一个子进程崩溃了,不会影响主进程和其他子进程。(当然主进程挂了所有进程就全挂了,但是Master进程只负责分配任务,挂掉的概率低)著名的Apache最早就是采用多进程模式 | 创建进程的代价大,在Unix/Linux系统下,用fork调用还行,在Windows下创建进程开销巨大。另外,操作系统能同时运行的进程数也是有限的,在内存和CPU的限制下,如果有几千个进程同时运行,操作系统连调度都会成问题。 |
| 多线程模式 | 通常比多进程快一点,但是也快不到哪去 | 致命的缺点就是任何一个线程挂掉都可能直接造成整个进程崩溃,因为所有线程共享进程的内存。在Windows上,如果一个线程执行的代码出了问题,你经常可以看到这样的提示:“该程序执行了非法操作,即将关闭”,其实往往是某个线程出了问题,但是操作系统会强制结束整个进程。 |
线程切换
无论是多进程还是多线程,只要数量一多,效率肯定上不去
切换作业是有代价的
操作系统在切换进程或者线程时也是一样的,它需要先保存当前执行的现场环境(CPU寄存器状态、内存页等),然后,把新任务的执行环境准备好(恢复上次的寄存器状态,切换内存页等),才能开始执行。这个切换过程虽然很快,但是也需要耗费时间。如果有几千个任务同时进行,操作系统可能就主要忙着切换任务,根本没有多少时间去执行任务了,这种情况最常见的就是硬盘狂响,点窗口无反应,系统处于假死状态。
计算密集型 vs. IO密集型
是否采用多任务的第二个考虑是任务的类型。我们可以把任务分为计算密集型和IO密集型。
| 特点 | 缺点 | 补充 | ||
|---|---|---|---|---|
| 计算密集型任务 | 要进行大量的计算,消耗CPU资源,比如计算圆周率、对视频进行高清解码等等,全靠CPU的运算能力 | 虽然也可以用多任务完成,但是任务越多,花在任务切换的时间就越多,CPU执行任务的效率就越低 | 所以,要最高效地利用CPU,计算密集型任务同时进行的数量应当等于CPU的核心数 | 对于计算密集型任务,最好用C语言编写 |
| IO密集型 | 涉及到网络、磁盘IO的任务都是IO密集型任务,这类任务的特点是CPU消耗很少,任务的大部分时间都在等待IO操作完成(因为IO的速度远远低于CPU和内存的速度) | 任务执行期间,99%的时间都花在IO上,花在CPU上的时间很少 | 对于IO密集型任务,任务越多,CPU效率越高,但也有一个限度 | 对于IO密集型任务,最合适的语言就是开发效率最高(代码量最少)的语言,脚本语言是首选,C语言最差。 |
异步IO
考虑到CPU和IO之间巨大的速度差异,一个任务在执行的过程中大部分时间都在等待IO操作,单进程单线程模型会导致别的任务无法并行执行,因此,我们才需要多进程模型或者多线程模型来支持多任务并发执行。
现代操作系统对IO操作已经做了巨大的改进,最大的特点就是支持异步IO。如果充分利用操作系统提供的异步IO支持,就可以用单进程单线程模型来执行多任务,这种全新的模型称为事件驱动模型,Nginx就是支持异步IO的Web服务器,它在单核CPU上采用单进程模型就可以高效地支持多任务。在多核CPU上,可以运行多个进程(数量与CPU核心数相同),充分利用多核CPU。由于系统总的进程数量十分有限,因此操作系统调度非常高效。用异步IO编程模型来实现多任务是一个主要的趋势。
对应到Python语言,单线程的异步编程模型称为协程,有了协程的支持,就可以基于事件驱动编写高效的多任务程序。我们会在后面讨论如何编写协程。
分布式进程
在Thread和Process中,应当优选Process,因为Process更稳定,而且,Process可以分布到多台机器上,而Thread最多只能分布到同一台机器的多个CPU上。
Python的==multiprocessing模块不但支持多进程,其中**managers子模块**还支持把多进程分布到多台机器上==。一个服务进程可以作为调度者,将任务分布到其他多个进程中,依靠网络通信。由于managers模块封装很好,不必了解网络通信的细节,就可以很容易地编写分布式多进程程序。
参考:
https://blog.csdn.net/u011318077/article/details/88094583